
The first results when searching for “Artificial Intelligence in video games” in Google speak for themselves: Artificial Intelligence (AI) in video games is often unsatisfactory. As a gamer, it is moreover frequent to be confronted with situations that lose credibility because of the AI behavior. Is this a real problem? Why does AI seem to stagnate in video games while the rest (graphics, complexity, gameplay…..) is continuously improving? While more and more IAs are able to compete with humans on board games (chess, Go) but also more recently on strategy (Dota 2), why do they seem to tirelessly get stuck in the background or repeat the same tirades when we play? This is what we will try to study in this complete dossier.
State of the art and history
Artificial intelligence and board games such as chess or Go have always been linked since the emergence of the discipline. Indeed, they provide a fertile ground to evaluate the different AI methods and algorithms developed. When the first video games appeared, AI research was in full swing. It is therefore logical that interest has been focused on this new medium. However and for a long time, research has mainly led to the improvement of video games and not vice versa.

The main goal of AI in a video game is to make the world portrayed by the game as coherent and humane as possible in order to enhance the player’s enjoyment and immersion. This goal of recreating a world as close to reality can be achieved through many different approaches such as improving the behavior of non-player characters (NPCs) or generating content automatically. Like board games, early video games often featured a confrontation between two players (such as Pong in 1972). Since two players were playing against each other, no AI was required in this type of game. However, games quickly became more complex and many elements began to exhibit behaviors independent of the player’s actions making the game more interactive, such as ghosts in Pac Man.
So it quickly becomes necessary to implement AI in video games to be able to generate such behaviors. Since then, AI and video games are irremediably linked, as AI has become more and more important in game systems.
Now, whatever the type of video games (racing games, strategy games, role-playing games, platform games, etc …), there is a good chance that many elements of the game are managed by AI algorithms. However, this strong overlap between AI and game system has not always been smooth and, even today, some integrations are deficient.
The links between AI and video games
At the beginning of the field, there was for a long time a gap between classical AI research and AI actually implemented by developers in video games. Indeed, there were major differences between the two in the knowledge, the problems encountered but also the ways to solve these problems. The main reason behind these differences probably comes from the fact that these two approaches to AI do not really have the same objectives.
Classical AI research generally aspires to improve or create new algorithms to advance the state of the art. On the other hand, the development of an AI in a video game aims to create a coherent system that integrates as well as possible into the game design in order to be fun for the player. Thus, a high-performance AI that is not well integrated into the gameplay may serve the game more than it will improve it.
Developing an AI for a video game therefore often requires to find engineering solutions to problems that are little or not at all addressed by classical AI research. For example, an AI algorithm in a game is highly constrained in terms of computing power, memory and execution time. Indeed, the game must run through a console or an “ordinary” computer and it must not be slowed down by AI. This is why some state of the art resource-intensive AI solutions could only be implemented in video games several years after their use in traditional AI.
Possible solutions to solve a given problem are also a distinction between the two fields. For example, it is often possible to get around a difficult AI problem by slightly modifying the game design. Moreover, in a video game, an AI can afford to cheat (by having access to information it is not supposed to have, or by having more possibilities than the player for example) in order to compensate for its lack of performance. Cheating an AI in itself is not a problem as long as it improves the player experience. However, in general, it is difficult to disguise the fact that an AI cheats and this can lead to frustration for the player.

It can be noted that most of the major video game concepts (racing games, platform games, strategy games, shooting games, etc…) were created around the 80s and 90s. At that time, the development of a complex AI in a game was something difficult to achieve given the existing resources and methods. Game designers of the time therefore often had to deal with the lack of AI by making appropriate choices of Game Design. Some games were even thought to not need AI. These basic designs have been inherited by the different generations of video games, many of which remain fairly faithful to the genre’s working guns. This may also explain why AI systems in video games are generally quite basic when compared to traditional research approaches.
Thus, the methods that we will present may surprise by their relative simplicity. Indeed, when we hear about AI today, it refers to Deep Learning and thus to very complex and abstract neural networks. However, Deep Learning is only a sub-domain of AI, and symbolic methods have been the commonly used approaches for a long time. These approaches are now referred to as GOFAI (“Good Old-Fashioned Artificial Intelligence” or “bonne vieille AI démodée” in French). As its nickname indicates, symbolic AI is clearly no longer the most popular approach, but it can nevertheless solve many problems, especially in the context of video games.
AI for video games
The main criterion of success of an AI in a classic game is probably its level of integration and nesting in the game design. For example, NPCs with unjustifiable behavior can break the intended game experience and thus the player’s immersion.

One of the most classic examples in old games is when Nonplayer Characters (NPCs) get stuck in the background. Conversely, an AI that fully participates in the game experience will necessarily have a positive impact on the player’s experience, partly because players are more or less used to the sometimes incoherent behavior of AI.
Depending on the type of game, an AI can have a wide variety of tasks to solve. So we will not look at all the possible uses of an AI in a game but rather the main ones. These will include the management of the behavior of NPCs (allies or enemies) in shooting games or role-playing games, as well as the higher level management of an agent who must play a strategy game.
NPC's control
There are many approaches to developing realistic behaviors in a video game. However, realism alone is not enough to make a game fun. Indeed, it should not be forgotten that the goal of an enemy in a game is generally to be eliminated by the player. A game with overly realistic opponents will not necessarily be fun to play. For example, NPCs who spend their time running away may annoy the player more than anything else. So there is a compromise to be found in the behavior of NPCs that is not necessarily easy to throw away.
In this part, we will take a look at the main solutions to try to solve this problem. But first, let’s review some important notions.
Agents
Probably the first notion when we talk about Artificial Intelligence for video games, an agent is an entity that can obtain information about its environment and make decisions based on this information in order to achieve an objective. In a video game, an agent often represents an NPC, but it can also represent a more complete system such as an opponent in a strategy game. Therefore, there can be several levels of agents communicating with each other in the same game.
States
A state is a unique configuration of the environment in which an agent is located. The state can change when an agent (or the player) performs an action. For an agent, the set of possible states is called the state space. This is an important notion since the basic idea of most AI methods is to browse or explore the state space to find the best way to act according to the current situation. The characteristics of the state space thus impact the nature of the AI methods that can be used.
For example, if we consider an agent that defines the behavior of an NPC, the state space can be defined in a simple way: it is the set of situations in which the NPC can find itself. You can set up a state where the NPC does not see the player, a state where the NPC sees the player, a state when the player shoots at the NPC and a state when the NPC is injured. By considering all possible situations for the NPC, we can determine the actions that the NPC can take and the consequences of these actions in terms of changing the state (the space of states is easily browsed). We can therefore fully define the agent’s behavior and choose the most relevant actions at each moment according to what is happening.
Conversely, in the case of an agent playing a game like chess, the state space will be all the possible configurations of the pieces on the game board. This represents an extremely large number of situations (10^47 states for chess). Under these conditions, it is no longer possible to explore all the possibilities. Consequently, we can no longer determine the consequences of the agent’s actions and thus judge the relevance of his actions. One is therefore forced to forget about manual approaches and turn to other more complex methods (which will be discussed later).
Pathfinding
Before being able to model the behavior of an NPC by exploring the state space, it is necessary to define how the NPC can interact with its environment and, in particular, how it can move around in the game world. Pathfinding, which is the act of finding the shortest path between point A and point B, is therefore often one of the building blocks of a complex AI system. If this brick fails, the whole system will suffer. Indeed, NPCs with a faulty pathfinding may get stuck in the scenery and thus negatively impact the immersion of the player.
The most used algorithm for pathfinding is the A* algorithm. It is a faster version of an older algorithm, the Dijkstra algorithm. Both are so-called graph pathfinding algorithms. To use these algorithms in a video game, the playing field (which takes into account possible obstacles and hidden parts) is modeled on a 2-dimensional grid (a grid is a form of graph). The algorithm will run in this 2D grid.

Dijkstra’s principle is relatively simple, he will go through each grid cell in order according to its distance from the starting cell until he finds the destination cell.
We can see with the diagram above that the algorithm has gone through all the blue boxes before finding the purple destination box. This algorithm will always find the best path but it is slow because it goes through a large number of boxes.
Where Dijkstra always finds the optimal solution, A* may only find an approximate solution. However, he will do it much faster, which is a critical point in a video game. In addition to having the distance information between each square with the starting square, the algorithm calculates approximately the general direction in which he has to go to get closer to the destination. It will then try to run through the graph, always getting closer to the goal, which makes it possible to find a solution much faster.

In more complex cases where the algorithm encounters an obstacle, it will start from the beginning to find another path that gets closer to the destination but avoids the obstacle.
For more recent 3D games, the world is not represented by a grid but by a 3D equivalent called a navigation mesh. A navigation mesh is a simplification of the world that considers only the zones in which it is possible to move in order to facilitate the work of the pathfinding algorithm. The principle of pathfinding remains the same.
These graph pathfinding algorithms may seem simple and one may wonder if they are really AI. It is important to know that a good part of AI can finally be reduced to search algorithms. This feeling that a problem solved by AI was finally not so complicated is called the AI effect.

But when it comes to pathfinding, it’s not such a simple problem, and researchers are still interested in it. For example, in 2012, an alternative to the A* algorithm was developed: the Jump Point Search (JPS) method. It allows, when searching under certain conditions, to skip several squares at once and thus save time compared to A*, which can only search for its path square by square.
Pathfinding implementations in video games today are often variations of A* or JPS, adapted to the specific problems of each game.
Pathfinding is an important component of an NPC’s behavioral system. There are others such as line of sight management (NPCs must not see behind their backs or through walls) or interactions with the environment that are necessary before consistent behavior can be implemented. But since they are generally not managed by AI, we won’t spend more time on them. However, we must not forget that the final system requires all these bricks to work. Once our NPC is able to move and interact, we can develop its behavior.

Ad hoc behavior authoring
Ad-hoc behavior authoring is probably the most common class of method to implement AI in a video game. The very term AI in video games still refers mainly to this approach. Ad Hoc methods are expert systems, i.e. systems where you have to manually define a set of rules that will be used to define the AI behavior. They are therefore manual methods for traversing the state space. Their application is therefore limited to agents confronted with a rather limited number of possible situations, which is generally the case for NPCs. Unlike search algorithms like A*, ad-hoc methods may not really be defined as classical AI, but they are considered as such by the video game industry since its beginning.
Finite state machine
A finite automaton allows to manually define the objectives and stimuli of an agent in order to dictate its behavior. For each objective, one or more states are defined and each state dictates one or more actions for the NPC. Depending on external events or stimuli, the NPC’s objective can change and therefore the automaton can transition from one state to another.
A finite automaton is therefore simply a means of representing the space of an agent’s states as well as all the transitions between its different states. If the states and transitions are well defined, the agent will behave appropriately in all situations. Finite automata are usually represented in the form of a flow diagram as shown in the example below.
The main advantage of finite automata is that they allow you to model a relevant behavior quite simply and quickly since you only need to manually define the rules that define the different states and transitions. They are also practical since they allow you to see visually how an NPC can behave.
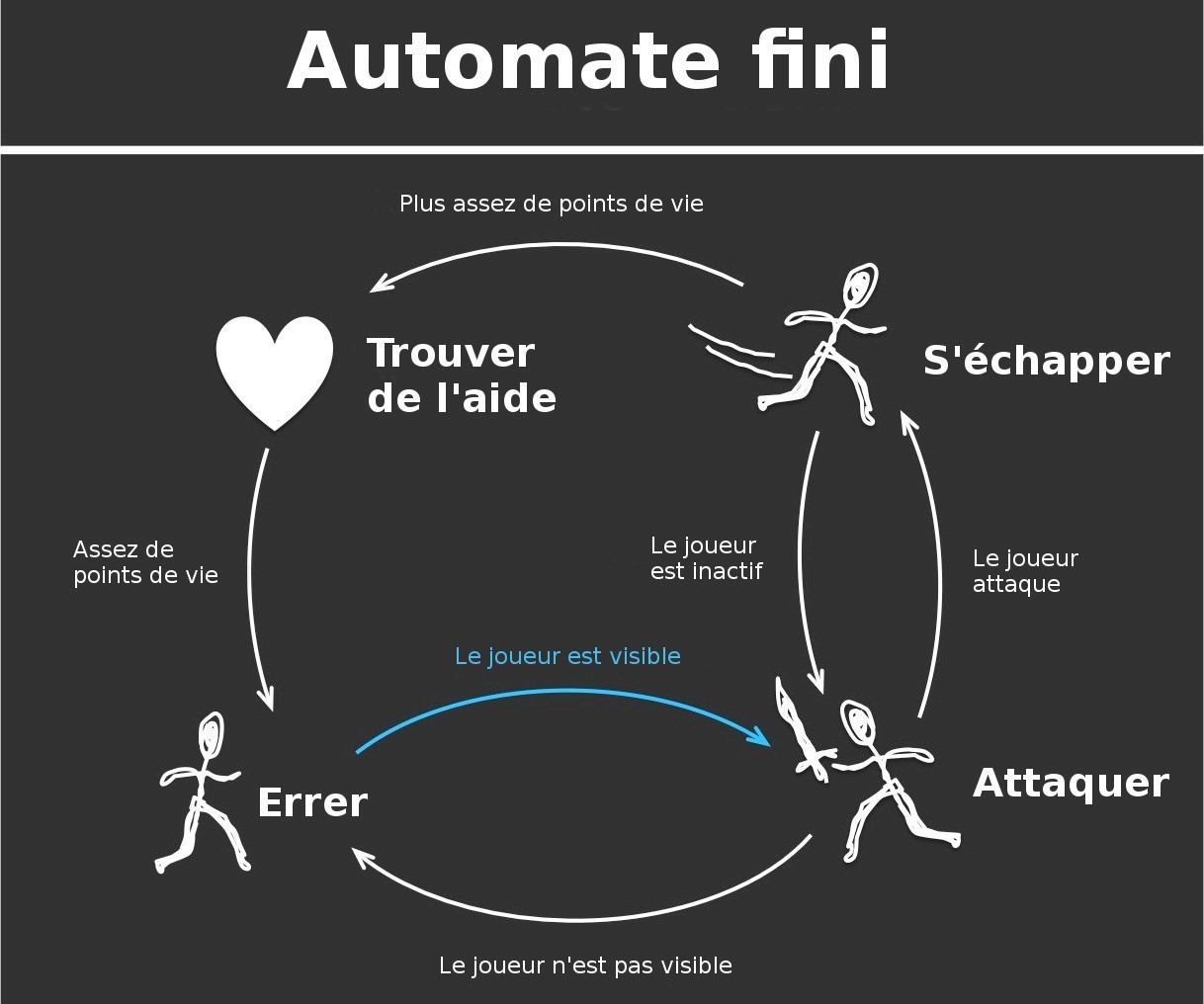
However, a finite automaton has no adaptability, since once the automaton is defined and implemented, the behavior of the AI will not be able to evolve or adapt. For the same objective, the NPC will always perform the same actions. It will therefore often present a relatively simple and predictable behavior (although it is always possible to present unpredictability by adding some randomness in transitions for example).
A finite automaton allows to manually define the objectives and stimuli of an agent in order to dictate its behavior. For each objective, one or more states are defined and each state dictates one or more actions for the NPC. Depending on external events or stimuli, the NPC’s objective can change and therefore the automaton can transition from one state to another.
A finite automaton is therefore simply a means of representing the space of an agent’s states as well as all the transitions between its different states. If the states and transitions are well defined, the agent will behave appropriately in all situations. Finite automata are usually represented in the form of a flow diagram as shown in the example below.
The main advantage of finite automata is that they allow to model a relevant behavior quite simply and quickly since it is enough to manually define the rules that define the different states and transitions. They are also practical since they allow you to see visually how an NPC can behave.
Because of their simple design, finite automata allow to complete, modify or debug an AI system relatively easily. It is thus possible to work in an iterative form in order to quickly check the implemented behaviors.
However, when you want to implement a more complex behavior with a finite automaton, it quickly becomes complicated. A large number of states and transitions have to be defined manually and the size of the PLC can quickly impact the ease of debugging and modification.
An evolution of finite automata tries to address this problem: hierarchical finite automata. This approach groups sets of similar states in order to limit the number of transitions between possible states. The objective is to keep the complexity of what we want to model, while simplifying the work of creating and maintaining the model by structuring the behaviors.
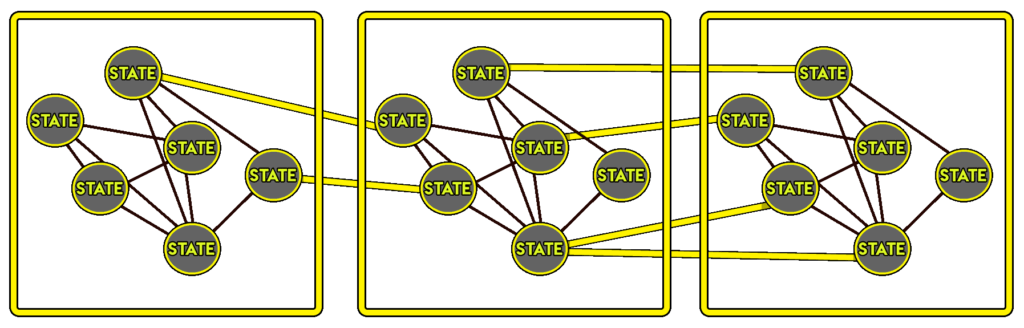
Finite automata were the most popular method for building simple behaviors in video games until the mid-2000s. They are still used on some recent games such as the Batman: Arkham or DOOM series (which uses hierarchical finite automata to model the behavior of enemies). However, they are no longer the most frequently used algorithms on the market.
Behavior trees
Behavior trees are quite similar to finite automata, with the difference that they are based directly on actions (and not states), and that they represent the different transitions between actions in the form of a tree. The tree-like representation structure makes it possible to implement complex behaviors much more simply. It is also simpler to maintain, because one gets a better idea of the agent’s possibilities of action by browsing the tree than with a flow chart.
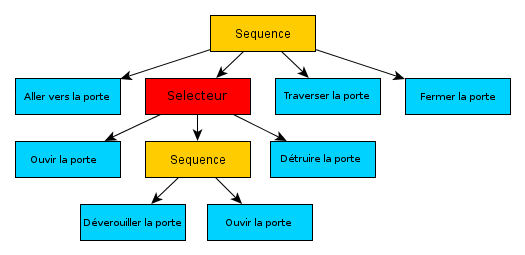
A behavior tree consists of different types of nodes :
- Leaf nodes (above in blue) which have no descendants and represent actions
- The selector nodes (in red) which have several descendants and allow to choose the most relevant one according to the context.
- Sequence nodes (in yellow) which execute all their descendant nodes in order and thus allow to make sequences of actions
A behavior tree is executed from top to bottom and from left to right Starting from the root node (the very first node) to the rightmost leaf. Once you get to the leaf and the action is executed, you return to the root node and scroll to the next leaf.
Thus, in the tree above:
The NPC will go to the door, then depending on the type of door and the items he has on him he will either open the door, unlock it and then open it, or destroy it. He will then go through the door and close it again. We can see that this tree allows you to define different sequences of actions that allow you to reach the same objective: to pass on the other side of a door.
It is of course possible to build much more complete trees that can represent all the behavioral information of the NPC. For example, below is a behavior tree that allows you to go through a door or a window depending on the context.
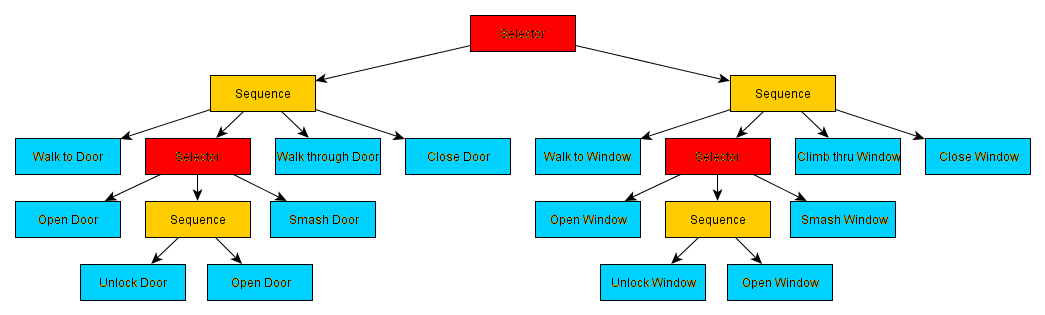
Behavior trees have globally the same limitations as finite automata. Mainly, they describe a fixed and predictable behavior since all rules and actions are manually defined upstream. However, their architecture in the form of a tree facilitates development and limits errors, thus making it possible to create more complex behaviors.
Behavior trees were first used with Halo 2 in 2004. They have since been used in a number of successful licenses such as Bioshock in 2007 or Spore in 2008 for example.
Utility based AI
With this approach, rather than transitioning from one state to another according to external events, an agent will constantly evaluate the different possible actions he can perform at a given moment and choose the action that has the highest utility for him in the present conditions. For each action a utility curve is defined upstream according to the conditions. For example, a utility curve can be defined for shooting the player according to the distance from the player. The closer the player is, the more useful it seems to be to shoot at him to avoid being eliminated. By choosing different types of curves (linear, logarithmic, exponential, etc…) for the different actions, one can prioritize which action to perform under which conditions without having to manually detail all possible cases.
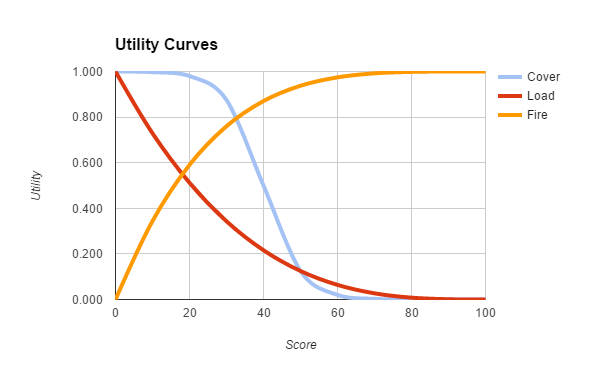
This approach therefore allows the development of complex and much more modular behaviors without having to define a very large number of states. The list of possible actions can easily be completed or modified with this type of approach, which was not the case with finite automata or behavior trees. However, it is still necessary to define all the utility curves and to set them properly to obtain the desired behaviors.
This approach, thanks to its advantages, is increasingly used in video games. Examples include Red Dead Redemption (2010) and Killzone 2 (2009).
In this first part, we have mainly reviewed the classical ad hoc methods. As we have seen, these different methods for modeling behaviors each have their advantages and disadvantages. Here is a small table summarizing the different approaches discussed so far.
A common disadvantage of all these approaches is that the behaviours defined cannot be adapted at all to the way the gambler behaves. In the second article we will therefore look at more advanced methods such as planning or Machine Learning approaches to try to correct this disadvantage.
So far, we have seen ad-hoc methods that manually manage agent actions and stimuli. These methods work well for presenting intelligent behaviors in the short term. However, to design agents that can think in the longer term, it is necessary to use other methods: planning algorithms.
Rather than having to manually define the state space and the different actions to reach a goal, planning is like searching for a solution in the state space to reach a goal.
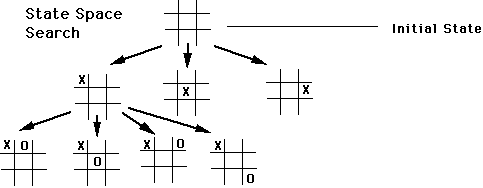
By using a planning algorithm, we will therefore search for a sequence of actions that allows us to reach a desired state.
Presented for pathfinding, the A* algorithm is not only useful for pathfinding on a grid. Indeed, it can also be used for searching in the space of states and therefore for planning. The state space is often represented in the form of a tree where the nodes are states and the branches are actions. Trees are types of graphs that are particularly suitable for searching.
Goal Oriented Action Planning
This approach, used for the first time in 2005 for the F.E.A.R. game, is based on the use of finite automata and a search by A* in the states of these automata.
In the case of a classical finite automaton, the logic that determines when and how to transition from one state to another must be specified manually, which can be problematic for automata with many states as we have seen previously. With the GOAP approach, this logic is determined by the planning system rather than manually. This allows the agent to make his own decisions to switch from one state to another.
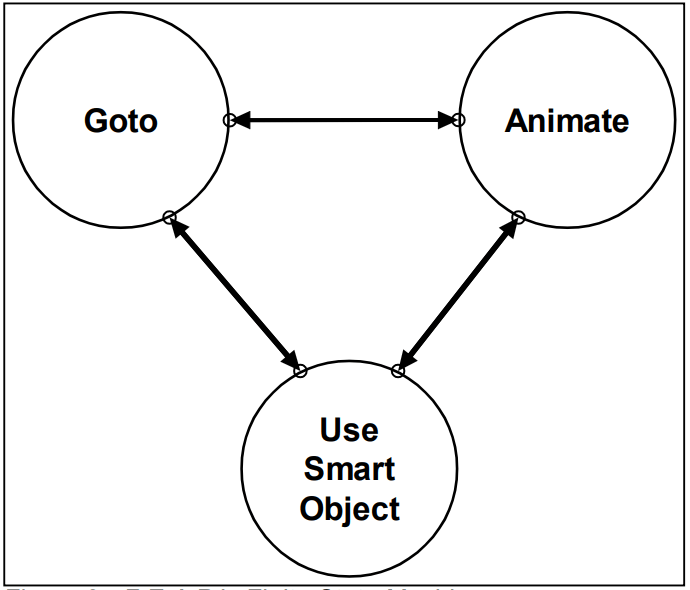
With this approach, the state space is represented by a finite automaton. Contrary to the classical approach where we define an automaton with many states that all correspond to a specific action, we will define a small automaton with only a few abstract states. Each abstract state therefore corresponds to large categories of actions that will be context-dependent. For example, the finite automata of the NPCs in F.E.A.R. have only 3 very abstract states. One of the states is used to manage displacements and the two others are used to manage animations. The complex behavior of NPCs is therefore simply a succession of movements and animations.
The interest of the GOAP approach is that, depending on the context in which an objective is defined, several different action plans can be found to solve the same problem. This action plan is constructed through the states of the finite automaton that dictate the movements and animations of the NPC.
Whatever happens, the plan (the sequence of actions) found by the A* algorithm will always be a reflection of the agent’s objective at the present moment. If the NPCs’ objectives are always well defined, they will present a coherent, complex and varied, sometimes even surprising behavior. Indeed, these plans can be more “long term” than those defined manually by a simple finite automaton or a behavior tree. This is why enemies can be seen moving around the player in F.E.A.R for example.
This approach gives very credible behavior in F.E.A.R., but it is not necessarily suitable for all types of games. Indeed, for very open and complex games where the number of possible actions is large, the method may have limitations. In F.E.A.R, the shots found by the search algorithm remain relatively short (usually sequences do not have more than 4 actions), but as the actions and states are defined in an abstract and high level way, a sequence of 4 actions is sufficient to change pieces, move around the player, move objects, take cover etc… If a game needs to find shots with much longer sequences of actions, it is often the case that the algorithm is too heavy in terms of resources and that the shots found diverge too much from the behavior targeted by the designers. Indeed, this kind of approach brings less control over the final result than an ad hoc behavior tree for example.
This is the problem encountered by the developers of the game Transformers: War for Cybertron in 2010. So they decided to change their approach and turned to another planning method: the Hierarchical Task Network planning (HTN) approach. For those who are interested, their issues and the implementation of the approach are explained in this article from AI and Games.
This approach in F.E.A.R was at the time of its release a small revolution in the world of AI in video games and it has since been modified and improved as needed (with the HTN approach for example). For example, this approach can be found in S.T.A.L.K.E.R, Just Cause 2, Tomb Raider, Middle Earth: Shadow of Mordor or Deus Ex: Human Revolution.
The case of strategy games
It is obvious that, depending on the type of game, AI does not have at all the same vocation nor the same possibilities. Most of the methods presented above are used to implement agent behaviors in a world in which the player evolves. Whether it’s a shooting game, or a role-playing game, NPCs are generally characters similar to the player in the sense that they only have control over their own actions. Moreover, a planned behavior in the short or medium term (4 actions for F.E.A.R.) is often sufficient to present a satisfactory behavior.
There are, however, other types of games (especially strategy games) where an agent playing the game must control several units at the same time and implement strategies over the very long term in order to get rid of his opponents. This type of game can be similar to board games such as chess or Go. At any given moment, an agent can perform a very large number of possible actions. The possible actions, relevant or not, depend on the current state of the game (which is derived from all the actions previously taken by the player and his opponent).

