
First of all, it is important to know the history of Deep Learning, before discovering in two other parts how it works and, finally, its future prospects. Deep Learning is a relatively new terminology, unlike deep neural networks, which it refers to. The theory behind Deep Learning is therefore not recent, and even if new algorithmic methods have made it possible to reveal its full potential, its foundations date back to the middle of the 20th century.
The origins of Deep Learning
Artificial neuron (or formal neuron)
The idea of an artificial neuron, which is a very simplified mathematical abstraction of a neuron in the human brain, was formalized in the mid-1940s.
An artificial neuron is a mathematical tool that receives input values, weights these values with weights (or coefficients) and returns an output value, based on the sum of the weighted values. The value returned by the neuron is then called an activation. It is therefore a mathematical abstraction of a biological neuron which, in a very simplified way, receives electrical signals through its dendrites, transforms them in its synapses and activates or not depending on the signals received. If a biological neuron activates, it means that it transmits the electrical signal received to other neurons.
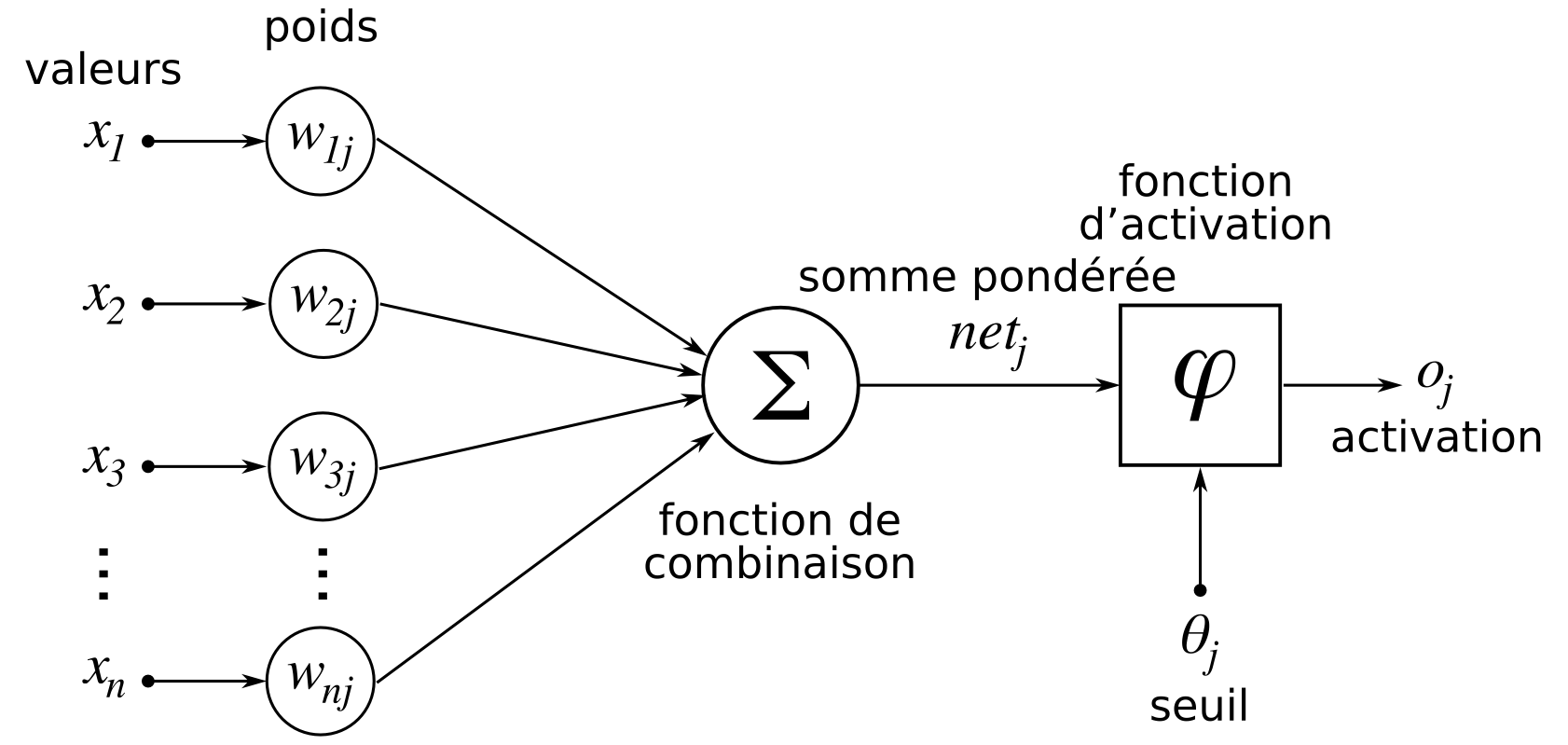
A few years later, the idea of the artificial neuron (or formal neuron) was applied to a binary classification problem: the resulting algorithm is called the perceptron.