In this kind of game, the state space corresponds to the set of possible configurations in which the game can be found. The more complex the game is, the bigger this space is and the more difficult it is for an AI to play it.
Indeed, to be able to play this kind of game, an AI must go through the state space to estimate the relevance of the various possible actions. For a game like chess it is still possible to search in the state space (size 10^47) but for more complicated games like Go it becomes impossible in terms of computing power. Go has about 10^170 states. In comparison, the real-time strategy game Starcraft II has a state space estimated at 10^1685. To give an idea, it is estimated that there are about 10^80 protons in the observable universe.
For a long time AI was not able to beat the best players in board games like chess (it was only in 1997 that AI Deep Blue managed to beat Kasparov, the world chess champion). The game of Go was “solved” only in 2016 thanks, among others, to the emergence of Deep Learning. This means that research and planning methods (such as GOAP in F.E.A.R) cannot work for games like Starcraft and developers had to find other solutions.
The AI of strategy games was therefore based on more simplistic approaches where each unit presented a behavior independent of the others. If each unit is taken independently, its state space is much smaller and it becomes possible to represent it by an ad hoc method (like an automaton or a behavior tree) or to search it to find a sequence of action (in the same way as for NPCs in shooting games for example).
With this approach, it becomes possible to compute the behaviors of all units, but the AI cannot really present a global strategy, as the different units cannot coordinate with each other. So these IAs are generally unable to beat seasoned players.
It is the difficulty of the task that often led the developers of these IAs to cheat, the only solution to present any challenge to the player. It is sometimes still the case today, depending on the type of game. For example in Starcraft II (released in 2010), the highest difficulty levels for the player are managed by cheating AI.
The developers of Starcraft II play here transparency on their AI. Any player who risks himself against the highest difficulty level knows what to expect. Despite this cheating, the game’s AI remains predictable and good players manage to get rid of it without too much difficulty.
Monte Carlo Tree Search
Recently, a new method has been much talked about for this kind of problems where the space to be searched for is very large. It is the Monte Carlo Tree Search method. Used for the first time in 2006 to play Go, it quickly allowed to improve the systems of the time (which could not yet compete with an amateur player). Then more recently in 2016, it was used as one of the main building blocks of AlphaGo, the algorithm that succeeded in defeating the world Go champion.
This method can of course also be applied to video games. In particular, it was used for the game Total War: Rome II released in 2013. The games in the Total War series feature different game phases:
A turn-based strategy phase on a world map where each player has to manage his country as well as relations with the surrounding countries (diplomacy, war, espionage etc..).
A real-time battle phase on a scale rarely seen in video games (each side often has several thousand units).
The turn-by-turn phase presents a very large space of states in which it is not possible to search for sequences of actions and therefore relevant strategies. It is in this phase of the game that the MCTS method can help. As this phase is played turn by turn, it is possible to take some time to find a good solution. Here the AI system does not have to respond in a few milliseconds as is often the case.
The MCTS method makes it possible to efficiently search for solutions in a space that is impossible to cover completely. The method is based on reinforcement learning concepts, especially the exploration-exploitation dilemma. Exploitation consists in going through the branches of the tree that are thought to be the most relevant to find the best solution. Exploration, on the other hand, consists in going through new branches that we do not know or that we had previously considered irrelevant.
It may seem logical to want to do nothing but exploitation, i.e. always focus on the solutions you think are the best. However the MCTS method is used in cases where it is not possible to search for all the solutions because the tree is too large (otherwise an algorithm like minimax is used). In this case it is not possible to know if the solution we consider is really the best one. Maybe another part of the tree not browsed contains better solutions. Moreover, a branch that is irrelevant at a given moment may become so later, so if we only exploit it we risk missing interesting solutions. The MCTS method allows to find a compromise between exploration and exploitation in order to quickly find satisfactory solutions.
It may seem logical to want to do nothing but exploitation, i.e. always focus on the solutions you think are the best. However the MCTS method is used in cases where it is not possible to search for all the solutions because the tree is too large (otherwise an algorithm like minimax is used). In this case it is not possible to know if the solution we consider is really the best one. Maybe another part of the tree not browsed contains better solutions. Moreover, a branch that is irrelevant at a given moment may become so later, so if we only exploit it we risk missing interesting solutions. The MCTS method allows to find a compromise between exploration and exploitation in order to quickly find satisfactory solutions.
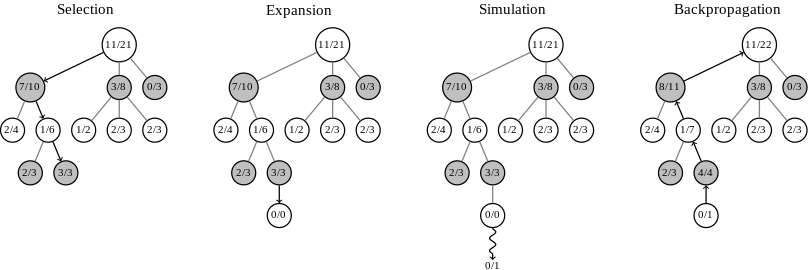
The objective of the Backpropagation step is to ensure that the nodes that seem most relevant are chosen more frequently in the next Selection steps. It is during the Selection phase that the compromise between exploration and exploitation is made. The idea of the MCTS method is to run these four simulation steps thousands of times and when making a decision, to choose the node that has given the most victories over all the simulations.
The advantage of the method is that a maximum execution time can be defined. Up to the allocated time limit, the algorithm will run simulations. Once the time has elapsed it is enough to take the node with the highest victory rate. The more time it is given, the more likely it will find good solutions since the calculated statistics will be accurate. Thus, the solution finally found by MCTS may not be the optimal solution, but it will be the best solution found in the given time. This approach allowed the agent playing in the turn-based strategy phase of Rome II Total War to present relatively advanced strategies despite the very complex state space of the game.

Funnily enough, the AI system for real-time battles is based on ad hoc methods from the Art of War by Sun Tzu (around 500 BC).
A relevant quote even for an AI system
These strategy rules can also be successfully applied in a video game. For example:
- When you surround the enemy, leave an exit door
- Do not try to block the enemy’s path on open ground.
- If you are 10 times more numerous than the enemy, surround him.
- If you outnumber the enemy 5 times, attack him head-on.
- If you are twice as many as the enemy, divide it up.
These simple rules can easily be implemented in an ad hoc system and allow the AI to present relevant behavior in many situations and thus propose realistic battles.
What about machine learning?
Not all the methods presented so far offer learning. Behaviors are governed by manually defined rules and by the way these rules are considered in relation to the environment. To get more complex AIs that can really adapt to various situations, it seems necessary to set up systems that can automatically learn to act according to the player’s behavior. The branch of automatic learning in AI is called Machine Learning.
Machine learning methods have sometimes been used to code the behavior of agents. For example, units in real-time battles in Total War games are controlled by perceptrons (the neural networks ancestors of Deep Learning). In this kind of implementation the networks are very simple (far from the huge networks of Deep Learning).
The inputs of the networks correspond to the state of the game (the situation) and the outputs correspond to the action taken. The learning of these networks is done upstream during the development of the game (sometimes even manually for the simplest networks). This kind of method is ultimately similar to ad hoc methods since the behavior of the units is fixed by the developer and does not evolve during the game.
However, there have been cases where agents could really learn during the game. For example in Black and White (released in 2000) which is known to have managed to mix different AI approaches and get a good result. The principle of the game is very much based on the interaction between the player and a creature with complex behavior.
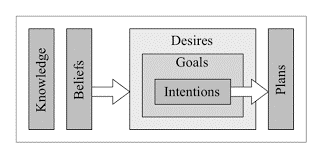
The creature’s decision-making behavior is modeled according to a belief-desire-intention (BDI) agent. The BDI approach is a model of psychology, which is here adapted for video games. This approach, as its name indicates, models, for an agent, a set of beliefs, desires and intentions that dictate his decision making.
The beliefs correspond to the state of the world as seen by the agent. These beliefs can be false if the agent does not have access to all the information. Desires, based on beliefs, represent the agent’s motivations and therefore the short and long term goals he or she will seek to achieve.
Intentions are the action plans that the agent has decided to carry out to achieve his or her objectives. In Black and White, the creature’s beliefs are modeled by decision trees and desires are modeled by perceptrons. For each desire, the creature bases itself on its most relevant beliefs.
The BDI model represents the creature’s decision-making system, but at the beginning of the game, she is like a child whose beliefs and desires are not well defined. During play, the creature learns how to behave through its interactions with the gambler. The gambler may reward or punish the creature based on its actions. Through a reinforcement learning algorithm the creature will discover which actions result in a reward and which result in a punishment. It will then model its behavior to be consistent with what the player asks it to do.
The creature’s behavioral system is therefore a hybrid system based on an ad hoc AI base (the BDI model) for which each component is a self-learning algorithm. These hybrid systems are probably the best compromise to obtain complex and evolutionary behaviors but still remain within an initially defined framework.
Why do we stay on ad hoc then?
This kind of more advanced approach with machine learning is however really not the majority of implementations in video games, and most of the AI recognized as very successful recently like the companion AI in Bioshock Infinite are usually very complex and well thought out ad hoc systems to fit perfectly into the gameplay (with all the cheating that this may require, like teleporting the companion when the player can’t see him for example).
If developers keep on clinging to the classical ad hoc AI methods, it’s firstly because in the end, these methods work well (for example in F.E.A.R or Bioshock Infinite). Indeed, what the designers are trying to create is an illusion of intelligence that is credible to the player, even if the model that handles NPCs is ultimately very simple. As long as the illusion is present, the contract is fulfilled. However, setting up this type of system can in fact quickly become very complex depending on the type of game and therefore require a lot of time and development resources. The majority of AI failures in video games is probably due to a too low investment in AI development rather than to unsuitable methods.
The second important reason that forces developers to stay on systems without learning is the difficulty in predicting AI behavior in all situations. Game designers fear that an AI that learns automatically may break the player’s gaming experience by presenting an unexpected and inconsistent behavior that would take the player out of his immersion in the game world (although it can be noted that this is precisely what happens with a poorly implemented ad hoc AI system). Designers want to fully imagine the experience the player will have and this is much harder to define with an AI that learns automatically.
Another important point is that the NPC’s behavior must be a minimum predictable and present codes that are known and expected by the players. These behavior codes are inherited from the first games that defined the styles and their evolution.
For example, in infiltration games the guards usually do rounds following a specific pattern that the player has to memorize in order to pass without being seen. Implementing a more complex behavior with an AI can risk changing the classic experience of undercover games and is therefore a choice to be made with full knowledge of the facts. Another similar case is boss fighting. In many games boss fights are special phases where the boss has a predetermined behavior that must be understood by the player in order to win.

A boss that adapts too much to the player’s way of playing may surprise players formatted by their past experiences. When implementing an AI in a game, you need to be able to do it while playing with the many clichés of the medium. That’s why the most innovative approaches in terms of AI nowadays are often linked to new game concepts, as classic styles are sometimes considered too rigid to accommodate this kind of AI.
Finally, another reason to stay on ad hoc methods seems to be that this is the way it has always been done in the field, and that starting to innovate without any assurance of success in a framework as limited in terms of time and resources as the development of a video game seems to be a fairly significant risk to take. Especially for development studios whose health may depend on the success or otherwise of a single game.
Evolution of methods
As we have seen, AI methods in video games have evolved over time to become increasingly complex and sophisticated. This makes you wonder why when you play, you have the feeling that AI is stagnating and not really improving. The answer is most likely that games are getting bigger and more complicated and therefore the tasks that IAs have to solve to be consistent are getting more and more complex.

Thus, the games where AI has been a great success are often games where the domain was relatively small. For example in F.E.A.R which focuses on small-scale clashes. The more games are open, the more likely it is that the AI is caught in default. We can take the example of the AI of the bandits in the role-playing game Skyrim.
These have fairly obvious flaws that can lead to the kind of incongruous situations depicted in the image above. The problem in Skyrim is that the NPC AI must be able to handle a very large number of different situations, so there are most likely situations where it will not be suitable.
Another problem in games that are too big is that the amount of content that needs to be generated for this world to be consistent becomes very important. If you want each NPC to be unique and have a story of its own, it’s a huge amount of work. That’s why all the guards in Skyrim all took an arrow in the knee in their youth when they were adventurers.
AI can help us with this content issue through what is called procedural content generation. In the rest of this article we will therefore focus on other less frequent ways to implement AI in video games, and in particular with procedural content generation.
Procedural generation
As we have seen in previous articles, AI in video games is mainly used to implement the behaviors of non-player characters (NPCs). This approach has been so important that other issues potentially addressed by AI have long been neglected. Recently, this kind of alternative approach has started to develop more and more, the main one probably being procedural content generation.
Procedural content generation refers to methods that allow to generate content in a game with little or no human intervention. The content generated can be very varied in nature and can affect almost an entire game. Examples include: levels, terrains, game rules, textures, stories, objects, quests, weapons, music, vehicles, people,… In general, it is considered that the behavior of NPCs and the game engine do not correspond to the content itself. The most frequent use of procedural generation is probably the creation of levels and terrains.
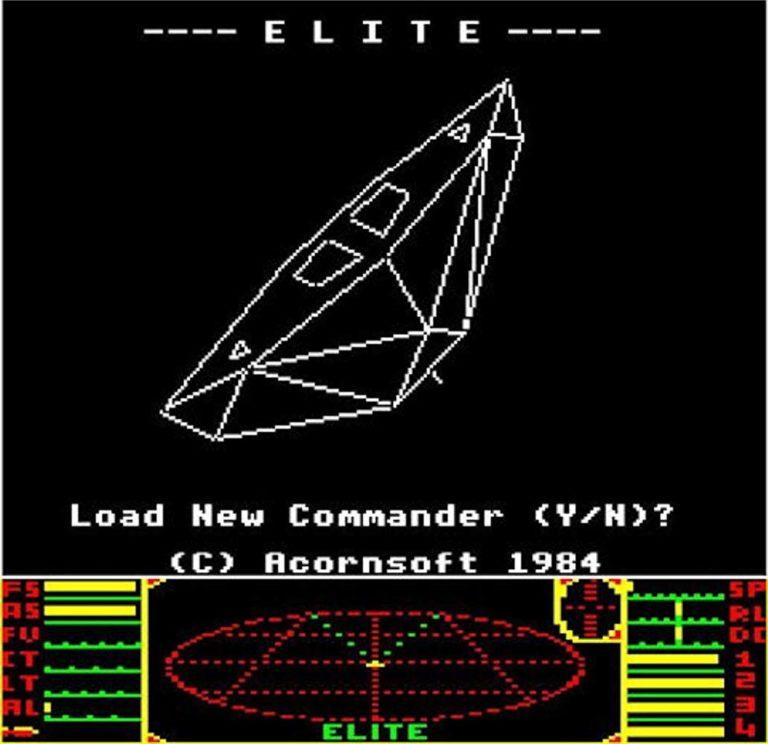
The use of procedural generation has exploded since the mid-2000s, however the field has been around for a very long time. Indeed, in 1980 the game Rogue was already using procedural generation to automatically create its levels and place objects in them. In 1984, Elite, a space commerce simulation game, generated new planetary systems (with their economy, politics and population) during the game.
Objectives
What is the interest of the procedural generation? The first games used procedural generation to reduce storage space. Indeed, by generating the game textures and levels on the fly, it is no longer necessary to store them on the cartridge or other game medium. This made it possible to go beyond the physical limits imposed by the technologies of the time and thus make potentially much larger games. For example, Elite had several hundred planetary systems requiring only a few tens of kilobytes (kb) on the machine.
Nowadays this is no longer the main reason to use procedural generation. Above all, it makes it possible to generate large quantities of content without having to design everything by hand. In the development of a game, the content creation phase can be very heavy and take a large part of the budget. Procedural generation can accelerate the creation of this content.
Anastasia Opara (SEED – Search for Extraordinary Experiences Division – at Electronic Arts) presents in this conference her vision of content generation. For her, content creation presents a phase of creativity that corresponds to the search for the idea and artistic creation, followed by a phase of manufacturing and implementation of this idea in the video game. She presents this phase as a mountain requiring special skills and a very significant investment of time to be overcome. The procedural generation of content can be an approach to try to reduce the size of this mountain and thus allow artists to focus mainly on pure creativity while abstracting from the difficulty of implementation.
In addition to facilitating the content-making phase, procedural generation can also encourage artists’ creativity by offering unexpected and interesting content. The procedural generation thus presents an aspect of collaboration between the artist and the machine. One can thus find galleries of procedurally generated artworks.
The procedural generation of content could thus promote human creation and allow the creation of new game experiences and even potentially new genres of play. One could thus imagine that games could be customized much more than what currently exists by dynamically modifying the game content according to the interactions with the player.

Finally, with a procedural generation capable of producing content in sufficient variety, quality and quantity, it seems possible to create games that never end and therefore with ultimate replayability.
However, as developers have realized (notably those of No Man’s Sky), the amount of content in a game does not necessarily make it interesting. There is therefore a vital compromise to be found between the quantity of content that is generated and its quality (interesting, varied, etc…).
For example, in the Elite game presented earlier, the designers planned to generate 282 trillion galaxies (that’s a lot). The publisher of the game convinced them to limit themselves to 8 galaxies, each composed of 256 stars. With this more measured number of stars to be created, the game’s generator was able to make each star relatively unique, which would have been impossible with the number of galaxies initially planned. Thus the game proposed a good balance between size, density and variability. With the procedural generation of content, one can quickly fall into the trap of a gigantic universe where absolutely everything looks the same. Each element will be mathematically different, but from the player’s point of view, once he has seen one star, he has seen them all.
There is therefore generally a balance to be found between the size of the world, its diversity and the developer’s time allocation. Generating the content through mathematics is the scientific part, while finding the right balance between the different elements is the artistic part.
The different approaches
There are many approaches to procedural content generation and not all of them are based on Artificial Intelligence. Often simple methods are used, such as NPCs’ behavioral design, in order to maintain control over the final rendering more easily. Indeed, the generated content must respect certain constraints in order to be well integrated into the game.
We will therefore first focus on the main classical methods of procedural generation, then we will give an overview (non-exhaustive) of the approaches based on AI.
Constructive procedural generation
Tiles-based approach
The simplest and most frequently used method is the tile-based method. The idea is simple: the game world is divided into subparts (the tiles), for example rooms in a dungeon exploration game. A large number of rooms are modeled by hand. When generating the world, the pre-modelled rooms are randomly selected to create a larger universe. If a large enough number of tiles have been defined beforehand, through the magic of combinatorics, you can obtain a world generator that will almost never produce the same result twice.
With this approach, you get a diversity of results while ensuring local consistency since each tile has been defined manually. In general, this type of approach also implements specific business rules to ensure that the result will be playable and interesting.

The simplest and most frequently used method is the tile-based method. The idea is simple: the game world is divided into subparts (the tiles), for example rooms in a dungeon exploration game. A large number of rooms are modeled by hand. When generating the world, the pre-modelled rooms are randomly selected to create a larger universe. If a large enough number of tiles have been defined beforehand, through the magic of combinatorics, you can obtain a world generator that will almost never produce the same result twice.
With this approach, you get a diversity of results while ensuring local consistency since each tile has been defined manually. In general, this type of approach also implements specific business rules to ensure that the result will be playable and interesting.

Weapons are cut into sub-parts which are interchangeable. Each weapon generated is a random draw of the different subparts. Each of these has an impact on the weapon’s statistics such as loading time, type of ammunition, accuracy, etc., so that all the generated weapons are slightly different from each other.
Fractal approaches
Fractal approaches get their name from the famous mathematical objects since they have some similar properties. Indeed, these procedural generation approaches are based on systems of successive layers at different scales, a bit like fractals. We will see two types of fractal approaches: noise-based methods and grammar-based methods.

Noise-based approaches
When observing the world from an airplane, the layout of the terrain seems to be relatively random. The idea of noise-based approaches is to rely on randomness to generate terrains that are close to those of the real world. When a sequence of values is randomly drawn, we get what is called white noise.
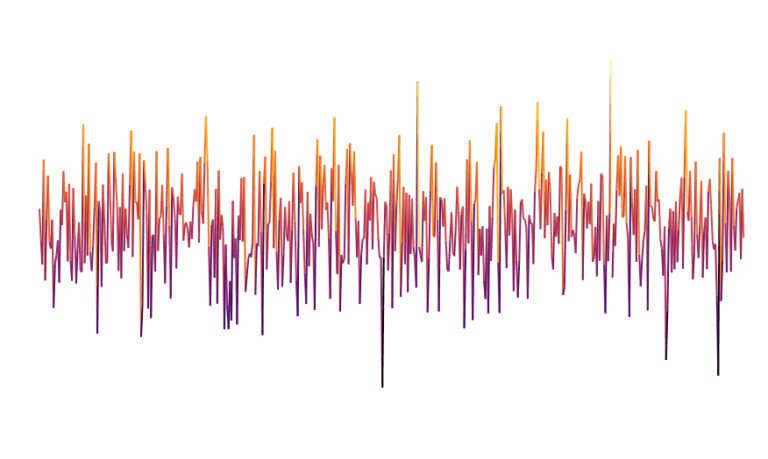
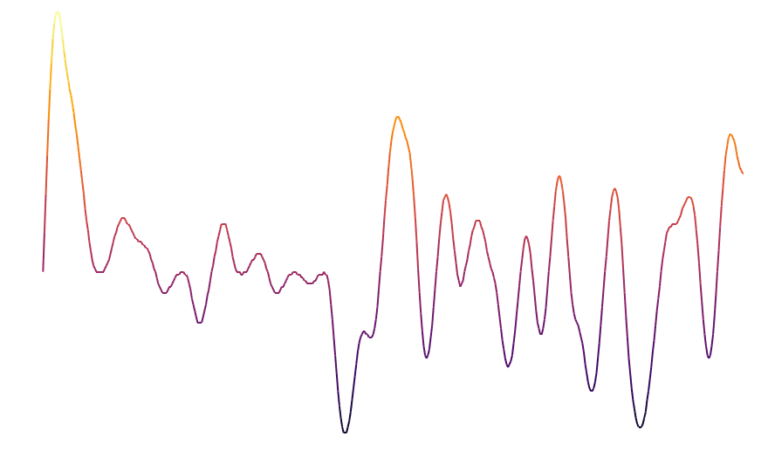
White noise is not a great help for procedural generation since it is the representation of a completely random process (which is clearly not the case in our world). However, there are other types of noise that represent randomness while maintaining a local structure. Probably the best known in the context of procedural generation is probably the Perlin noise. This noise is generated by a random process, however the nearby points are no longer independent of each other as for white noise. This makes it possible to obtain curves like the one shown here which are locally smoother.
Algorithms based on noise become interesting especially when the number of dimensions is increased. Thus, if we take a two-dimensional grid and make a print of white noise and Perlin noise, we obtain the following results. We have white noise on the left and Perlin noise on the right. Each pixel is colored according to its value.
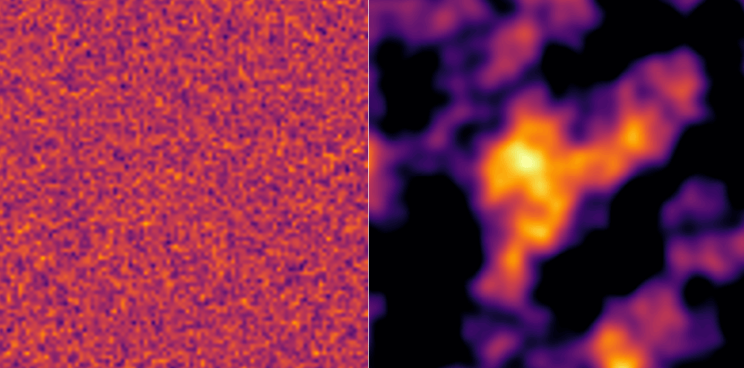
This gives a value for each pixel of the grid. We can then consider the value of this pixel as an altitude and display the grid in 3 dimensions. One thus obtains a representation of a mountainous terrain, entirely generated by Perlin noise. The problem with Perlin noise is that it will tend to generate repetitive elements of relatively similar size. We thus risk obtaining a mountainous but very empty world, without any details between the mountains.

To avoid this problem, several layers of Perlin noise are used at different scales (called octaves). Thus the first layer is used to generate the coarse-grid geography of the world and the following layers add successively finer and finer levels of detail. Thus we find again the idea of fractals.
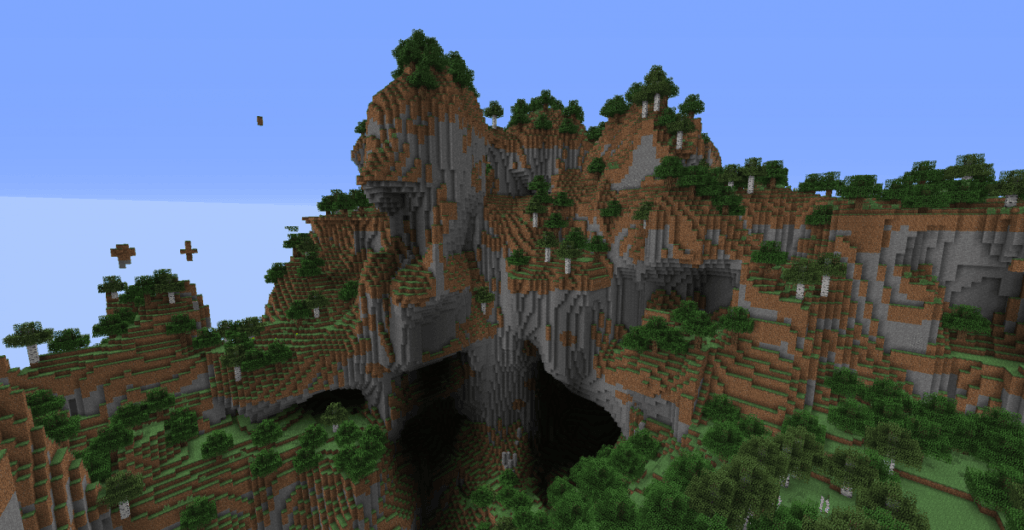
Perlin noise is probably the most used approach for procedural generation since terrain generation is a recurring need in video games. This approach is notably used by Minecraft to generate its worlds.
Many variations exist around the Perlin noise, as it often needs to be adapted to the specific needs of each game. We can mention the Simplex noise which is an improvement of the Perlin noise (proposed by the inventor of the Perlin noise – Ken Perlin – himself). In the game No man’s sky where almost the entire universe is generated procedurally, the planets are based on what the designers call “Uber noise” which is an approach based on the Perlin noise and combining many other types of noise. Their approach is supposed to give more realistic (and therefore more interesting for the player) results than those based only on Perlin noise.
Grammar-based approaches
A formal grammar can be defined as a set of rules that apply to text. The rules of grammar allow you to transform one string of characters into another. For example, the rules of grammar can be used to transform one string of characters into another:
A -> AB
B -> A
With the first rule every time there is an “A” in a string it will be transformed into an “AB” and with the second rule a “B” will be transformed into an “A”.
Formal grammars have many applications in computer science and AI, but we will focus on a particular type of grammar called L-systems. L-systems have the particularity of being grammars designed for plant generation. L-systems have recursive rules, which makes it easy to generate fractal forms. In nature many plants have fractal forms, Romanesco cabbage being one of the most striking examples.

An L-system is defined by an alphabet, a set of rules, modifications and a starting axiom (which is the character string we consider to start)
Let’s take a simple example:
A restricted alphabet : {A,B}
Two simple rules:
A → AB
B → A
The starting axiom: A
The idea is to apply several times the rules to the previously obtained result (n being the number of times the rule has been applied).
We obtain the following results:
n = 0 -> A
n = 1 -> AB
n = 2 -> ABA
n = 3 -> ABAAB
n = 4 -> ABAABABA
n = 5 -> ABAABABAAB
n = 6 -> ABAABABAABABAABABA
n = 7 -> ABAABABAABAABABAABABAABAABAABAAB
One may wonder where is the link between this string generation and the plants. The idea is to associate to each character of the alphabet a drawing action. The generated strings will therefore be a kind of drawing action.
For example we can consider an L-system with the following alphabet:
F: draw a line of a certain length (e.g. 10 pixels)
+ : turn left 30 degrees
– turn right 30 degrees
: keep track of current position and orientation
[ ] : return to the position and orientation in memory
Only one rule is defined in the grammar :
F → F[-F]F[+F][F]
The starting axiom is: F
Thus, for the different iterations, we obtain the following results. (The colors allow to make the link between the generated strings and the equivalent drawings)

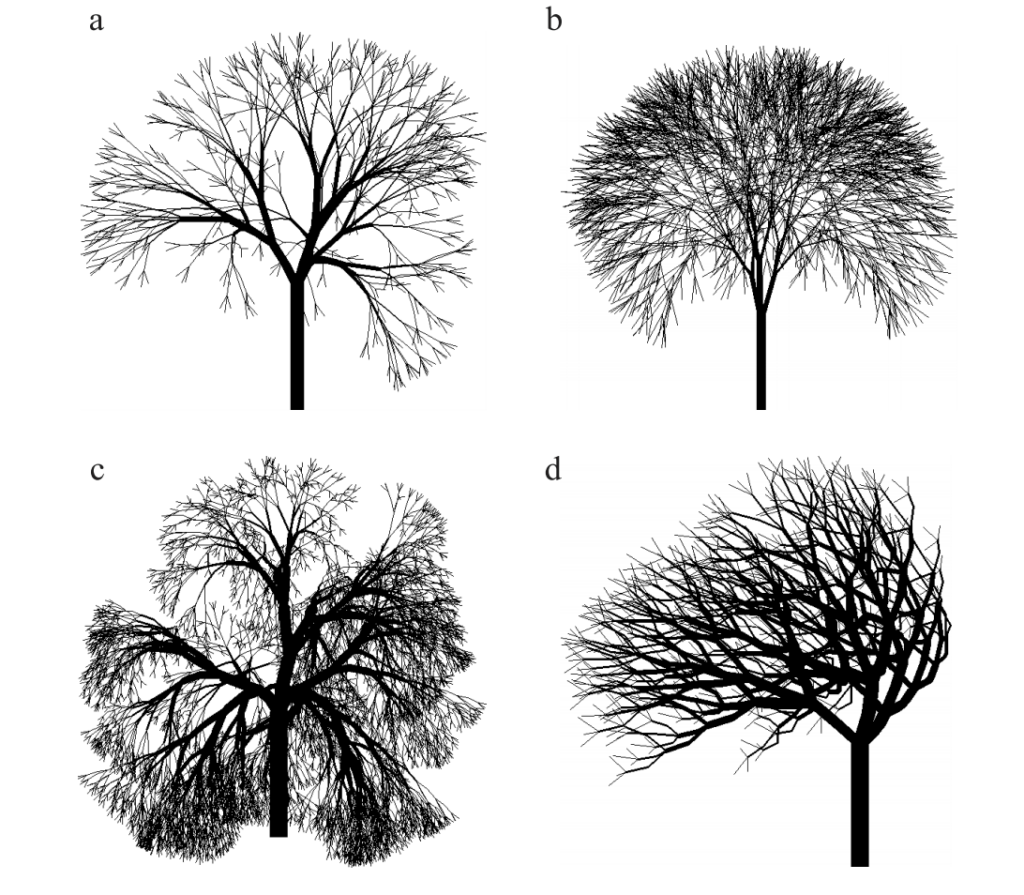
This allows the rule to continue to be applied until a satisfactory result is obtained. The results obtained with this grammar may seem simplistic, but with the right grammar rules and by iterating the algorithm long enough, one can obtain very convincing results such as those presented below. Then you just have to add textures and leaves to obtain a nice vegetation.
L-systems have the advantage of being very simple to define in theory (a single grammar rule can be sufficient). In practice, however, things are not so simple. Indeed, the links between axiom, rule and results in the form of drawings after expansions are very complex. It is therefore difficult to predict the result beforehand and trial and error seems necessary. This site allows you to play with L-systems in order to visualize the predefined grammar results, as well as to modify the rules of these grammars and see the impact on the results.
Another disadvantage is that L-systems are limited to the generation of geometric shapes that have fractal properties. This is why they are mainly used for the generation of plants.
However, there are many extensions to the basic principle of L-systems, such as systems with randomness or context-sensitive systems. These extensions make it possible to produce more varied content. For example, L-systems have sometimes been used to generate dungeons, rocks or cellars.
The image presented earlier in the article with a night tree was generated by a grammar system (more complete than the one presented here). This link presents the rules used to generate the image. The results obtained by these methods can be superb. By slightly modifying the grammar rules, different images can be generated.