The activation of a neuron within a perceptron thus corresponds to one of the two classes we are trying to predict. The learning of a perceptron corresponds to finding the weights (or coefficients) of the neuron that allow to return the desired value and thus the right class. Just as the human brain is made up of a large number of interconnected neurons, we quickly realized that using several neurons gives better results. This led to perceptrons with a layer of neurons instead of a single neuron.
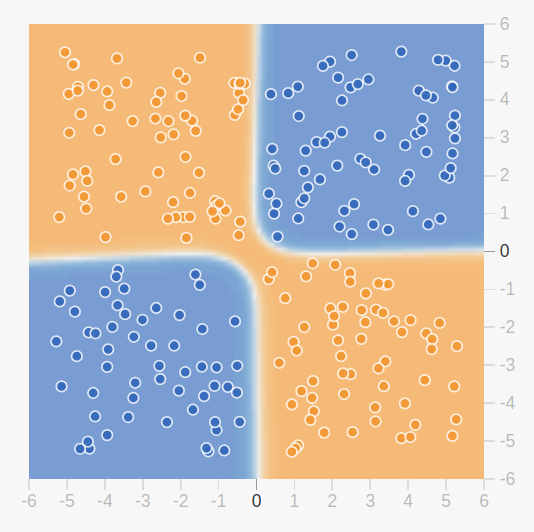
At the time, perceptrons were able to solve simple binary classification problems but were limited by their inability to solve certain types of problems (such as the XOR function below).
Multi-layers neuron network
To solve this problem, it is necessary to move from a perceptron with one layer of neurons to a neural network with several layers; the multi-layer perceptron. However, adding layers to a perceptron makes it more difficult to learn the perceptron.
The method for learning this type of neural network, called gradient backpropagation, was first successfully applied to a neural network in the mid-1980s. As a reminder, learning a perceptron consists in finding the values of the weights of the neurons. The learning of a multi-layer perceptron thus corresponds to finding the values of the weights of all the neurons making up the network, which can potentially make a very large number of weights to be found.
This method has allowed neural networks to be really useful for the first time by solving important problems such as the optical recognition of numbers on cheques for example.
However, it became clear relatively quickly that, to solve more complex problems, it was necessary to multiply the layers in the neural networks. The problem is that this increasing complexity of neural networks leads to two difficulties:
The more layers the network has (the deeper it is), the more computing power is needed to be able to learn and use it.
The deeper the network is, the less the learning algorithm (gradient backpropagation) works properly.
These two difficulties have limited the acceptance and use of neural networks for nearly two decades. Indeed, it was common to have to use networks for which one could not learn properly.
The success in 2000's
The method received renewed interest in the mid-2000s when it was proven that it was possible to prelearn deep neural networks using unsupervised methods.
This pre-training reduced the learning difficulties previously experienced in deep networks. It was this discovery that allowed research in the field to be somewhat revived, as a solution to the other problem was beginning to appear: the use of graphic cards to do the calculations.
Graphics cards are components of computers that manage the display of information on the screen. These components are designed to be able to perform a large number of simple mathematical calculations in parallel. However, it turns out that learning and using a neural network requires a very large number of very simple mathematical calculations, and that these can be largely parallelized. Graphics cards (or GPUs) are therefore much more suitable than conventional processors for learning and using neural networks.
ImageNet
However, the event that really triggered the revival of neural networks and the emergence of the term Deep Learning was the ImageNet Image Recognition and Classification Contest of 2012. This contest, held annually, challenges research teams from around the world to automatically classify images into 1,000 different categories.
In 2012, the winning team did it with a deep neural network, a first for this competition. Indeed, the great complexity of the task had previously seemed too great to use neural networks. Significantly, this team’s solution made almost half as many errors as the second-place team in the competition.