Cellular automata-based approaches
Cellular automata are discrete calculation models based on grids. Invented and developed in the 1950s mainly by John Von Neumann, they were mainly studied in theoretical computer science, mathematics and biology.
A cellular automaton is therefore based on a grid. The principle is that each cell composing the grid can have different states (for example two possible states: a living state and a dead state). The states of the cells evolve according to the state of the neighbouring cells at a given moment. In cellular automata, time advances in a discrete way, i.e. step by step.
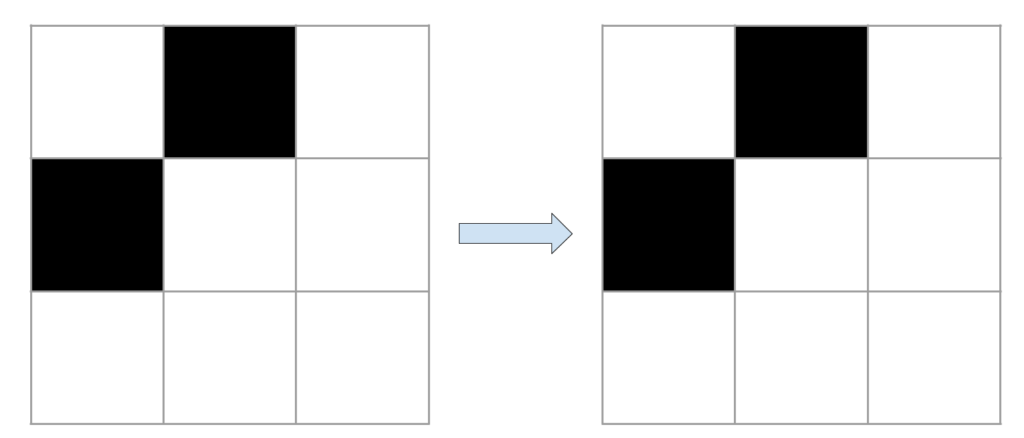
Let’s take the example of the most famous cellular automaton: Conway’s Game of Life to better understand.
The game of life can be described by two simple rules. At each stage, the state of a cell evolves according to the state of its eight neighbors:
If a cell is dead and has exactly three living neighbors, it goes into the living state.
If a cell is alive and has two or three living neighbors it keeps its state, otherwise it passes to the dead state.
Let’s take some visual examples. Living cells are shown in black and dead cells in white. For each example, it is the state of the middle cell that interests us.
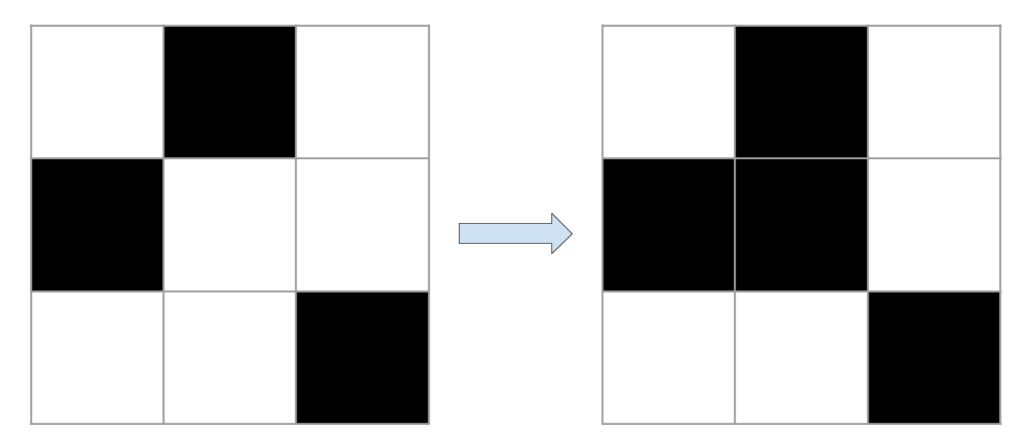
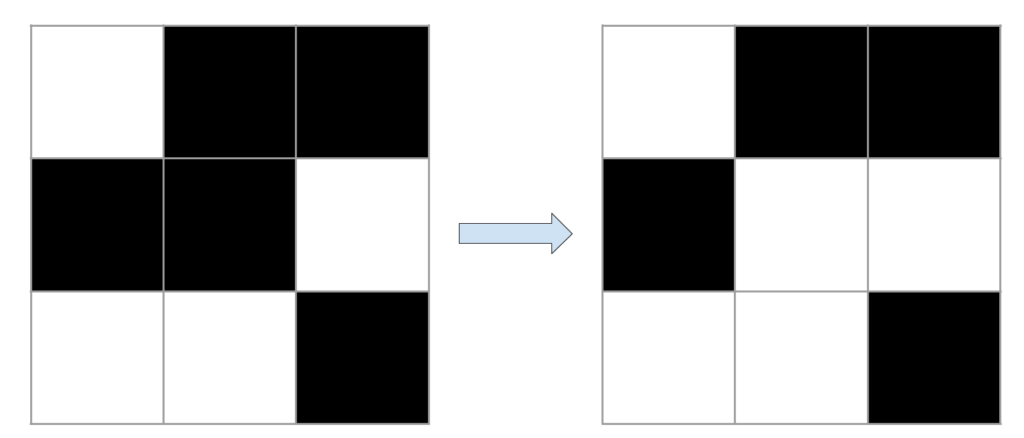
The examples presented above are very simple since we are only interested in the middle box of a very small grid. In general, when studying the behavior of cellular automata, much larger grids are used. In these large grids, more complex shapes can appear and evolve. For example, with the right initial conditions, it is possible to create shapes that move around in the grid. These shapes are called vessels. By considering larger grids and more complex initial conditions, much larger structures can evolve. When the grids become too large, the boundaries between cells are usually no longer represented for better visualization.

Here is an example of a much larger vessel that leaves in its wake objects capable of generating new small diagonal vessels. We can see that a great complexity can appear from an automaton with very simple rules (only two rules for the game of life).
It is possible to build a whole bunch of machines in the game of life and even functional computers (See this link for an example). They are of enormous complexity and extremely slow but they prove that it is possible to get very complex systems from very simple rules. All the elements of a computer (memory, calculation unit, program etc…) are built with different types of objects that it is possible to obtain in the game of life. For example, the bits of information in these computers are represented by small ships. For those of you who want to learn more about the game of life, you can check out this excellent video.
Objects in the game of life generally show behaviors that resemble those found in nature since their evolution is based on simple rules. Cellular automata have therefore been used extensively to model environmental systems. It is for this reason that they are interesting in the context of procedural content generation.
They have thus been used in video games to model rain, fire, fluid flows or explosions. However, they have also been used for map or terrain generation.
For example, in a game of exploration of a cellar in 2 dimensions seen from above.
In this game, each room is represented by a 50*50 cells grid. Each cell can have two states: empty or rock.
The cellular automaton is defined by a single rule of evolution:
A cell becomes or remains rock type if at least 5 of its neighbors are rock type, otherwise it becomes or remains empty.
The initial state is created randomly, each cell having a 50% chance of being in one of the two states.
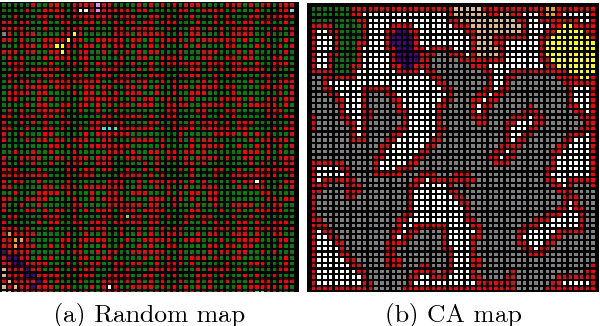
By making the grid evolve from its initial state (left) during several time steps, we obtain a result as on the image on the right with grey empty cells in the middle and red and white rock cells. The other colors indicate areas of voids that are not accessible because they are surrounded by rocks. We notice that the cellular automata allow us to represent erosion.
To obtain larger areas, several grids can be generated and then grouped into a new larger grid.
By changing the number of cells to be considered, the rules of the automaton as well as the number of evolution steps, different types of results can be obtained.
Cellular automata (and constructive algorithms in general) have the advantage of having a small number of parameters. They are therefore relatively simple to understand and implement. However, it is difficult to predict the impact on the final result of the change of a parameter since in general the parameters impact several elements of the generated result. Moreover, it is not possible to add criteria or conditions on the result. We cannot therefore ensure the playability or solvency of the generated levels since the gameplay characteristics of the game are independent of the parameters of the algorithm. It is therefore often necessary to add a processing layer to correct possible problems. Thus in the previous example with the cellular automaton it was necessary to create tunnels manually if the generated grids did not have a path.
In the following article, we will therefore focus on more complex methods, based on research or Machine Learning and which allow, among other things, to add conditions and criteria on the generated results.
Procedural generation approaches with AI
Now that we have seen the main classical approaches called constructive methods, let’s look at AI-based approaches. These approaches can be hybridized and mix AI with more classical methods such as those presented previously. Most of the methods presented in this part are not yet really implemented in commercial games but it seems quite likely that they will gradually make their appearance since they allow to go even further in the procedural generation.
Research-based methods
As we have seen in previous articles, search algorithms are an important part of AI, so they are naturally found in the field of procedural generation. With this approach, an optimization algorithm (often a genetic algorithm) searches for content meeting certain criteria defined upstream. The idea is to define a space of possibilities that corresponds to the whole content that can be generated for the game. We consider that a satisfactory solution exists in this space and we will therefore run through it with an algorithm in order to find this satisfactory content. Three main components are necessary for this type of procedural generation:
A search algorithm. This is the heart of the approach. In general a simple genetic algorithm is used but it is possible to use more advanced algorithms that may take into account constraints or specialize on a particular type of content.
A representation of the content. This is how the generated content will be seen by the search algorithm. For example for level generation, levels could be represented as vectors containing information such as the geography of the level, the coordinates of the different elements present in the level and their type etc… From this representation (often vectorial), it must be possible to obtain the content. The search algorithm scours the space of the representations to find the relevant content. The choice of the representation thus impacts the type of content that it will be possible to generate as well as the complexity of the search.
One or more evaluation functions. These are modules that look at a generated content and measure the quality of this content. An evaluation function can for example measure the playability of a level, the interest of a quest or the aesthetic qualities of generated content. Finding good evaluation functions is often one of the most difficult tasks when generating content with search.
Search-based methods are without a doubt the most versatile methods since almost any type of content can be generated. However, they also have their shortcomings, the first being the slowness of the process. Indeed, each content generation takes time since a large number of candidate contents must be evaluated. Moreover, it is often quite difficult to predict how long it will take the algorithm to find a satisfactory solution. These methods are therefore not really applicable in games where content generation must be done in real time or very quickly. Moreover, to obtain good results it is necessary to find a good combination of a search algorithm, a representation of the content and a way to evaluate this content. This good combination can be difficult to find and require iterative work.
All this being quite theoretical, let’s take an example. One of the use cases where this kind of approach can be interesting is the automatic creation and arrangement of parts. The idea is to be able to arrange a part coherently from a number of objects specified beforehand.
Arranging furniture in a room in a coherent and functional way is a complex task, which has to consider many parameters such as the dependency relationships between different objects, their spatial relationship to the room etc… It is therefore necessary to find a data representation that captures these different relationships.
Data representation
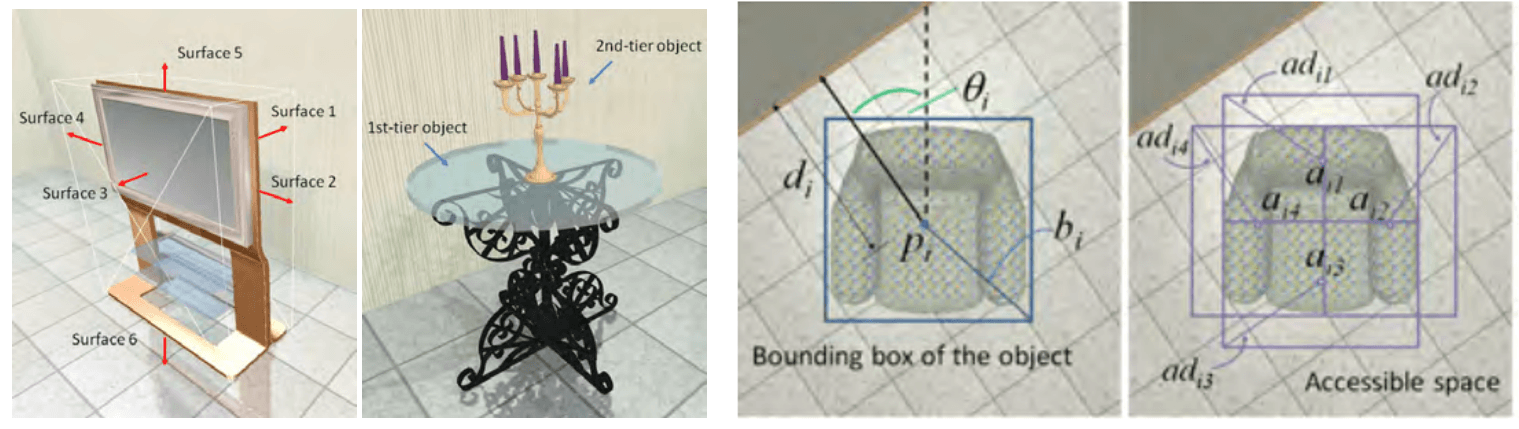
For each object, we assign what is called a bounding box, i.e. a 3-dimensional delimitation of the object. We also assign for each object a center, an orientation, and a direction (for example a sofa with a front and a back side). We also consider for some objects a cone of vision (for example there must be no objects in front of a TV, so we define a cone of vision in front of the TV which must be empty). We also assign other parameters to the objects such as the distance to the nearest wall, the distance to the nearest corner, the height, the necessary space that must be left in front of the object for it to be functional etc… A room is therefore represented by all the parameters of the different objects.
Evaluation function
To know if a part is consistent or not, you need a function that looks at the data representation of a part and returns a score. To know what a satisfactory room is, we use a set of rooms fitted out by hand by a human. We extract relevant characteristics for the placement of the different objects in the room. Thus, we observe the spatial relationships between the different objects. For example, a TV is always against a wall with a sofa in front, a lamp is often placed on a table, access to a door must be unobstructed, etc…
These different criteria are used as a reference in the evaluation function. The evaluation function measures the accessibility, visibility, location and relationships between all objects and looks at whether these values are consistent with those of rooms made by humans. The closer these values are to the example parts the better the score will be.
Research algorithms
The search algorithm used is the Simulated Annealing algorithm which is a very simple algorithm. To start the generation, we tell the algorithm the different objects that we want to put in the room and the search will allow to find a coherent arrangement of these objects. We start with a random arrangement of the objects. At each iteration of the search, a small modification of the room is made. The algorithm allows different layout modifications such as moving an object (rotation and/or translation) and switching the location of two objects.
Then, the new room layout is evaluated by the evaluation function. If the new layout is better than the previous one, it is kept. If, on the other hand, it is worse, it is kept according to a certain probability. This probability of keeping a worse solution is called the temperature and generally decreases with time. Its interest is to avoid ending up in what is called a local optimum, i.e. a good solution but not the best one. The objective at the end of the search is to have found the global optimum and therefore the best solution.
With a fairly long search time, this approach gives very satisfactory results. Other more advanced approaches (such as this one) automatically find the objects to be put in the room.
As said before, this kind of approach is not yet really implemented in commercial games, but we can see right away the interest for environment generation. They have also been used, for example, to create maps in the Starcraft game or in Galactic arm race to automatically find weapon characteristics that appeal to the player.
Other procedural generation approaches can be combined with search methods, such as grammar-based methods. Indeed, since grammars are a representation of content, it is possible to search with an algorithm rather than manually for the rules and grammars best suited to generate its content.
Solver-based methods
Solver-based methods are quite similar to research-based methods since they also involve looking for a solution in a space of possibilities, however the research method is different. Instead of looking for complete solutions that are more and more relevant, these methods first look for partial solutions in order to progressively reduce the space of possibilities to finally find a satisfactory complete solution. Here the search is posed as a problem of constraint satisfaction and the methods of resolution are more specialized (we speak of solvers).
Thus, unlike methods such as the MCTS seen in the previous article which can stop at any time and will always have a solution (probably not optimal but a solution anyway), these approaches cannot be stopped in the research environment since they will then only have a partial solution to the problem.
A simple example of a constraint satisfaction problem is the resolution of a sudoku grid. The constraints are the rules of the game and the space of possibilities corresponds to the set of possible choices for the different boxes. The algorithm will find partial solutions that respect the constraints by filling the grid as it goes along, thus reducing the remaining possibilities. It can happen with this kind of approach to encounter a contradiction where it is no longer possible to advance the resolution while respecting the constraints. If this happens, the research must be restarted.

Usually solvers are advanced enough to try to avoid these problems.
Let’s take an example: the Wave Function Collapse (WFC) algorithm. This approach is really recent, indeed it was proposed in 2016. The approach can be implemented as a constraint satisfaction problem.
The basic idea is to generate a large 2-dimensional image based on a smaller input image. The generated image is constrained to be locally similar to the input image.
The similarity constraints are the following:
Each pattern of a certain size N*N pixel (e.g. 3*3) that is present in the generated image must appear at least once in the base image.
The probability of finding a certain pattern in the generated image should be as similar as possible to its frequency of presence in the initial image.
At the beginning of the generation, the generated image is in a state where each pixel can take any value (color) present in the input image. We can make the analogy with a sudoku grid where at the beginning of the resolution a box can take several values.
The algorithm is as follows:
A zone of size N*N is chosen in the image. In sudoku we start by filling in the boxes where there is only one possible value. Similarly, here the chosen area is the one with the least number of different possibilities. At the beginning of the generation all the zones have the same possibilities since we start from scratch. Therefore a zone is chosen at random to start the algorithm. The chosen zone is replaced by a pattern of the same size present in the initial image. The pattern is chosen according to the frequencies.
The second phase corresponds to a propagation of the information. As a zone has been defined, it is likely that the pixels around this zone are more constrained in terms of possibility. In sudoku, by filling in some boxes, we add constraints on the remaining boxes. Here the principle is the same since the possible patterns are constrained by the basic image.
The algorithm continues by alternating these two phases until all the areas of the generated image are replaced.
Small point of terminology :
In quantum mechanics, an object can be in several states at the same time (cf Schrödinger’s famous cat). This is called superposition of states. This is obviously not possible with objects in classical physics. However, these objects which are in a superposition of states seem to return to only one of the different states when we observe them. It is thus impossible to directly observe the superposition of states. This phenomenon is called wave packet reduction and in English Wave Function Collapse. It is therefore this principle that inspired the designer to develop the algorithm. Indeed, this idea can be found a little bit in the possible values that the different pixels can take, which are reduced as the algorithm progresses.
An interactive version of a simple case of Wave Function Collapse can be found on this website. It is excellent for intuitively understanding how it works and especially how the choice of a cell impacts the possibilities of the surrounding cells.
The github of the WFC algorithm presents a lot of resources and examples of what can be done with this algorithm. Since the algorithm is a constraint satisfaction problem, it is precisely possible to add new constraints (such as the presence of a path for example) to force a different result.
The Wave Function Collapse approach is quite simple to implement and gives very good results. That’s why it has been very quickly implemented in the world of independent video games (for example in Bad North released very recently and in Caves of Qud still in early access).
Machine learning methods
Machine Learning-based procedural generation learns how to model content from previously collected data in order to generate new, similar content. The content data that will be used to learn the model can be created manually or possibly extracted from an existing set for example. In any case, this step of building a dataset is crucial and if the data is not in sufficient quantity and quality the results will most likely be bad.
In search-based approaches, the expected result is defined quite explicitly (through the evaluation function) and a search in the possibility space is carried out to find a solution that corresponds to the required criteria. With Machine Learning, the control over the final result is less explicit since it is the Machine Learning model that will directly generate the content. It is therefore mainly the work on the learning data set that will condition the final result.
In commercial games, this approach is still very little democratized, with developers most often opting for simpler approaches (such as WFC for example). The main reason is probably that it is quite difficult to build a dataset large enough to model the content well. However, research in the field is very active and many new methods are regularly emerging. It is likely that in the coming years, more and more games will rely on these approaches to procedurally generate their universes.
So let’s take a look at some of the interesting possibilities offered by Machine Learning.
Tiles method with machine learning
Probably the simplest Machine Learning methods for procedural generation are Markov models and especially Markov chains. Markov chains are a set of techniques that learn the probabilities of occurrence of elements in a sequence based on the preceding elements of that sequence. These methods have been used in the world of research to generate new levels in Super Mario Bros.
To do this, the levels in the game have been cut into vertical strips. Thus, a level can be represented as a sequence of vertical strips. The Markov Chain will study a set of Super Mario Bros. levels to learn the probability of a certain vertical stripe by knowing the beginning of the level and thus the previous vertical stripes.
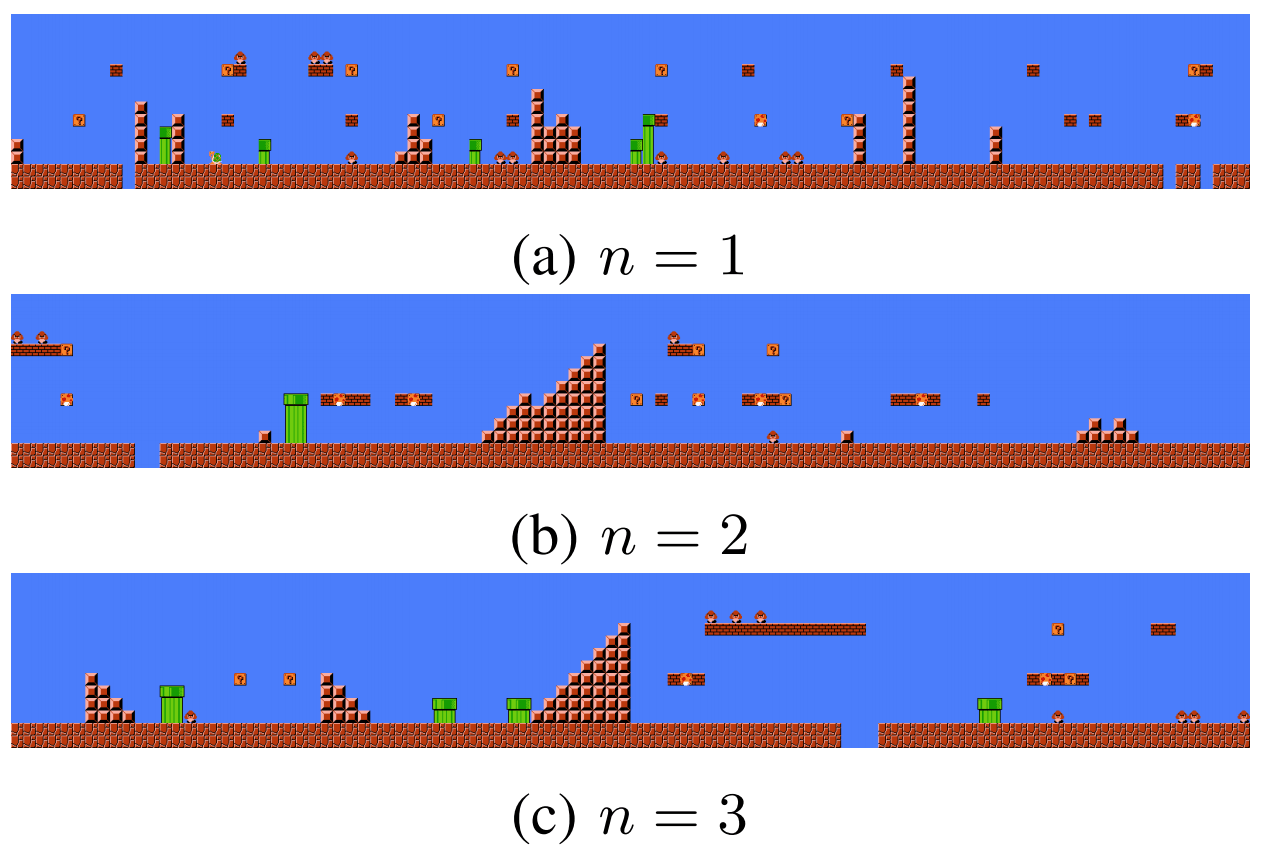
By choosing a random vertical band to start the level and then generating the level from left to right band by band according to probabilities it is possible to generate whole levels. In general, we calculate the probabilities of a vertical band according to a certain number n of previous bands (If we take each time all the vertical bands since the beginning of the level it becomes very heavy to calculate). Taking for example n=1, each band is only conditioned by the previous band. In practice, this generates levels that are quite different from the classical and difficult to finish levels. By taking into consideration more previous bands (e.g. 2 or 3), you get levels that are much more consistent and close to what you expect from a Super Mario Bros. level.
This method gives quite good results especially in terms of local consistency, but it is obvious that without access to existing levels it is not possible to apply it since it is not possible to calculate the different probabilities between the vertical bands.
Many approaches mixing Machine Learning and tiles have been proposed in the research world. With these approaches, it becomes possible to generate new realistic examples from just a few examples.
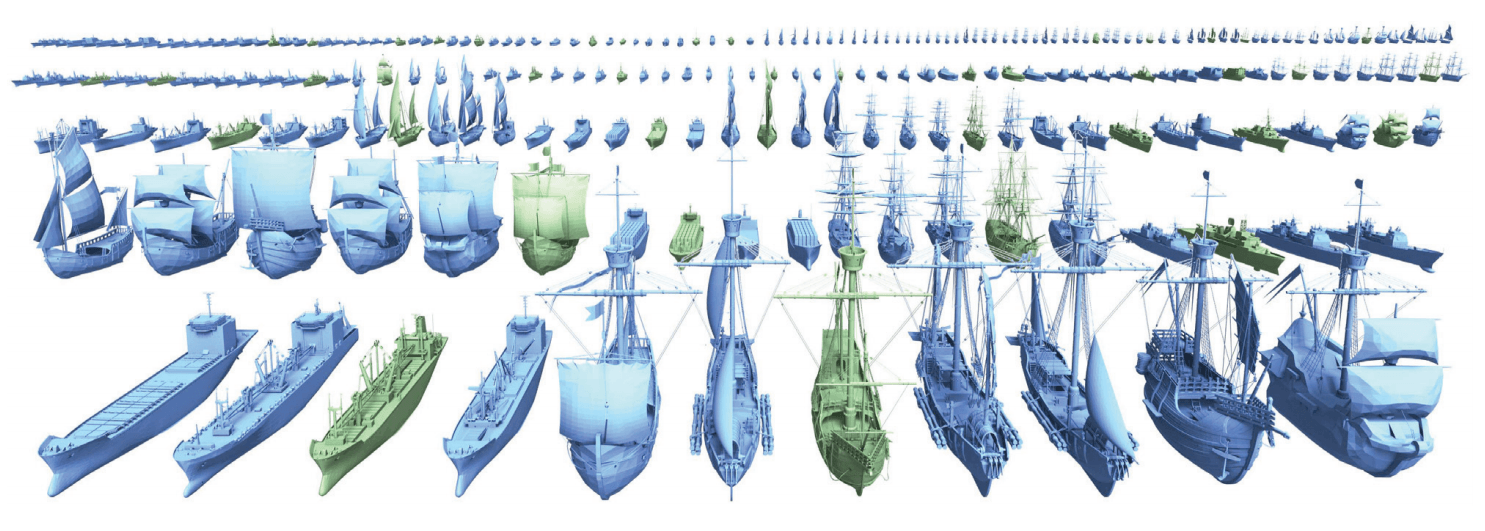
The Machine Learning in procedural generation is a promising axis since it allows new approaches, however to obtain systems that work, it is necessary to have sufficient data and to find out how to represent this data in a relevant way. And when we talk about data representation in Machine Learning, it seems interesting to look at Deep Learning.
Deep Learning
Deep Learning, a sub-domain of Machine Learning that has recently emerged, extends the possibilities of the classical models in many areas. The procedural generation is one of them.
Sequences
Deep Learning allows you to manage data that are in sequence form more efficiently than traditional algorithms thanks to a particular type of network called Recurrent Neuron Networks (RNN). It is mainly with these networks that word processing (NLP) has been profoundly modified. Indeed, text data are sequential.
Recurrent networks are quite similar to classical neural networks with the difference that they receive input data sequentially rather than all at once. Thus, a recurrent network applied to text will receive the words of a sentence one by one in the order of the sentence. When the network processes a word, it therefore has information about the previous words in its memory, which can help it in the analysis.
However, classical recurrent networks are quite limited in terms of memory. They cannot correctly keep information more than 5 or 10 steps in time, which is generally not enough to analyze or generate a complete coherent sentence (difficult to understand if at the end of the sentence, one has forgotten the beginning).
A variant of recurrent networks was proposed in 1997: LSTMs (Long Short Term Memory). These recurrent networks are more complicated, they present a mechanism to determine what is important to remember and what can be forgotten. Thanks to this mechanism, LSTMs push the memory limits of classical RNNs and are therefore much more used.
Procedural level generation sometimes represents levels in sequence form (to apply Markov Chains for example), so it is quite possible to use Deep Learning in a similar way to generate levels.
Thus, by representing a level as a sequence of vertical slices and having a dataset with enough levels, it is possible to teach an LSTM to generate a new sequence of vertical slices and thus a new Mario level. LSTMs, unlike classical RNNs and older methods like Markov Chains, allow to model quite long sequences correctly. This makes it possible to obtain Mario levels with both a good local consistency (which we already obtain with classical methods) but also a global consistency.
One of the advantages of neural networks is that they allow you to represent data in different ways. It is therefore possible to generate Mario levels other than by creating vertical slices. Indeed, this method has some disadvantages, the main one being that it will not be possible to generate a level with vertical slices that were not already present in the initial dataset. The levels generated are therefore likely to be quite similar to the levels used in the learning process.
Another approach is to represent a Mario level as a data grid where each element of the grid corresponds to a block in the game.
With this representation, a level is no longer generated slice by slice but block by block. A Mario level being in 2 dimensions, there are several possible orders of block generation. You can already generate the level horizontally or vertically.
The horizontal method would start for example by generating from the left of the level the highest line of the sky (so with just blue blocks) then, once arrived at the right edge of the level would return to the beginning of the level to generate the line below and so on. This approach is probably not the best since it makes vertical consistency between different elements difficult to ensure. For example, if a cloud is present on two vertical lines, and it has started to be generated, you have to make sure when generating the second line that you finish it well. However, in terms of generation, the end of the cloud arrives long after the beginning. If we consider that a level of mario is 500 blocks long, the network will have generated 500 blocks between the beginning and the end of the cloud. LSTMs have an improved memory compared to classical recurrent networks but 500 generations is probably still too long to ensure good results in all cases. A vertical generation approach therefore seems more relevant.

With this approach, the level is generated column by column. With this generation, there is no more problem of vertical consistency since the elements are generated one after the other. On the other hand, there may now be a problem of horizontal consistency. However, a level making about fifteen blocks vertically, it is much easier to finish an object started at the previous column since only about fifteen blocks will have been generated in the meantime, which is quite within the LSTM memory chords. Another approach called snaking, generates the blocks by snaking from top to bottom and then from bottom to top rather than always generating from top to bottom. With snaking, the number of generations between two columns is further reduced and therefore it improves the consistency of large objects like ramps even more.
With vertical generation and snaking, it is possible to generate new and interesting levels of Mario using a relatively small number of existing levels as a basis for learning (a few dozen).
Mario is a 2-dimensional game but the levels are very linear. Usually you just have to go from left to right to finish the level. That’s why generating a Mario level is a relatively easy task. More complex exploration games where you have to explore several paths, retrace your steps etc… (such as Metroid or Castlevania) are much more difficult to generate. As soon as a real 2-dimensional coherence is needed, approaches with LSTMs on sequences show their limits. However, other approaches seem to be able to address these issues. For example, in this very interesting article a development team explains the different approaches they have tested in order to succeed in generating levels with 2-dimensional consistency for their Fantasy Raiders game.
Deep Dream and Style Transfert
So far, the main focus has been on recurrent networks and thus sequential data, but Deep Learning also makes it possible to do things that were previously impossible in the field of images. Indeed, convolutional networks are a type of neural network with exceptional performance in image processing and comprehension tasks. One of the first really striking examples was probably Google’s Deep Dream algorithm.
The strength of convolutional networks lies in their ability to represent data in a relevant way. For example, a neural network trained to classify animal images, learns to extract important features from the images in order to build a representation that will allow it to solve the classification problem. The network thus learns to extract the common characteristics of dogs, cats etc…
The idea of Google’s Deep Dream algorithm is to force the network to show the internal representations that the network has learned. This is done by running the network upside down. We give it an image as input and ask it to accentuate in the image the elements it recognizes. In the image of the sky, if part of a cloud looks like a dog’s head, the network will accentuate this by showing what a dog looks like in its internal representation. By iterating this process several times on the same image, we get results like the sky image where the network has drawn shapes all over the image. Since the network used was trained to recognize animals and buildings, this is the type of shapes it drew.
It is also possible to completely generate a new image with Deep Dream by giving white noise as input.
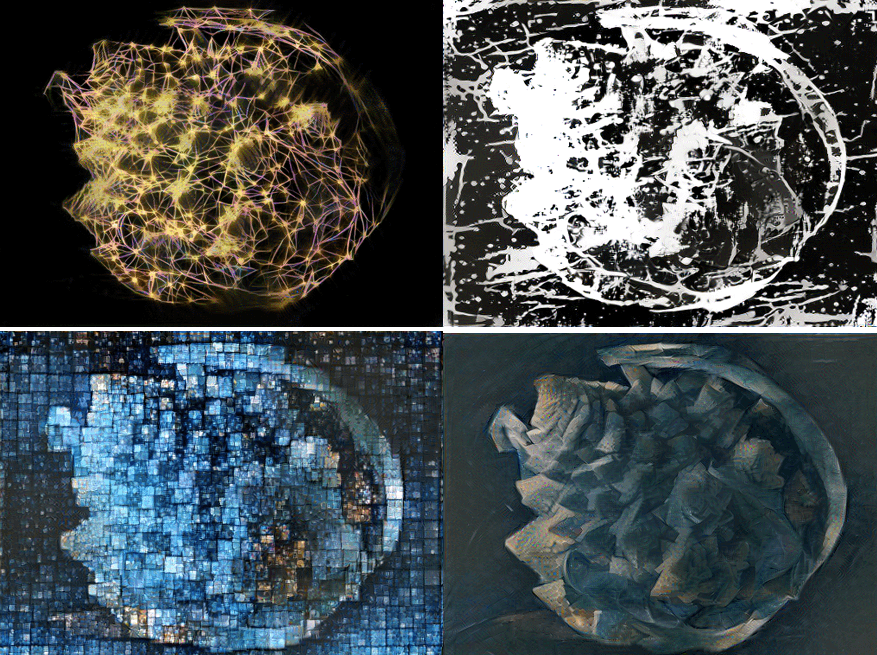
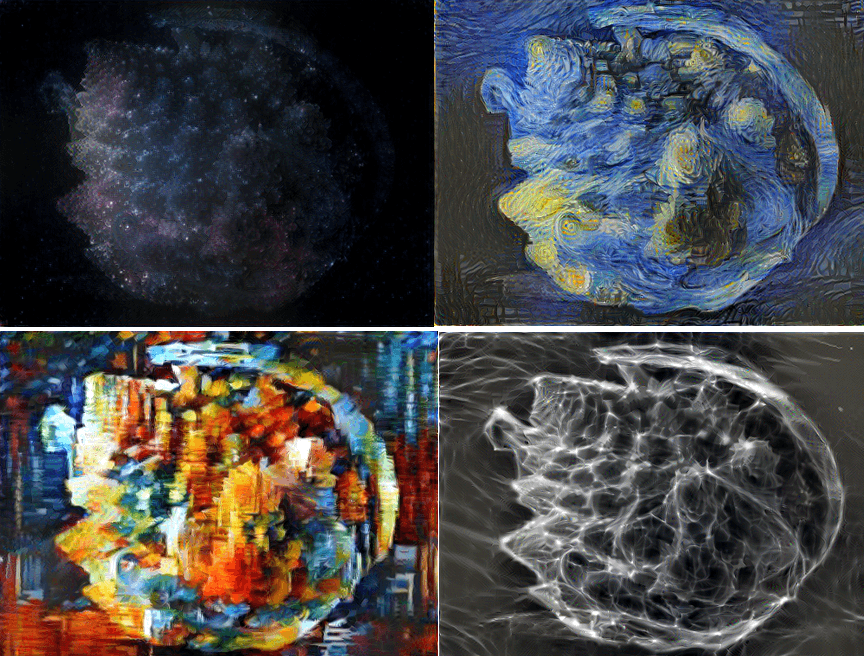
This method offers opportunities in procedural generation, especially for generating textures for example, but above all they show the potential of data representations of convolutional networks and Deep Learning.
Another method seems to have more direct applications in procedural generation: the Transfer Style. The Transfer Style applies the style of one image or work to another image. The idea is to use the internal representations of images that a neural network is able to build. By working with these representations, it is possible to bring two images stylistically closer together while keeping as much as possible of the content of the initial image.
These new approaches show to what extent neural networks are capable of “understanding” images. This in-depth understanding thus allows for automated transformation and content creation that was impossible to perform before.
This is why it offers new opportunities or new ways of working within the framework of procedural generation. For example, the Transfer Style seems to be able to accelerate the work of artists by applying a particular style to a set of resources very quickly.
This article presents how a creative developer managed to apply the style of a film from the Ghibli studio (Le Château ambulant) on a procedurally generated 3D terrain.
For now, the use of these methods still requires a lot of trial and error. To take full advantage of them and see a real use in video games, it will probably be necessary to find simple and reliable ways to collaborate between the artist and the algorithm, but at the moment these methods are already quite promising.
GANs
The two previous approaches are interesting, but when we talk about generation and Deep Learning, another type of architecture in particular stands out: GANs (Generative Adversarial Networks).
A GAN is an architecture that brings together two networks of antagonistic neurons. At the input of these networks, a set of content data (often images) is provided. One of the two networks has the task of generating content similar to that of the input data set and the other network must be able to distinguish the real data from those generated by the first network. Both networks learn simultaneously and compete with each other during the learning process, which ultimately allows each network to improve in their respective tasks. At the end of the learning process, only the generative network is kept, which in theory is capable of generating new content very similar to the initial content.
GANs could be used, for example, to generate levels of the DOOM game (1993). To do this, researchers relied on more than a thousand levels of the game created by the community. For each level, they extracted several images describing the layout of walls, ceilings, objects, enemies, etc. For each of the levels, they extracted several images describing the layout of walls, ceilings, objects, enemies, etc. Each level is thus entirely described by 6 images seen from above. The GANs are trained on these images and at the end of the training is able to generate new images which are then transformed into levels.
In this video, we can see the images generated by the network as it is being trained. At the beginning, GANs generate informal levels, but as the learning progresses, they look more and more like human-generated levels. At the end of the video, we see them playing in one of the generated levels.
GANs have probably attracted the attention of the general public for the first time with the pix2pix algorithm that allows to transform an image. For example, one can go from a black and white image to its colored version, from a sketched image to its realistic version, or from a daytime image to the same image at night.
To be able to learn this network, you must already have a data set of image pairs (for example, a pair corresponds to a sketch drawn and the complete corresponding image).
During learning, the generator takes a sketch as input and generates a complete image. The discriminator looks at the resulting pair of images (the sketch and the generated image) and tries to determine whether the pair comes from the original data set or whether the image was generated. The two networks improve as they are learned and at the end we get a generator capable of transforming any sketch into an image. One of the versions of this algorithm that has much more is Edges2cat that has been trained on pairs of cat images.
By inputting a fairly detailed sketch, we get a photo-realistic result. When one is less talented and gives a sketch like the one below, the results are less convincing, but still correspond well to what is requested from the network.
Surprisingly enough, even when you give sketches that do not represent cats at all, the network manages to get by and tries to generate a cat with the requested shape.

This approach has of course been used for procedural field generation. As we have seen previously, procedural field generation often goes through Perlin noise or its variants (such as uber noise for No man’s sky) with rather uneven results, since a lot of manual adjustment is often required.
With a method very close to pix2pix, it is possible to learn a network able to go from a very simple sketch of a terrain to a 3-dimensional modeled terrain. It is then enough to work on the sketch to modify the result in 3D, which saves a lot of time. In this short video, we see how this method is used in real time to generate realistic terrains.
GANs are a rather flourishing research topic (the list of different GAN variants published is quite impressive), and their use cases are varied. It is impossible to present all the initiatives related to video games, but here is one last one that is quite interesting. Based on CycleGAN (a kind of enhanced version of pix2pix), this method applies the graphic style of one game in another game. The results are quite impressive, this article gives more details.
To conclude
Procedural generation approaches based on AI and mainly those with Deep Learning seem really promising, but they clearly do not solve all the problems. Indeed, Deep Learning is well adapted to natural data such as images, text or sound, but less so to data with strong structural constraints.
For example, GANs still tend to occasionally generate impossible images such as spiders with too many legs or tennis balls.