Their solution was based on a neural network that was very deep at the time (8 layers). The learning of the network was possible thanks to the use of GPUs and thanks to a set of new techniques to facilitate the use of gradient backpropagation (in particular by changing the way neurons return their activation value).
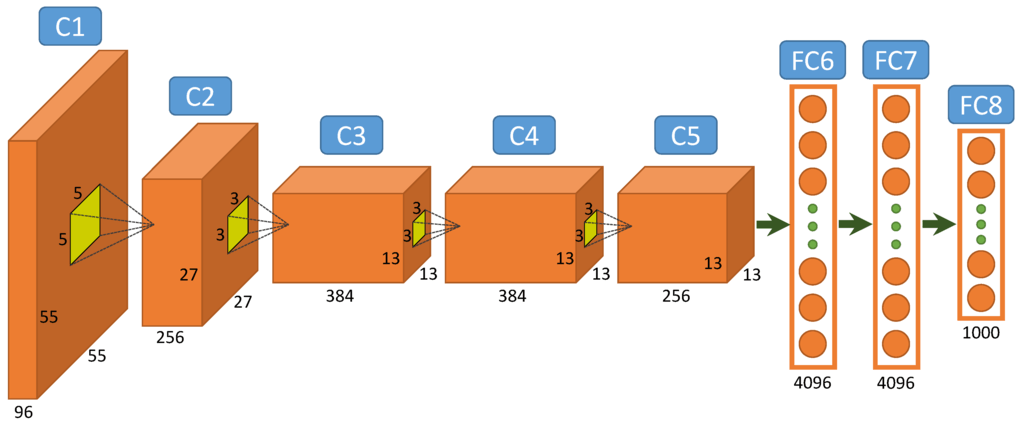
The following year, all the best teams used neural networks and today, no one uses different methods for this competition.
Deep neural networks (or Deep Learning, the word “Deep” referring to the depth of the networks, i.e. their large number of layers) thus have their origins in relatively old approaches, but their current exposure is due to a set of very recent technological and algorithmic advances.
A definition of Deep Learning
In recent years, Deep Learning has been particularly highlighted in the media through its applications in Artificial Intelligence. This discipline, a sub-domain of Machine Learning, has recently brought back AI alone to the forefront. Today, research in the field is almost entirely focused on Deep Learning, which has led to major advances in image and text processing. Let’s try to see what is behind this term, which has become popular today and which remains abstract and mysterious.
Basis of Deep Learning: Machine Learning
The objective of the “classic” machine learning is to give a machine the ability to learn how to solve a problem without having to explicitly program each rule. The idea of Machine Learning is therefore to solve problems by modeling behaviors through data-based learning.
However, before being able to model a problem through a Machine Learning algorithm, it is often necessary to perform a number of transformations on the data. These transformations, which are done manually, are dictated by the business problem to be solved, and by the choice of the algorithm used. This data processing (commonly called feature engineering) is often very time-consuming and may require business expertise to be relevant.
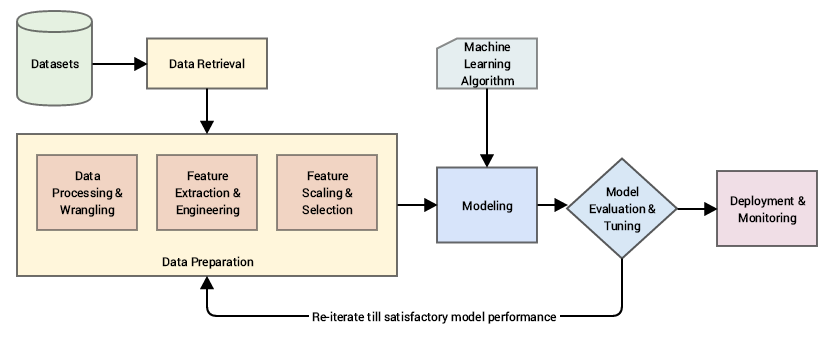
These data transformations can be seen as the construction of a representation of the problem that can be easily understood and interpreted by the Machine Learning algorithm.
What is the use of machine learning?