When you want to generate the level of a game, this kind of erroneous generation is a problem. Indeed, a very nice level that is not finishable is of little interest. The problems posed by the procedural generation of content in video games are therefore somewhat different from those of the generation of simple images or text, and the methods must therefore be adapted. However, research work on DOOM has proven that it is possible to use GANs for this kind of use case.
Without being 100% reliable tools, it is clear that these methods seem to be able to accelerate or facilitate the work of developers and artists. It is difficult to predict whether approaches with Deep Learning will replace more traditional approaches, but it is clear that they bring new perspectives and inspiration to content generation methods.
In any case, it is likely that in the future most game development will be automated and humans will take care of the most creative tasks. For those interested to go further, this github gathers a lot of interesting resources on procedural generation.
Video games to make AI go further
Recently, a lot of media have been covering AI and video games, presenting agents capable of competing or beating professional gamers on complex video games such as Dota 2 or very recently Starcraft 2 with the AlphaStar algorithm.
So far we have focused on what AI can bring to the world of video games. We’ve seen how it can help create bigger, livelier, more coherent worlds etc… However, the relationship between the two fields doesn’t stop there. Video games can be a way to improve and accelerate research in AI. In this part, we will therefore focus on video games as a medium for AI research by presenting some important achievements in the field.
The interest of video games
How can games help develop better AI systems and why are researchers so interested in video games? The goal of AI research is to produce increasingly complex agents capable of understanding their environment, reasoning and making complex decisions. Ultimately the idea is to have agents capable of making important decisions (e.g. economic, environmental, etc…) by taking into account more parameters than it is possible for a human to do so.
The best approach we have at the moment to reach these goals is based on learning. Thus, rather than explicitly telling the agent how he should act, we will try to make him learn a behavior on his own. We talk about Machine Learning and more specifically about learning by reinforcement. This is a very open learning framework that allows for good results on a variety of tasks. However, in order to implement this learning, you need data. Lots of data. And it often requires a clear goal to guide the learning.
Real-world issues are generally quite difficult to represent in this framework since there are often no large volumes of accessible data or well-defined objectives.
Games are therefore very conducive to AI learning since they can be quite similar to the real world while offering very clear objectives (e.g. beat the player face to face, or maximize a score). Thus, the Starcraft game represents a partially observable environment where the player has to make strategic decisions without having access to all the information. This environment can be compared in terms of complexity to real-world competitive scenarios such as logistics or supply chain management for example.
In addition, games can be played a very large number of times since they are programs, which can generate a lot of data. The process can also be accelerated by parallelizing the learning process over hundreds or thousands of instances of the game at the same time.
Transferring learning directly from a video game to a real-world problem is difficult. However, the methods invented to solve problems in games often prove useful for other real-world problems as well.
For example, the Monte Carlo Tree Search method (invented for the game of Go) discussed in previous articles has already been applied to real-world problems such as planning interplanetary trajectories of space probes. Similarly, the reinforcement learning algorithm developed by OpenAI to play Dota2 could be used almost directly to learn in a simulation how to control and move objects with one mechanical hand.
OpenAI developers even managed to transfer what was learned in this simulation and apply it to the real world. Thus, they taught a real mechanical hand to control objects by learning in a simulation using an algorithm developed for a video game.
Media evolution
Games (mainly chess) have long been considered the “drosophila of AI”. Drosophila or “fruit flies” have been used extensively in laboratories for genetic research. Although it is not of interest in itself, it is very useful for research since it reproduces very quickly and is simple to feed and store. It is therefore easy to test and compare different experiments quickly.
The games in the same way provide a simple and stable environment to measure the performance of different AI algorithms. Checkers games and then chess have therefore long served as a benchmark for AI research. However, as research evolves, when a game becomes too simple to solve with current methods, a more difficult game is found for the benchmark. Thus the game of Go has replaced chess and video games such as Starcraft II or Dota 2 replace the game of Go. The interest of AI research for video games thus remains relatively recent. The majority of AI competitions and benchmarks carried out on video games date from the last ten years.
A large scale interest
Games are good mediums since they generate public interest. You only have to see the craze generated by e-sport competitions on the biggest games to realize the importance of the phenomenon. Moreover the oppositions between IAs and humans have always fascinated or at least interested most of us.
Thus, games allow to measure the evolution of the performance of AI algorithms in a way accessible to everyone. Knowing that an algorithm has beaten the world champion in chess is probably more telling than knowing that the state of the art in image classification is 2.25% in top-5 error on ImageNet.
Another more materialistic point is that by getting the general public interested in AI issues, we decrease the risk of seeing a new AI winter coming (a freeze on AI investments).

Research in AI
Before the deep learning
The Pac-Man game has been quite important in the development of interest in video games in the AI research community. Thus, Pac-Man was considered an interesting problem for AI in the early 1990s, but research really started on it in the early 2000s. Early approaches to game play were based on genetic algorithms and simple neural networks.
Soon, the research moved on to the Ms. Pac-Man game which added a little bit of randomness to the ghost movements, making the problem more difficult from an algorithmic point of view. The growing interest of researchers in Ms. Pac-Man led to the creation of two competitions based on the game. The first, the “Ms. The first, the “Ms. Pac-Man AI Competition” took place from 2007 to 2011 and the goal was to develop an agent that would score the highest possible in the game. The second competition, “Pac-Man vs Ghosts competition” took place from 2011 to 2012 and was aimed at developing agents to control ghosts. The agents controlling Pac-Man and those controlling ghosts played against each other.
These two competitions allowed to improve certain domains, in particular genetic algorithms, but it is especially the MCTS method (still it) which was much developed thanks to this game. Approaches based on reinforcement learning were tested but without much success compared to other approaches.
The interest of the scientific community in these competitions launched the field and thus competitions on other games were created. Today the interest in AI for Ms. Pac-Man has fallen, but the game was important for the field.
Another important game was Super Mario Bros. with “The Mario AI Competition” which took place from 2009 to 2012. The competition was initially oriented towards creating agents that could play the game like the ones on Ms. Pac-Man. The game being very different, this presented an interesting alternative from a research point of view. Many solutions were proposed, including classical approaches based on reinforcement learning, genetic algorithms and neural networks, but the first place was won to the surprise of all by an agent implementing a simple A* search algorithm. This video shows the agent in action. This highlighted the fact that a very simple but well implemented algorithm can do better than more complex solutions. In the following years, more labyrinthine levels of Mario were proposed and the A* algorithm quickly showed its limits.

In 2010, a procedural generation task on the game was proposed. See part 3 of this series and this article for more details on the proposed solutions. Thus, AI in video games was no longer limited to simply making agents that play games well.
In 2012, another research approach was proposed: setting up agents that play exactly like humans. The objective is that an outside person looking at the way of playing cannot determine whether it is a human or an AI that plays. So we talk about a Turing test for a game since it is a variant of the classical Turing test.
This stain on the Mario game took place only one year and the agents were not able to pass the test.
However, this task was also proposed on other games, notably on Unreal Tournament 2004 between 2008 and 2012. On this game two agents were able to pass the test in 2012. The two agents learned to imitate human behavior to the point where they showed almost indistinguishable behavior.
Since deep learning
The advent of Deep Learning in 2012 has transformed many areas into AI such as image recognition or language analysis. The world of AI on video games has also been strongly impacted mainly through the evolution of reinforcement learning.
In decline since the early 2000s, the interest for reinforcement has been revived by DeepMind in 2013 and their solution called DQN (Deep Q-Network). They managed to create a Deep Learning based reinforcement learning system capable of playing some old Atari 2600 games as well as humans using only the images of the game (as a human would play). They then improved their solution in 2015 (after a buyout by Google in the meantime). This time, the algorithm plays better than professionals on about 30 games and almost as well on about 20 others.
Where their solution is interesting is that they used the same architecture with the same parameters for all the games. A network learning for each game is well done, but it is each time the same initial network, which is an important advance in Machine Learning where it is often necessary to design a specific architecture for each problem. Having a single algorithm capable of developing a wide range of skills on various tasks is one of the objectives of general artificial intelligence.
Before going into more detail about their solution, let’s first take a look at reinforcement learning.
Reinforcement learning and Q-Learning
Reinforced learning is the last main approach of Machine Learning (along with supervised and unsupervised learning). It is the freest form of learning since it does not require any data upstream, the data will be somehow built up during the learning process. Many use cases can therefore be handled through reinforcement learning. However, in practice it is also the most difficult approach to implement and operate, precisely because the data is much more raw than for supervised or unsupervised approaches.
The approach takes up the notions of agents, environments, states and actions that we saw in the first article of this series with finite automata.
As a reminder, in a video game, a state corresponds to any situation that can be encountered in the game. In general, even simple games have a very large number of states.
An action corresponds to one of the possibilities that an agent has to move the game from one state to another. For example, an agent’s moves are actions.
Here, instead of manually defining the actions that the agent must perform according to the state it is in, we will let the agent find the relevant actions to perform by itself. To decide if an action is relevant the agent will use a notion called reward. For each action performed, the agent receives a reward. This reward will indicate whether the state the agent is in is positive or not. In general, we define the agent in such a way that he tries to do the actions that are supposed to maximize his rewards in the future. In this way, it tries to estimate the best way to act to obtain the most rewards overall.
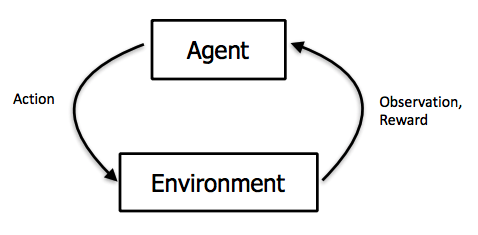
It is the designer of the algorithm who must define how the rewards are distributed so that the agent can learn. If the reward system has been well defined, maximizing the rewards is equivalent to solving the learning problem. If it has been poorly defined, the agent will maximize the reward but will not necessarily act as expected, so this is one of the crucial points in successful learning.
With reinforcement learning, the dataset is built iteratively according to the different actions performed by the agent. A data sample therefore corresponds to a state transition, i.e. an initial state, the action performed by the agent, the state after the action and the reward obtained for the action. With many samples like this, it is possible for an algorithm to learn the best actions to perform in order to get the most reward.
In real life, it is difficult to construct these samples because you have to actually perform actions and observe the rewards. However, in a simulation or a video game, this does not usually pose a problem.
Let’s see an example of an algorithm with Q-Learning. Q-Learning is an approach based on a particular function called Q-value.
The Q-value function can be considered as a large table of values that groups all the states and all the possible actions associated with them. For each possible state and action, we have a value that represents the reward we can expect to get if we perform that action while in that state.
Thus, whatever state you are in, you only need to look at the values of the different actions in the table to know how to behave.
To build the Q-value table, one must therefore play the game and test all the actions in all possible states and observe the rewards obtained. If the game is not deterministic, i.e. if certain events in the game are random, you have to test each action in each state several times. It is quite clear that if one plays a game with many states and actions it becomes impossible. So, rather than building the whole board, we will try to approximate it. The idea is to be able to construct a function that gives the estimated reward value for any pair of states and actions but without having to calculate everything.
The best function approximation tool currently available in AI is Deep Learning. The idea of the DQN (Deep Q Network) is to do Q-Learning by approximating the Q-value table with a neural network.
DQN
This approximation of the table with Deep Learning is possible because a neural network is able to find similarities between close states. Thus, it will not be necessary to test all the possible cases to estimate the Q-value in a relevant way.
Let us concretize this by looking at the Atari problem. The different Atari 2600 games run on an emulator which allows to easily retrieve the different images (we talk about frames) and to connect an algorithm which will perform the actions instead of the player.
The algorithm has access to the same information as a human player so that the comparison can be coherent. The states of the game are therefore simply the frames of the game.
There is, however, a small subtlety: in reinforcement learning, a state must contain all the information necessary to understand a given situation in order to be able to predict what will happen next. It is said that the future must be independent of the past in view of the present.
Let’s take the breakout game as an example. If we define a state as a single frame, we have a problem: we don’t know in which direction the ball is moving. We can’t clearly determine the continuation of the movement. To solve this problem, we just have to define a state as a succession of frames. In their solution, DeepMind use four frames to define a state.
The possible actions are the different key combinations allowed by the games. At most, there are eighteen actions (ten,seven actions allowed by the joystick of the Atari 2600 of the time + the action of doing nothing), but in many games the number of actions is much smaller. For example in Pong there are three possible actions (up, down and do nothing)
Finally, the goal to maximize is the game score. This is visible at the top of the frames so you just have to extract it to know if the chosen actions had positive or negative results. The objective of the algorithm is to take the decisions that will maximize the expected future score.
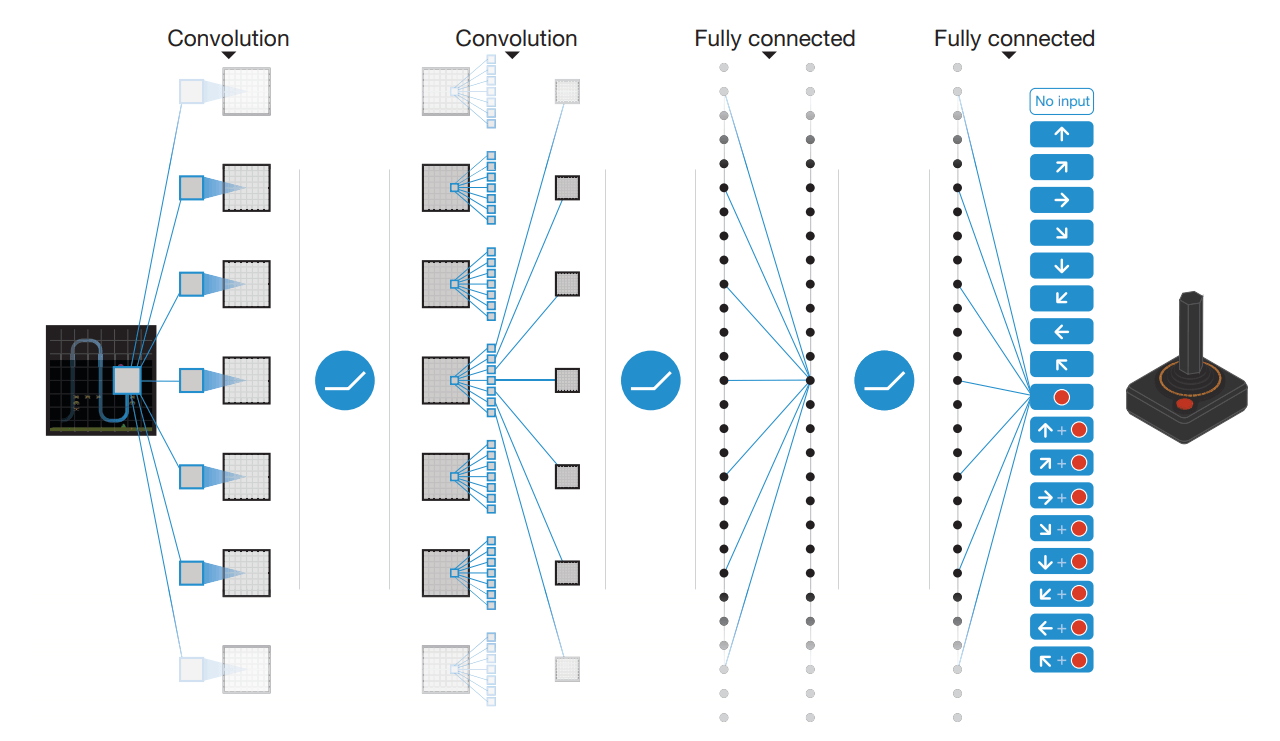
The Q-value table is replaced by a neural network that takes a state of the game as input (so 4 frames). The network will process these frames and in output indicate the expected reward for each of the different possible actions. By taking the best action we maximize the reward and thus the score on the game.
So far we have described how the neural network works, but we have not yet seen how the learning process takes place. In fact, at the beginning the network has never played the game, it has not seen any frame and therefore it does not know how to estimate which actions are relevant.
A classical neural network (i.e. in the context of supervised learning) is learned by comparing one’s own predictions with a ground truth (a label). For example for image classification, if a network predicts that the image is a dog while it is a cat image, the network will have a big prediction error.
This error will then be used to update the different weights of the network so that it won’t make such a big mistake if it ever sees this cat image again in the future.
When you do reinforcement learning, you don’t have access to a ground truth since you don’t have a label. So you have to find another way to calculate your prediction errors.
The only information you have when you do reinforcement learning is the reward associated with the action you have just chosen and the new state you are in.
Thus, we can compare the future rewards that we estimated before doing the action with the future rewards that we estimate in the new state once the action is done. By comparing these two estimates of future rewards and taking into account the true reward for the action taken, a network prediction error can be calculated. The network thus uses itself to measure its performance and thus improve. This practice of using the same network in the next state to self-evaluate itself is called bootstrapping.
There is a problem with the DQN. The idea of applying neural networks to Q-Learning is not new. Indeed, it had already been applied when the name Deep Learning did not yet exist and this idea did not work. When doing Q-Learning with a neural network, learning tends to diverge because of the so-called Deadly Triad. In practice, what happens is that a network that uses itself to evaluate and improve itself has a strong tendency to learn anything.
To combat this and still allow learning, DeepMind has proposed two ideas:
The first idea is to use a second neural network in parallel with the first one to estimate errors. The second neural network is updated much less regularly than the first one. Thus, the prediction error is not calculated based on a target that changes all the time, but rather on a stable target generated by a network that is fixed most of the time. This helps to stabilize learning.
The second idea is to use what they call a replay experiment. This can be seen as a library containing a large number of states, actions and past rewards (for example 50000). Instead of learning the neural network by following the course of the game, we randomly draw in the library triplets of states, actions, rewards that will be used to update the network. The idea with this method is to remove the temporal correlation that we can have when we take the actions sequentially, which also stabilizes the learning.
Once the network is learned, one can display the Q-values for different states to see what the agent has understood about the game. The agent controlled by the algorithm is on the right in green. In the Pong game there are three possible actions: up, down and do nothing.
In state 1, the ball is still far away so the algorithm estimates that all three actions are worth the same in terms of reward.
In state 2, the ball is getting closer and the estimated reward value of the “up” action increases while the reward value of “down” and “do nothing” become negative. The algorithm has understood that if it does not go up from now on the point will be lost.
In state 3, the agent continues to do the “up” action and hits the ball.
In state 4, the ball has gone to the other side and the point will be won so the algorithm has understood that whatever action is performed the point will be won. That’s why the values of the three actions are 1.
For each of the games, the learning process was carried out on 50 million frames, which corresponds to nearly 38 days of games in total. Since the agent was trained on an emulator, all the games were actually played in accelerated mode, so the training did not really take 38 days.
The DQN is not an efficient algorithm, it needs a lot of data to achieve a satisfactory level. For example, it takes 38 days to learn how to play games, whereas a human would probably need 30 seconds to understand how they work. Numerous improvements to the algorithm were subsequently proposed in order to improve this efficiency and thus allow for the learning of more complex tasks.
Renewed interest in strengthening
The success of the DQN has really rekindled the general interest in reinforcement learning. As a result, many variants and improvements of the algorithm were quickly developed.
The problem posed by the Atari environment being largely solved, new and more difficult topics had to be found. Thus, many video game research platforms were deployed in order to facilitate and accelerate research.
Good research environments or platforms are important to be able to develop and compare algorithms in an efficient and serious way. The main technical platform is probably OpenAI Gym. It is a fairly simple interface in Python that facilitates the comparison of reinforcement algorithms. Most of the research platforms that exist are based on Gym. It is not possible to cover all platforms, so we will present a few that seem important.
OpenAI environments
First of all, there is Universe, developed by OpenAI in 2016. Universe widened the possibilities offered by the Atari environment by proposing to work on flash games or even games like GTA V. The objective of Universe was to be able to generalize a learning made on a game to other games or other environments. Universe was probably too ambitious and the results were not conclusive. The main problem was that in order to be able to launch such varied types of games, the environment launched a chrome browser in a docker. Because of this choice of implementation, the system was not stable and the algorithms had to interact with the games in real time, which is a hindrance to learn a lot.
This is why OpenAI has developed Retro to replace Universe. The goal of Retro was to return to a more reliable system while offering environments that remain challenging for the algorithms. With Retro it is therefore only possible to learn models on Mega Drive games (SEGA console). Mega Drive games are more advanced than Atari games, so they offer a greater challenge. Moreover the objective of the environment is again to try to learn behaviors that can be generalized on several different games.
A contest on Retro has been set up at the exit of the environment. The different participating teams have to learn an agent on certain levels of the Sonic game and then their agent is tested on other new levels. The agent that goes the furthest in the level wins the competition.
The results showed that the most successful solutions were quite classical reinforcement learning approaches (especially the 2nd place one using an improved variant of DQN) which is quite encouraging as it was not very manual and problem specific solutions that won. On the other hand, the results obtained are quite far from the theoretical maximum score, which shows that the problem is still far from being solved.
The results of the contest showed that the agents are performing well on the levels used to learn but quite badly on new levels presenting new situations. Reinforcement learning algorithms therefore present generalization problems. Sonic levels being quite complex and labyrinthine, the task proposed by the Retro contest is really difficult. This is why OpenAI decided to develop an environment called CoinRun specifically dedicated to generalization. CoinRun presents a platform game environment where a character must reach a room at the other end of a level.
The levels in CoinRun are generally much simpler than those in Sonic, but agents are always tested on levels they haven’t seen during their training. The objective of this environment is therefore to be a good compromise between challenge from a research point of view and the difficulty of the task.
VizDoom
VizDoom, as its name indicates, is a platform that allows you to do reinforcement learning in the Doom game. The platform allows you to obtain several types of information about the game, such as the displayed image, the position and type of the different elements, depth information or information about the level seen from above. Of course, it also allows to rotate the game very quickly to speed up the learning process.
For the last three years, a competition has been held on the platform. It is the Visual Doom AI Competition (VDAIC). In this competition, agents who only have access to images of the game have to compete against each other in death matches. So far, the agents in this competition have not yet reached the level of humans.
Other quite innovative approaches have been developed on VizDoom, notably the World Models approach. This is a reinforcement learning approach where an agent builds a model of the world (like a kind of dream) and learns to act in this model of the dream world.
In all, the VizDoom platform has enabled the publication of more than 150 research articles.
TORCS
TORCS (The Open Racing Car Simulator) is a car racing simulation game. It is used as a game and as a research platform. It is a simulation so the agents who play must take into account many parameters such as pit stops or tire wear and temperature for example. The game has been used as a basis for many AI competitions, whether it is the creation of agents driving cars or agents automatically building new circuits. There is even a world championship on the game every year. It is a championship between agents where each team proposes upstream an AI that must compete during different races.
Racing environments that are very close to reality are interesting since they can be used as a basis for designing algorithms for autonomous cars. The fact that the game is royalty-free is important. Indeed, several autonomous car simulation research projects based on the GTA V game (including one in the OpenAI Universe environment) had to be completely stopped due to rights issues related to the editor of the Take-Two Interactive game. The TORCS environment is less photo-realistic than GTA V, but there is no risk that research projects based on it will be stopped for similar reasons.
Project Malmo
Another notable platform project is the Malmo project. The goal here is to develop AI algorithms capable of understanding a complex environment, interacting with the world, learning skills and applying them to new and difficult problems. The environment chosen to develop solutions to these problems is the Minecraft game. Minecraft is a sandbox game in which the player is much freer than in most other games. The action possibilities are very wide, ranging from very simple tasks like walking around looking for minerals to very complex tasks like building superstructures. This freedom makes Minecraft a good sandbox for algorithms, but it is quite likely that the Malmo project will allow for longer term advances in AI than other environments.
Finally, Unity has recently made available an environment called The Obstacle Tower and is also offering a contest (starting on February 11th) on this environment.
It is a 3-dimensional game in which the agent must climb a 100-story tower. Each floor corresponds to a level and the difficulty is increasing. The game can be played by humans, but it is intended for research. With a few minutes of training, humans who have tested the game usually manage to reach the 20th level. The environment is therefore difficult, and even for a human to reach the top of the tower seems to be a challenge.
Unity proposes this environment with the objective to be a benchmark on a difficult task to replace a previous difficult environment: the game Atari 2600 Montezuma’s Revenge.
Montezuma’s Revenge
If we look at the scores of the DQN algorithm on the different Atari 2600 games and linger on the background of the ranking, we notice a game with a score of 0% (which corresponds to the score obtained by playing randomly). This means that the DQN agent which is able to play better than professional players on about thirty games is not able to do better than random on this particular game: Montezuma’s Revenge. Why is that? What makes this game so different from others? Let’s take a little interest in this game.
This is the first level of Montezuma’s Revenge. It is a labyrinthine game where the player must advance by finding keys to open doors, while fighting enemies. To gain points in this game, you must either find a key or open a door (which requires a key). The picture shown here is the very first room in the game.
In order to get points in this room, the player must climb down the ladder, go to the right (the floor is a conveyor belt that goes to the left and projects into the void), jump on the rope, jump on the platform on the right, climb down the ladder, go to the left, jump over the moving skull, climb the ladder and finally jump on the key.
Reinforcement-based learning uses the rewards obtained to assess whether or not the actions taken are relevant. If there are no rewards, there is no way to improve. Reinforcement algorithms therefore usually start by playing randomly at the beginning to see which actions give rewards and which do not.
The problem with Montezuma’s Revenge is that by playing randomly, it is almost impossible to get the first key and therefore impossible to get a reward. The DQN algorithm therefore breaks its teeth on this game since the learning cannot even start. The many variants and improvements of the DQN have improved the results somewhat, but none of them give really satisfactory results. None of them manage to finish the first level. To give you an idea, there are 23 more such rooms to complete to finish the first level of the game.
Recently, DeepMind and OpenAI have proposed methods to play Montezuma’s Revenge. Their methods managed to complete the first level of the game, which is a much better result than what was possible until then. However, one cannot really consider that their approaches solved the game by pure reinforcement learning. Indeed, their methods are based on human demonstrations to assist learning.
DeepMind’s first method is based on Youtube videos of human players completing the level. From these videos, they build a reward that corresponds to reaching areas visited by the players. The algorithm therefore gets rewards much more frequently, which allows learning.
OpenAI’s approach uses the trajectories of a human player to initialize the agent differently. Indeed, if we initialize the agent right in front of the key, a classical algorithm will easily find that we have to jump on it to get points. Once this phase is learned, one can initialize the agent at the bottom of the scale under the key. Once again since this initialization, an agent will inevitably move up the ladder. Once at the top, he is in a situation he knows because he learned it just before, so he will jump to retrieve the key.
By continuing the learning process by moving the starting point further and further away, one can succeed in learning an agent capable of solving the first level. However, this requires specific work since it is necessary to define several initialization points that follow the trajectory of a human player but in the opposite direction.
These two approaches are interesting but they present a problem.
Using human demonstrations to learn a task is not a problem in itself (this is usually how humans learn new skills by the way) but it is in the context of Montezuma’s Revenge. Indeed, the game is deterministic, meaning that every time you play it, there will be the same rooms, the same enemies and nothing will be left to chance.
By using a human demonstration on gambling, the agent is not allowed to understand the demonstration and generalize it to new situations, he is just allowed to learn by heart the trajectories he must take to solve the game. What is learned in the end is not how to play Montezuma’s Revenge, but rather how to execute a specific sequence of actions to finish the game. This was clearly not the original goal, as the aim is to create the most general reinforcement learning methods possible.
RND approach
Very recently (end of October 2018), OpenAI proposed an algorithm capable of sometimes completing the first level without relying on a human demonstration. Their approach, called RND (Random Network Distillation), encourages the agent to explore his environment by kindling his curiosity. Thus, they propose an additional reward system that will encourage the agent to visit areas he has not yet seen. By exploring the different areas of the game in a more methodical way, he will come across the elements that give the real rewards, such as keys or doors, and thus learning will be facilitated.
To find the areas not visited, the agent relies on his own predictions of the future state. Indeed, if the agent is able to predict what will happen after an action, it is because he is in a known area. On the contrary, if he cannot predict what will happen, it is because he has never had to travel through the zone. Giving the agent a reward when he can’t predict the future is an incentive for him to always go to new areas. By combining this exploratory approach with a classic reinforcement learning algorithm, the game could be solved.
Montezuma’s Revenge has long shown the limits of our learning algorithms. It has long been believed that in order to solve the game well, agents should have a better understanding of the different concepts of the game, such as what a key is, what a door is, the fact that a key opens a door, and so on.
In the end, by finding a clever way to explore the level and with enough time to learn, the game was solved. So it seems that the various difficult problems that seem to require human abilities (such as understanding concepts, reasoning, etc.) to be solved, can often in the end be solved in a completely different way by the algorithms.
Unity’s environment, The Obstacle Tower is designed to be a kind of successor to Montezuma’s Revenge. The future will tell us if the environment is really interesting in terms of AI research.
The main approaches of DeepMind and OpenAI on video games
We are now going to focus on three approaches with really impressive results. These methods are very recent, were developed in 2018 and 2019, and have been much talked about in the media. They are developed by DeepMind and OpenAI which have means in terms of computing power far superior to academic research laboratories. This allows these teams to focus on topics both as research problems, but also as engineering problems. Academic laboratories are generally interested in more restricted and/or fundamental problems mainly due to lack of means.
The games concerned by these approaches are Quake III, Dota 2 and Starcraft 2.
Quake III
The first approach is DeepMind’s work on the game Quake III. In practice, it is a home-made clone of Quake III called DeepMind Lab. The game mode they worked on is called Capture The Flag (CTF). It’s a mode where two teams compete against each other to try to steal the flag of the opposing side and bring it back to their own flag. The team that has managed to bring back the opposing flag the most times to its own camp in 5 minutes wins. This short video from Deepmind explains the principle. The rules are simple, but the dynamics of this mode of play are complex. To be successful, it is necessary to implement strategies, tactics and especially to play as a team.
Deepmind has succeeded in developing agents capable of playing as well as humans in this mode of play. Interestingly, their agents manage to work in teams with other agents, but also with humans.
The problem posed by this game is called multi-agent learning. Indeed, several agents must learn to act independently while learning to interact and cooperate with other agents. This is a difficult task since, as agents evolve during their learning, the environment they face is constantly changing. Moreover, in order for agents to really learn to play in CTF mode rather than memorize the layout of the environment by rote, they play in procedurally generated environments (and yes, procedural generation can also be used to create a better learning environment!).
As with many of the other approaches presented in this post, agents have access to the same information as human players, i.e. simply the information that is displayed on the screen. The CTF rules are never made explicit; agents must understand them on their own. Moreover, the different agents have no means to communicate with each other, so they must act and learn independently.
Agents architecture
As for the DQN algorithm, the heart of the agent will be a neural network. Here everything is just a little more complex. Agents must be able to perform on several time scales: they must be able to react quickly when an enemy appears or the flag is stolen for example, and they must also be able to act on the longer term to implement a strategy. In general, when we have these kinds of problems, we are interested in what is called hierarchical reinforcement learning. Thus, in order to be able to propose such behavior, agents are based on a hierarchical recurrent network with two levels of temporality. Recurrent networks are the networks that are classically used to process sequential data (such as text). The best known are the LSTMs. The agents are thus provided with a hierarchy of two LSTMs (in practice the networks used are a little more complex than LSTMs but the idea remains the same). The first one sees all the states and acts at all stages while the second one only sees one state from time to time. The two levels can therefore process information in different ways. In addition, the agents are equipped with a memory system that allows them to store the information they consider important so that they can reuse it when the time comes.
Upstream of this system is a classic convolutional network that is simply there to understand the images and extract important information (let’s not forget that the agents play with the images on the screen as the only information). As for the DQN, a state is a succession of 4 images. The game runs at 60 frames per second, so that makes 15 learning steps per second.
The different actions
At the exit of the LSTMs hierarchy, an action for the agent is chosen. In the Atari environment, there were 17 possible actions. Here the game is much more complicated, the possible actions are continuous rather than discrete (you can move the viewfinder anywhere on the screen) and they are combinable (you can for example move forward, jump, move the viewfinder and shoot at the same time). To greatly simplify this, the actions have been limited mainly at the viewfinder level. Thus, it becomes only possible for the agent to move the viewfinder by a certain vertical and/or horizontal value in relation to the position at the previous step (for example, only horizontal movements of the viewfinder with an angle of 10 degrees or 60 degrees are allowed). Thanks to this simplification, the number of possible actions at each step is 540.
The hierarchy of LSTMs thus chooses one of these actions according to the images it receives and information from the past.
The reward
So agents have a way to choose actions according to states. As in any reinforcement learning algorithm to learn how to choose these actions in a relevant way we use the reward. Since the goal is to teach agents to win at CTF, the reward is positive if the agent’s team wins the game, negative if it loses and null if it is tied. The problem is that this reward is very rare, indeed thousands of actions can be done before the end of a game. The problem is the same as in Montezuma’s Revenge, where the agent is unable to make the link between actions and rewards. We must therefore find a way to provide agents with rewards more frequently. Quake III contains a point system for each player that is independent of the team’s score (which is based only on flag captures). Players earn points by hitting enemy players, capturing a flag, bringing their own flag back to their base etc.
Deepmind offers a system where the agent creates his own internal reward system based on the Quake III point system. With this system, rewards become much more frequent and learning becomes possible.
Learning algorithm
The reinforcement algorithm used for learning is the UNREAL algorithm (also developed by DeepMind) which is an enhancement of the A3C (Asynchronous Advantage Actor-Critic) algorithm with unsupervised tasks to accelerate learning. This DeepMind blog post gives more details about this method. The A3C algorithm is itself an improvement of the DQN algorithm. These algorithms are visible on the figure presenting the main reinforcement algorithms derived from the DQN presented earlier.
Learning
We saw how an agent was represented, its reward system and the reinforcement algorithm used. From now on, data is needed to do the learning. A possible solution to learn this type of agent is to make it play against itself. However, this approach can be quite unstable and does not bring much variety. Indeed, the agent will continuously play against a version of himself that will become stronger and stronger over time, but will probably have a fairly similar overall behavior in the long run. In order to bring diversity to gambling tactics and strategies, it is not one agent but a whole population of different agents that is trained in parallel. The different agents play against each other, thus stabilizing learning. This population of agents evolves over time thanks to a genetic algorithm called PBT. This algorithm replaces the least performing agents with mutated versions of the most performing agents. Thus, the whole population improves over time. It is also this algorithm that adapts the internal reward system of each agent. Thus, the most relevant goals for one agent may not be the same for another agent.
The learning of the agents required 450,000 parts. At the end of this phase they are much better than humans. After just over 100,000 parts the agent population was playing at the level of an average human.
The system proposed by DeepMind to play Capture The Flag is therefore a complex two-level learning approach mixing genetic algorithm and reinforcement learning. Through this system, agents discover how to balance their individual objectives (their internal reward system) with the team objective (the final reward, i.e. win or lose the game).
It is interesting to note that different strategic and teamwork behaviors like these above were discovered and understood during the learning process. Once trained, agents tend to cooperate better with their teammates than human players.
Dota 2