The idea of Deep Learning is to automatically build this relevant representation of data through the learning phase, thus avoiding human intervention. This is called learning by representation. A Deep Learning algorithm will learn increasingly complex hierarchical representations of data. This type of algorithm is therefore adapted to signal data (images, texts, sounds,…), because, by essence, these are very hierarchical.
How does Deep Learning work?
Deep neural networks are not a simple stack of neural layers. Indeed, to solve more and more complex problems, it is not enough to add more and more layers. The two major problems of neural networks, which are the learning difficulty and the increasing computational complexity with the number of layers, are indeed always present. The solutions provided by recent research make it possible to limit these problems but not to solve them completely.
It is therefore necessary to present different approaches according to the problems that one is trying to solve. In practice, there are different types of deep neural networks that aim to solve different problems.
Image analysis
For example, to analyze images in a meaningful way, it is important to analyze the hierarchy of objects defined by pixels rather than each pixel separately. Neural networks that analyze images are called convolutional networks because they use particular layers of neurons called convolution layers. These layers of neurons somehow scan the image to detect the interesting features of the image (for the problem to be solved). The superposition of several convolution layers allows the detection of increasingly complex hierarchical features in an image.
AlexNet, the neural network that won ImageNet in 2012, was a deep convolutional neural network composed of 5 convolution layers and 3 more classical neural layers.

The most common uses in image analysis are image classification (finding the category of the main object in the image), object detection (finding where all objects in the image are located, as well as their category) and image segmentation (determining for each pixel in the image to which category it belongs). These three use cases are becoming increasingly complex. However, with sufficient data, current neural networks allow to obtain performances similar to those of humans, or even superior for these problems.
Text processing
Textual data has an additional complexity that is related to its ordered structure. There is indeed a temporality in text. Understanding a sentence in a paragraph may require knowledge of the context and therefore understanding the previous sentences in that paragraph.
The neural networks that allow this type of temporal data to be processed are called recurrent networks. These networks analyze the words of the text one by one (see characters for some) and store information that seems relevant. As with more classical neural networks, recurrent networks are based on a theory that predates the era of Deep Learning. Indeed, the most frequently used recurrent networks are called LSTM (Long Short Term Memory) and they were invented in 1997. The computing power and new methods to facilitate learning have once again enabled their application on a larger scale since 2012.
The most common uses in text analysis are text classification (what is the text about?), sentiment analysis (is the text positive or negative?), machine translation and language modeling (what is the next word or character in the text?). In certain uses such as classification or translation, neural networks have performances that are close to those of humans. Nevertheless, there are still some tasks for which networks are far from it, such as sentiment analysis when irony is involved.
Auto Encoders
Neural networks are not necessarily limited to supervised learning issues, although this remains their main use. Indeed, there are also neural networks that allow unsupervised learning.
The most used in this field are probably the Auto Encoders. These networks do not aim at predicting what is in an image or a text, but only at trying to find a relevant and compressed representation of the image or the text by taking advantage of the power of representation of neural networks.
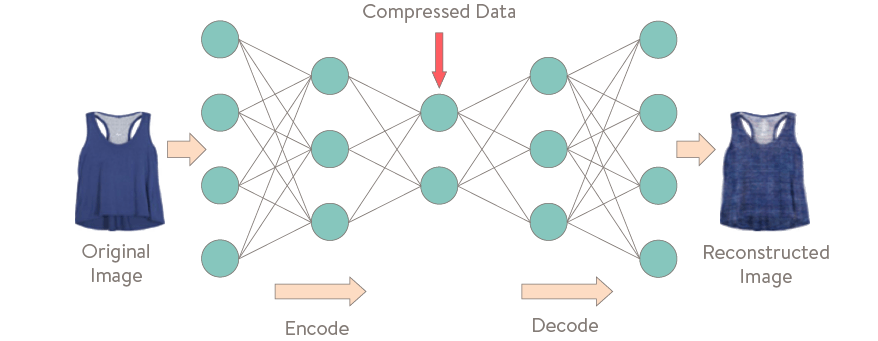
The purpose of an Auto Encoder is to be able to fully regenerate the input data. The representation found by the neural network must therefore contain enough information to be able to do the generation. The reconstruction goal forces the intermediate compressed representation to be relevant. The representations found by the Auto Encoder can then be used for other tasks, such as classification for example.