More or less at the same time as DeepMind’s solution for playing Quake III CTF, OpenAI has finished developing its approach for playing Dota 2 in 5v5. During the spring and summer of 2018, they continually improved and completed their approach, offering increasingly efficient agents until the culmination at the end of August: two matches against teams of professional players at The International 2018, the world’s largest Dota 2 competition.
Dota 2 is a Moba type game (Multiplayer online battle arena). It is a type of game where two teams of usually 5 players each compete against each other in order to destroy the base of the opposing team. Each player controls a single character, a hero with special abilities and powers. Over the course of the game, the heroes evolve, becoming more and more powerful and unlocking new powers. Many heroes exist and each player starts by choosing his own from the different possibilities, so the strategic aspect starts even before the game begins. Indeed, some heroes allow to counter other heroes and so on. As the game is played with 5 players against 5 players, the possibilities are enormous.
Game complexity
When comparing Dota2 with the CTF mode of Quake III, the complexity is much higher. Indeed, where the number of possible actions at each instant had been reduced to 540 on Quake III, here the number of possible actions is 170000 (even if in practice at each instant, not all actions are executable, the order of magnitude is rather a thousand actions).
As for Quake III, this is a game where the information is imperfect (unlike Go) since only areas close to the team are visible. So we do not know at every moment what the opponent is doing. Moreover, the game is played in real time and a game lasts on average 45 minutes (compared to 5 minutes for Quake III). And the last point, Dota 2 is a highly strategic game, to win you have to be able to coordinate between the different members of the team and plan your actions over the long term. All of these factors make Dota 2 a very complex game for an AI, so it’s a good challenge to improve research in the field.
OpenAI iterative approach
Faced with the complexity of the task, OpenAI decided to take an iterative approach, offering an agent for a very simplified and restricted version of the game, then gradually removing the restrictions to finally reach the full game.
Thus, they started by proposing an agent for the 1v1 gaming mode. This is a mode where each team is composed of only one player, which greatly reduces the possibilities of the game. It is a less popular game mode than 5v5 but there are still 1v1 competitions, so the mode is played by humans.
At The International 2017 competition, their agent beat a professional 1v1 player on stage in front of a large audience. In the days before, their agent had also beaten other professional players including the best in the world. They described the agent as unbeatable.
At that time, OpenAI had not yet detailed its approach (wanting to reveal the information only once the agent was ready for the 5v5 game). The only information available was that the agent is learned entirely by playing against himself. The approach therefore seems similar to that for Quake III.
In the end, it turned out that the agent was not unbeatable. All professional players obviously wanted to compete with the AI and loopholes were found. Indeed, the agent was extremely strong against an opponent playing in a conventional way, but he quickly became confused if the opponent played in a completely abnormal way. Thus, with the right (unconventional) strategy all professional players were able to beat this version of the agent.
OpenAI was able to correct these problems quickly by considering these strategies during the learning phase of the agent against himself and decided to leave the agent in 1v1 and start working on the 5v5 version. The main reason is that in 5v5, the number of unexpected strategies like the one found by the players is necessarily much higher. Learning these strategies by implementing them one by one during the learning phase is therefore not a viable solution. What is needed is an agent capable of learning how to react on his own to these unconventional situations.
OpenAI Five
OpenAI has therefore continued its iterative approach to AI development by removing game restrictions as they became successful. Each restriction removed increases the complexity of the game and comes closer to the official rules of major tournaments. The rise of their 5v5 agent – named OpenAI Five – is quite impressive. Indeed, it is only at the end of April 2018 that they managed to beat a team of bots whose rules are manual. This kind of bot is very far from the level of good human players. So they were still quite far from the goal at that time. And yet, in June 2018, their agent beat a team of semi-professional players. And finally in August the matches against two teams of professional players took place. OpenAI Five lost both times, but the matches were very close. So their agents are very close to the level of the best professional teams. The matches in August were also the first with the official rules. Indeed, those in June were still played on a version of the game with restricted rules.
So let’s see how they managed this impressive progression. OpenAI has not yet provided all the details of its implementation, but several articles on their blog describe the approach used quite precisely.
Data
OpenAI Five uses the API provided by Valve the developer of Dota2. Thus, at all times, all the information visible on the screen for a human player is accessible to the agents. This is a big difference from the solution for Quake III, which looked at and analyzed the images on the screen. Here, there is no image recognition step to get the information. The agents have access to all the information at once (in practice this represents 20,000 values in each state), unlike humans who can’t look at everything at once. There may be a debate here about whether this is fair or not compared to humans, but learning with the game images to analyze would have required thousands of additional GPUs.
Like the Quake III agent, OpenAI Five observes the game every 4 images (because a state is a sequence of 4 images). Dota 2 runs at 30 frames per second so at most the agent could perform 7.5 actions per second or 450 actions per minute. In practice, an agent performs on average between 150 and 170 actions per minute which is within the range of a human player. However, the average reaction time of an agent is 80 ms which is faster than the reaction time of a human.
Agents architecture
Each of the OpenAI Five team heroes is controlled by an independent agent, just like a team of humans. So it is not a super agent controlling all the heroes at the same time. Thus, each agent contains a model that is initially the same for all, but can learn differently from the others depending on the experiences they have had during training. Agent models are neural networks. At each stage, they receive data provided by the API.
The networks are first of all made up of layers of classical neurons whose objective is to represent the information in a relevant way so that the heart of the agents can make decisions. The 20,000 values provided by the API are therefore aggregated and transformed by these layers in order to keep only what is relevant for the agent.
The cores of the agents that receive this transformed data are simple recurrent networks of the LSTM type. The LSTM analyzes the data sequence and contextualizes the present through past events. Thanks to the data contextualized by the LSTM, different classification “heads” estimate the actions to be performed. Thus, we can see that one head has the objective to choose the most relevant action, another one has to estimate the X coordinates of the action execution, another one has to estimate the Y coordinates and so on.
The LTSM contextualizes the data sequence and the 8 classification heads make the decision of what to do. The complete unretouched diagram can be found here. In this article, a dynamic interface is used to make the link between what is displayed on the screen and the different heads.
Some choices in the modeling (especially at the action head level) were made by analyzing the agents’ behaviors during games. If a certain behavior did not correspond to what was expected, the network architecture was modified to facilitate the learning of this behavior.
An interesting point, if we compare this solution with the one for Quake III, we can see that there is no hierarchy of LSTM at different temporalities to manage short and long term actions. It seems that with a single LSTM, OpenAI Five agents can manage long-term planning. OpenAI researchers themselves explain that they thought this was impossible with traditional approaches. For example, the hierarchical reinforcement learning (first described here) used in Quake III seemed to them to be a necessity. But this was clearly not the case.
Learning algorithm
The reinforcement learning algorithm used is called Proximal Policy Optimization (PPO). It is not a variant of DQN like all the other algorithms we have seen so far. The difference is that here it is not the Q-Value that is optimized but directly the policy of choice of actions. The PPO algorithm was proposed by OpenAI in 2017 and has since demonstrated good performances, especially during the Retro contest on the game Sonic or on Montezuma’s Revenge.
For any reinforcement algorithm, the objective is to maximize future rewards. In general, one tries to maximize the sum of future rewards weighted by decreasing values. The idea is to say that all future rewards are important, but that those in the near future are more important than those in the distant future because the distant future is too uncertain.
In general, we often take values that decrease exponentially over 100 values, so at each point in time we consider the rewards of the next 100 steps. Depending on the time between steps it can be a more or less long time, but usually it does not exceed a few seconds.
At the beginning of learning OpenAI Five, the number of future rewards considered by the agent is quite small, but as the number of rewards increases, the number increases until all the rewards are considered.
Thus, once learned Dota Five tries at every moment to optimize the rewards that it considers to be obtained until the end of the game, which allows for the implementation of strategies on the scale of an entire game. This is probably the first time reinforcement learning over such a long period of time has worked.
Learning
So how can it work if the approach used is a classical and well-known algorithm? OpenAI discusses two reasons for this success: the very large scale learning and the presence of good means of exploration.
The infrastructure to do the learning is impressive: 256 GPUs per agent and 128,000 CPUs. With this, it is possible for agents to play Dota every day the equivalent of 180 years for a human.
The agents learn to play the entire game by playing against themselves. During the first few games, the heroes do a bit of everything, wandering aimlessly around the map. Then, as the game progresses, they begin to exhibit behaviors closer to those of humans. To avoid what they call “strategy collapse”, agents play 80% of the games against themselves and 20% against versions of themselves from the past. This is a problem similar to the DQN’s deadly triad. By taking versions from the past, we decrease the risk of having overly correlated learning data.
With this learning approach, OpenAI Five was able to become good enough to beat a bot with manual rules (in March 2017) but it was getting confused in front of humans. They were playing in too many different ways, always presenting new situations not seen during the learning process. As we had seen with Quake III, playing against oneself does not bring enough variety in situations, even when playing against versions from the past.
To better explore during the learning process, i.e. to test new game configurations to see the results of different actions, OpenAI decided to add randomness to the games. Thus, in some games, the properties of the different units such as life, speed or starting level have been randomly modified. Thus, the agents found themselves in much more varied situations than by simply playing normal games.
This forced randomness allowed the agents to reach the level of humans for the first time. By learning longer and with even more randomness, the level of Dota Five only increased.
The reward
As with Quake III, using only one reward at the end of the game is not enough to train agents properly. A more frequent reward was therefore built manually by OpenAI. It includes the different indicators that humans consider to know the state of a game, i.e. the number of heroes killed, the number of dead, the number of NPCs killed etc… This reward is internal to each agent, but there is also an overall reward linked to the team that roughly corresponds to winning or losing the game.
The agents have no explicit way to communicate with each other. In order to manage teamwork during the learning process, a parameter is used to define the importance of agent specific rewards compared to team related rewards. At the beginning of learning, agents are only interested in their own rewards. This allows agents to learn the important rules and principles of the game. Then, as more and more importance is placed on team rewards, agents develop strategies together. This system is very effective since the teamwork of the different agents is what impressed the experts watching Dota Five play the most.
The last manual composants
The strategic choices in terms of combinations of objects and heroes’ skills (so-called hero builds) are for the moment defined manually. They have been coded upstream and at each game they are chosen randomly. It is likely that OpenAI will try to remove these manual steps in the future to automatically learn the most appropriate builds for each situation. There are still a few other features that are hard defined in their approach. Maybe next summer at The International 2019, Dota Five will be a fully automatic agent with all parameters learned automatically. In any case, if OpenAI has continued to work on this agent and they organize a match against a professional team during this event, everything leads us to believe that this time the agent will win over the humans.
Starcraft II
Starcraft II is a real-time strategy (RTS) game in which two players compete against each other by developing a base to obtain resources that allow them to build different types of units to attack the opponent. Starcraft II has long been regarded as a great challenge for AI research or the ultimate challenge in video games. Dota players will probably say the opposite, but either way the two games are very complex and probably present a fairly similar challenge for an AI.
Indeed, Starcraft 2 is also a game where the information is imperfect since only areas close to the player’s units are visible. The game is played in real time and the number of possible actions at each moment is huge. There are no winning strategies in Starcraft II. Just like in a rock-paper-scissors game, there will always be one approach to counter another.
Moreover, to play well, you need to be able to demonstrate strategy on two levels of hierarchy:
The micro-management, that is to say to manage in an intelligent, fast and precise way the various units that we have at our disposal during the fights.
Macro-management, i.e. managing the overall strategy of the game by building the right units, deciding when to attack, how to manage your resources, etc…
In order to play Starcraft II well, you must be able to foresee in the long term since decisions made at a given moment can have repercussions much later in the game, but you must also be able to make decisions very quickly and act precisely. Seeing the professional players play is quite impressive.
Research on Starcraft
Although there have been many successes in AI in video games as we have seen (Atari, Quake III, Dota2,…), until now the different algorithms could not handle the complexity of Starcraft. No AI-based agent could compete with professional gamers. This is not to say that there was no research on the game. Several competitions took place, sometimes restricting the task to a sub-part of the complete game.
In 2018 at the AIIDE Starcraft AI competition it was an agent with manual rules that won the competition (ahead of a Facebook agent learned by reinforcement).
In 2016 and 2017 Blizzard and DeepMind worked together to provide an environment called PySc2 with different tools to simplify algorithm searching and learning on Starcraft II.
Thanks to this environment, some recent approaches (like this one or this one) are starting to offer agents with learning that can beat the best Starcraft II bots (who cheat by having more resources or by seeing the whole game for example) but not yet at the human level.
AlphaStar
Still thanks to PySc2, DeepMind was able to develop AlphaStar, an AI capable of beating professional players on the full game (with some restrictions: the game is currently limited to a single race and a single map).
AlphaStar has played so far against two professional players and has so far (January 2019) recorded ten victories for one defeat. The results are therefore far superior to previous approaches.
Approach used
All the details of AlphaStar are not yet available since DeepMind has not yet provided the research paper describing the solution in detail. However, a blog article gives us the main information on how the agent works.
The method seems to be an improvement of the one used to play CTF mode on quake III. Indeed, we find the idea of learning at two levels: an agent population in which each agent does its own learning by reinforcement but which at the global level is managed by a genetic algorithm that keeps only the best agents to improve as the level of the whole population increases.
The different learning phases
One important difference is that Starcraft II is much more complex than CTF mode, so it seems almost impossible to learn the basic gameplay by reinforcement alone. Indeed, at the beginning if agents don’t know how to play at all, they may play against each other, but they won’t learn anything. This is why the initial learning of the agents is done in a supervised way through what is called Imitation Learning. Similar to the approaches discussed for Montezuma’s Revenge, the agents have access to a large number of human player games and they learn the basics of the game from these games. It is only after this phase that the agents begin to play against each other in what DeepMind has called the AlphaStar League. In this league, the agent population plays a very large number of games against each other to improve.
For the five-set matches against professional players, the top five agents in the League have been selected. The genetic algorithm that manages the population forces a certain variety among the agents, so the five agents chosen by DeepMind played in different ways, which surprised and disturbed the professional players.
For the first game against a professional player, the agents trained for 7 full days. The PySc2 environment allows to speed up the game and to launch many instances in parallel. The 7 days thus correspond to 200 years of gameplay for the agents. For the second game, the agents had 7 more days of training. For each agent, 16 TPUs were used during the training, which represents quite a lot of computing power. However, once the agent has been trained, playing the game only requires a classic machine with a GPU.
Learning algorithm
The reinforcement algorithm used is IMPALA (not to be confused with Apache Impala, the SQL query engine on Hadoop present in Saagie.
It is an enhancement of A3C optimized for massive parallelization. In addition, many learning tricks are used such as self-imitation learning which encourages the agent to repeat more often the good deeds he may have done in the past.
Agents architecture
For Quake III’s CTF mode, the core of the agents was an architecture with two layers of LSTMs. Here, the agent is based on a Transformer combined with an LSTM (in addition to other recent approaches such as pointer networks).
The Transformer is a neural network model that has been much talked about in the world of language processing (NLP). In fact, it is the architecture on which many state of the art NLP solutions are based (such as machine translation for example). This architecture is designed to manage data in sequential forms. In general, it is used on sentences but here the actions to be performed in the game are also sequential data. It is a rather interesting choice because the Transformer is known to have difficulties to manage very long sequences. However, the sequences of actions to be performed in a game like Starcraft II are much longer than any sequence of words in a sentence. DeepMind has probably found an approach to counter this phenomenon, perhaps creating a hierarchy of sequences or limiting sequences temporally for example. We’ll probably have the details once the research paper is published.
Pointer networks are a variant of seq2seq architectures (the state of the art in translation before the arrival of the Transformer) whose objective is to sort a sequence in a certain way at the input. For example, these networks can be used to solve the problem of the business traveler by indicating in which order to travel. DeepMind does not yet detail in which framework these networks are used, but it could be used to manage the order in which actions must be executed. For example in a battle, choose which units to attack first, which ones to protect, etc…
Agent prediction
The agent’s architecture predicts at each moment of the game the sequence of actions expected until the end of the game. Obviously, this action sequence is continuously updated and modified according to what the opponent is actually doing in the game.
The Transformer is what is called an attention model, i.e. it can somehow focus on only certain parts of the information it considers important. You can see on the minicard on the right that the agent at each moment focuses on only one area and that in one minute he changes his attention zone about 30 times (which is similar to the behavior of human professional players).
In the interface proposed by Deepmind, we can see that at each instant, the model considers if it has to build new buildings or new units and, above all, it estimates if it is winning or losing the game. This indicator of its state in the game allows it to act accordingly. For example, if he feels that he is losing, he may retreat to try to better defend himself in his base.
One of the important points during games against professional players is that the agent always seemed to be able to estimate when he could attack or when, on the contrary, it was better not to take any risks. The model therefore seems to be able to predict at every moment if he is winning the game, but on a smaller scale, he also seems to be able to predict whether he can win a skirmish or not.
Architecture relevance
DeepMind believes that their architecture can also be used in other tasks where it is important to model sequences over the long term (such as machine translation for example).
One of the major advances about AlphaStar (and OpenAI Five) and it seems that these models continue to learn and improve as more computing power is added. This was clearly not the case with traditional Machine Learning where one often reached a level of performance that was difficult to surpass even by adding more data. This means that the architectures chosen are relevant and allow the different problems of these games to be properly encoded.
About restrictions
Speaking of game restrictions, being able to play with all three races adds a lot to the complexity of the game. However, the proposed architecture seems to be able to learn this with sufficient time and computing power especially by starting learning by imitating human parts. The other big restriction is related to the playing cards. Currently, AlphaStar is learned on only one card whereas the game proposes much more and renews its panel regularly. There are some very aggressive strategies that are viable on only one card for example, so the agent will need to be able to adapt to these specific strategies and generalize a behavior. Once again, given the results already achieved, this seems possible with the current architecture.
Agent dexterity
An important point to consider when talking about AI playing Starcraft II is the “dexterity” of the agent. Indeed, Starcraft being a game where you have to control many units at the same time, a human will never be able to compete with an agent that can perform several thousand actions per second. DeepMind has therefore deliberately slowed down its agents so that it is fairer to human players and therefore that it is the strategies proposed by the agent that make the difference and not its perfect execution.
Above you can see the average number of actions per minute (APM) of the agent and the professional players. The agent seems to perform fewer actions on average. The reaction time must also be taken into consideration. Indeed, an agent who reacts instantaneously to different situations will also have a considerable advantage over a human even if he does not perform many actions. We can see on the right the reaction time of the agent which has been reduced to the level of a human.
This graph presents the theory. In practice, there are still a lot of questions about the actual dexterity of AlphaStar. It is clear that the AI has at times shown non-human dexterity during games.
Indeed, the agent was initially limited in terms of APM. With this limitation, the agent obviously could not learn to micro-manage his units during confrontations. To facilitate learning, some peaks of APM were allowed. For example, during a five-second AlphaStar sequence with the ability to go up to 600 APMs, for fifteen seconds it can go up to 400 APMs etc.. Thanks to this, AlphaStar was able to learn how to micro-manage during confrontations.
These peak action values are based on the APMs of professional players. The problem is that human players don’t have perfect accuracy so to perform a single action, they usually perform several clicks to make sure they click at least once in the right place. This is called spam cliking. So not all actions per minute of a human are actual actions. The TLO action per minute curve (in yellow) is the extreme example, probably only about one tenth of these actions are not spam clicking. A human’s effective actions per minute (EPM) are therefore a better way to play AlphaStar, which does little or no unnecessary actions. Thus, it would probably have been better to use human EPM values to calculate peak thresholds. Currently AlphaStar during confrontations has inhuman speed and accuracy.
As a result, AlphaStar’s victories become somewhat questionable. Did the agent really win because he implemented good strategies or simply because he controlled his units better than professional players? Since each game was played by a different agent, did AlphaStar really adapt to the actions of the opponent or did he just have a well-honed strategy in mind from the beginning that he applied well enough to win most games?
The goal of DeepMind is to beat professional players in Starcraft II, but more importantly to do it “well”. That is to say that the AI must win without the feeling that it is cheating or that the game is not fair. For now, it seems that their solution hasn’t reached this stage yet, but they are clearly on the right track. Their solution gives the impression that further and longer learning will solve most of the problems and questions about the current version. The future will tell us if this is indeed the case.
To conclude
Research is evolving very quickly in the field of video games and the second half of 2018 has been very important with the development of several very impressive systems.
One of the points that the end of the year showed us is that playing an agent against itself (self-play) gives very good results. This is obviously the best (or easiest) way to create large volumes of learning data. This approach, complemented by a good neural network architecture for an agent, is sufficient to solve many tasks if the domain is relatively small (as for Quake III). On the other hand, we observe that when complexity increases (as for Dota 2 and Starcraft 2) it is no longer sufficient and other complementary approaches must be found.
For Dota2, the approach has been to restrict the game by simplifying the rules and manually coding the most difficult concepts, and then during the learning process to progressively remove the restrictions and manual rules. The exploration of the different possibilities of the game was managed mainly by adding randomness in the games during the learning process.
For Starcraft 2, the approach was to use what is called imitation learning, i.e. copying human behavior to learn the basic rules, then learning how to play better in self-play. The exploration was here managed by a high level genetic algorithm and the AlphaStar League, which allows agents to regularly find new strategies.
The AlphaStar bug
During the only live game of the clash between AlphaStar and MaNa (one of the professional players), MaNa won the match against the AI by exploiting a weakness of the AI.
MaNa managed to make AlphaStar run in circles for several minutes thanks to a single unit (a Warp Prism), whereas the simple creation of the unit against would have solved the problem (It is visible in this video of the event around 2h39 minutes). Thanks to this little game MaNa was able to win the game.
Any human player (even of very low level) would have created the unit able to destroy the Warp Prism which would have immediately stopped MaNa’s strategy. Only AlphaStar did not. From his reactions, one could see that the agent considered the Warp Prism as important, he was monitoring it, but he didn’t have the obvious reaction that any human player would have had. One of the commentators described this exchange as, “This is what I’m used to seeing when a human plays against an AI”. The human detects a flaw in the AI’s behavior and exploits it to the fullest, the AI being unable to react.
AlphaStar’s developers consider that one of the great challenges in AI is the large number of possibilities a system has to go wrong. Indeed, traditional AI is easy to exploit since it has many visible flaws. The complex learning systems thought by OpenAI and DeepMind allow to limit a lot these flaws by finding the most reliable approaches and strategies, but the live match against MaNa proved us that there are always flaws. It seems that during the agent’s training his opponents did not use this Warp Prism-based strategy. By increasing the duration of the AlphaStar Training League and thus the learning time, it is likely that this kind of loophole will disappear.
AlphaStar does not understand the game at all like humans do, and concepts that are obvious to us are unknown to it. Thus, if during the training, the agent has never had to counter a Warp Prism with such a strategy, he will not be able to understand how to counter this strategy, whereas a human will probably have the intuition even without knowing the particular game. Indeed, humans are able to take advantage of their past experiences, aggregate them as concepts, and generalize them to new problems, which is something AI does not yet do well.
Concepts on Montezuma’s Revenge
When a person first sees the first level of Montezuma’s Revenge, even though they may not necessarily know exactly what to do, some concepts will be familiar to them. For example, the key seems to be an important object. It is likely that it will open a door. The skull seems to be something to avoid. Ladders are used to go up and down. Falling off a ladder is a high risk of death for the character etc. Just by observing this, the person will be able to plan a sequence of actions to get out of the room. These general concepts are applicable to almost all platform games of this style.
It is this kind of high-level reasoning based on an aggregation of concepts that seem to be the basis of human intelligence and therefore seem important to implement in learning systems.
The problem is that this reasoning and these skills are very difficult to put into algorithmic forms since they are not already well understood in humans. When we learn new concepts, as humans we usually use general external knowledge that we relate to these concepts. Thus, if we do not have access to our prior knowledge (innate or learned), games that we consider very simple become suddenly much more complex.
This is what a team of researchers from Berkeley wanted to study in this article.
They took a classic platform game and successively removed the visual concepts we use as humans to play this kind of game. Thus, this interactive page allows us to play the game in a version where all our previous knowledge is removed. The game is relatively unplayable. We can consider that a reinforcement learning algorithm is put in a similar situation at the beginning of a learning process. This may partly explain the lack of efficiency of these algorithms compared to humans in terms of learning (for example the 200 years of Starcraft to present the level of a professional player). Since algorithms lack the knowledge of the basics that we humans have, the first step in learning is to create this knowledge from scratch through the rewards obtained in response to different actions, which necessarily takes time.
A reinforcement learning algorithm (A3C) has been learned on this version of the game and it turns out that the algorithm takes as much time as on the initial game, which does not pose any particular problem to it, unlike us humans.
Concepts learning
So the goal is to find out how to make an agent learn this basic knowledge to enable him to “understand” the game, and how to make this knowledge apply to all games of this style and not just one.
The two ways of approaching this problem proposed by OpenAI and DeepMind, namely manual definition of concepts and learning by imitation, seem to solve the problem on the surface, but probably not enough to be able to properly generalize the concepts to other domains. There is therefore still some research work to be done to reach these objectives.
On the other hand, if we look at the advances in the game of Go, the very first version of the AlphaGo agent had a very similar learning curve to AlphaStar. Indeed, the agent was initialized with Imitation Learning and then the rest of the learning was done in self-play. This version was able to beat the best players in the world. However, DeepMind while continuing to work on the subject released a new version called AlphaGo Zero learned entirely in self-play. This version beat AlpaGo 100 games to zero. This showed that mimicking the human way of playing limited the algorithm in practice. Humans are obviously not that good at playing Go and the biases induced by copying their way of playing were not optimal for playing.
So, trying to instill human notions and concepts to agents and relying on our way of thinking to invent learning algorithms may not be the best approach.
It will be interesting to see if AlphaStar can be learned in the same way as Alphago Zero and also show superhuman performance in terms of strategy on Starcraft II.