GANs
Finally, there are also templates capable of generating new content. The goal of these neural networks is to understand the data structure in an unsupervised setting. The idea on which these networks are based is that if one is able to generate content that is indistinguishable from the initial data, it is because one has succeeded in understanding the structure of this data.
GANs (Generative adversarial networks) are probably the most promising generative networks. Learning this task is difficult and requires the use of two antagonistic networks. One of the two networks aims to generate data as close to reality as possible, while the goal of the second network is to be able to distinguish between real data and the data generated by the first network. The networks are said to be antagonistic because they are in competition during the learning process. By training the two networks in parallel, they each improve in their respective tasks. At the end of the learning process, the result is a network capable of generating data that is very close to reality.

GANs have been successfully used to generate data but also to colorize black and white images, to increase image resolution or to reconstruct partially erased images. However, the very high learning curve of GANs still limits their potential, which seems very promising.
Deeper is better?
Why does Deep Learning work so well compared to more traditional Machine Learning algorithms? A first part of the answer seems to be the representational learning algorithm nature of Deep Learning. Indeed, this way of learning allows to automatically build the most useful features to solve a problem. Manual data engineering work is therefore much less present when using Deep Learning rather than more classical Machine Learning algorithms. This absence of manual work makes it possible to take full advantage of the very large volumes of data and computing power that have become available since the emergence of Big Data.
A second part of the answer may lie in the generalization capacity of Deep Learning. Indeed, unlike more traditional algorithms, which learn solutions that only work for a single problem, the solutions found by deep neural networks can often be applied to other similar tasks (with a few adaptations). This is called Transfer Learning. For example, it is possible to use neural networks that have been learned from the images of the ImageNet competition and to readapt them so that they can recognize new types of objects. This method saves time since it is not necessary to teach the network everything, since the knowledge base to distinguish one image from another has already been learned.
This ability to transfer tasks is possible once again thanks to the increasingly complex hierarchical representations obtained during the learning phase. Indeed, the first layers of neural networks learn to look for very simple characteristics in images (lines, curves, colors, etc…). These first characteristics are largely independent of the problem to be solved, so they are relevant and reusable for a large number of different tasks. When we do Learning Transfer, we sort of cut out the part of the network that is specific to a particular task and keep the generalist part.
Since learning very large neural networks is a long and complicated process, Transfer Learning has most likely had a really important role in the democratization of Deep Learning.
What about the future of Deep Learning?
Now that you are comfortable with Deep Learning and even know its origins, it’s time to take an interest in its future. Current research in the field is exceptionally active and new neural network architectures, new types of layers and new learning techniques are appearing very regularly. The performance of networks since AlexNet in 2012 has continued to improve quite impressively.
The proof, the situations where Deep Learning beats humans are multiplying (Go, Poker, Video Games, etc…), even in areas where the supremacy of humans over algorithmics seemed indisputable. And yet, there are still many ways to improve Deep Learning. Here are some of them.
Interpretability
In image analysis
One of these tracks is related to the understanding of neural networks. The algorithms of Deep Learning are assimilated to black boxes. This means that when a neural network makes a decision, it is difficult to explain why it was made. Indeed, the decision of a neural network involves the activation or not of thousands of neurons, so it is not humanly possible to analyze everything.
Another difficulty lies in the representations learned by neural networks. Indeed, these are abstract for humans, they are not readable and understandable (it is said that they are not symbolic). Thus, when a neuron becomes active, it is difficult to explain why. Research in this field has managed to partly solve this problem by finding a method to generate fictitious images that strongly activate certain neurons. With this method, it becomes possible to understand what each neuron is looking for in an image.
Another approach to improve the interpretability of neural networks is to study the areas of the input image that have interested the network. This can help detect problems in learning the network if it is found to be interested in regions or features in images that make no sense.


In text analysis
When working on textual analysis, it is also possible to analyze when each neuron activates and thus to understand what these neurons have learned.

We realize that these methods are a posteriori explanations of neural networks. Once the learning of a network is over, we try to understand it by analyzing its components. These methods are still very manual and not very viable on a large scale. There is still a lot of work to be done to be able to reliably and robustly interpret neural network behaviors.
In security
Another area for improvement is the robustness of neural networks against attacks. It is now relatively easy to learn how to fool a neural network if one has access to all these weights. It becomes possible to find flaws in the network and to modify very slightly an image to make it look like something else. A human would not see the difference, but for the network, it is a completely different image.
There are other types of network attacks, such as patch attacks. This involves applying a special patch to any image to fool the network. The patch is constructed to be extremely specific for the network, so it will somehow overwrite all the other characteristics of the image. So a specific “toaster” patch will make any image look like a toaster image.
These types of attacks could have critical repercussions in systems where neural networks help to make important decisions (in autonomous vehicles for example). However, their impact needs to be put into perspective. In order to implement these attacks, it is necessary to obtain information about the network that, in theory, is not accessible. However, this is still a real problem, a lot of research is therefore done (successfully), to limit or block the effects of these attacks.
Networks learning
Other avenues aim to improve the weak point of deep neural networks: the very large amount of data required for learning. Indeed, Deep Learning, which is somewhat inspired by the brain, is (still) unable to learn as well as the brain.
Few-shot Learning
For this reason, there are approaches to facilitate learning to solve problems where it is not possible to have a large number of labeled samples. It is necessary in these conditions to succeed in making a network learn with very few examples. This is called Few-shot Learning (or K-shot learning). In general, these methods are based on the idea of Transfer Learning (if a neural network already knows how to solve a task, it is possible to teach it to solve a similar task with few examples).
These approaches seek to adapt to the types of data to which we have access today. The vast majority of data produced today is either unsupervised (there are no labels associated with the data) or semi-supervised (there are a few labels but a majority of unlabeled data). If we succeed in taking advantage of the knowledge and information contained in these data, it could become possible to build much more complex and efficient models than those currently available.
Multi Task Learning
With a view to obtaining the most generic networks possible, some approaches also focus on the idea of learning to solve several different tasks at the same time (this is called Multi Task Learning). This kind of approach seems very promising since humans seem to learn in this way. Indeed, by being able to understand the similarities between different problems, one becomes able to solve them faster and more efficiently.
Finally, a number of approaches seek to bring the functioning of deep neural networks closer to the functioning of the human brain. A child is able to learn a language extremely quickly and with a very small amount of data. Similarly, he will be able to understand new concepts by observing, and without needing to be explained every detail many times. Human learning is therefore much more effective than Deep Learning and is largely unsupervised. We do not really understand how the human brain works during learning, but it is relatively safe to think that the mechanisms used are different from those present in Deep Learning. Almost all of today’s deep neural networks are learned with the gradient back-propagation algorithm, and many researchers believe that finding a better way to do this learning is the key to improving performance and getting closer to how the human brain works. New methods are beginning to emerge, such as network learning through reinforcement or genetic algorithms, and it is likely that the coming years will see further advances in this area.
Knowledge analysis
Finally, it seems interesting to dwell on an example given by Andrej Karpathy (currently Director of AI at Tesla) on knowledge analysis. He presents this picture.

This picture is fun. But it is only fun for a human. Indeed, the amount of information that it is necessary to know and understand to be able to analyze this image is very important. A human makes this analysis without even realizing it, but it is almost impossible for today’s machines. A small non-exhaustive list of what it is necessary to understand:
- There are men in suits in a corridor.
- There are many mirrors in the room and therefore some people are only reflections.
- The man in the middle is Barack Obama.
- He was president of the United States at the time of the photograph.
- A man is on a scale, weighing himself.
- Barack Obama has his foot on the scale and presses it.
- The laws of physics imply that the weight on the scale will be greater.
- We feel that the person on the scale is confused because the weight on the scale is not the one he knows.
- The people in the background are amused to see the confusion of the person on the scale.
- A chairperson does not usually do this kind of action, which makes the image more amusing.
By going into even more detail, one realizes the complexity of the task of understanding this type of image, a task that is obvious to a human being.
For a machine to be able to understand this kind of image, in addition to recognizing all the objects and people present, it is necessary that it has access to vast knowledge and is able to process it. The representation of knowledge and its processing in AI has been based a lot on the manipulation of many manual symbolic rules. These systems are often very long and complicated to set up in addition to requiring significant human involvement. It will probably be necessary to succeed in abstracting from these symbolic rules to obtain systems capable of understanding images like the one above.
The future of AI could therefore go through systems combining representation-based learning (Deep Learning) with complex means of reasoning. However, there is still a lot of work to be done.




