
Le concept de machine learning, issu de la data science, est complexe à définir, car il ne signifie pas la même chose pour tout le monde. Cependant, chacun s’accordera à dire qu’il fait partie d’un domaine encore plus large : l’intelligence artificielle.
Qu’est-ce que le machine learning ?
En intelligence artificielle, on apprend à une machine à présenter un comportement « intelligent ». Selon la définition, le machine learning est l’apprentissage d’une machine à apprendre.
Grâce à ce qu’elle apprend, la machine peut ensuite prendre des décisions pour aider les entreprises. Cependant, une machine ne peut apprendre comme le font les hommes ou les animaux (pas encore) ; alors, elle apprend par les données, les patterns, la reconnaissance de points communs entre les variables.
Les algorithmes de machine learning permettent à une machine de pouvoir apprendre des modèles très complexes et de traiter un grand nombre d’informations.
Le principal obstacle réside donc dans la qualité des données fournies puisqu’elles représentent la source de l’apprentissage. C’est pourquoi il est nécessaire d’associer au machine learning d’autres disciplines comme l’informatique (plus précisément le big data, l’intelligence artificielle) et une expertise métier spécifique. L’ensemble de ces disciplines est souvent appelé « data science ».
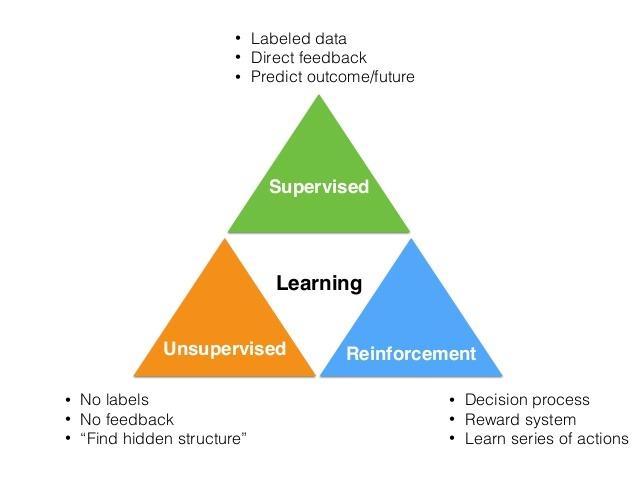
Selon la définition du machine learning, il y a 3 techniques pour tirer de la valeur des données :
- l’apprentissage supervisé (supervised learning) ;
- l’apprentissage non supervisé (unsupervised learning) ;
- l’apprentissage par renforcement (reinforcement learning).
La manière de procéder et les algorithmes de machine learning utilisés dépendront des données disponibles et de la problématique à traiter.
Chez Saagie, on tente de rendre compréhensibles pour tout le monde, les concepts complexes de big data et de data science. C’est pourquoi, plutôt que d’utiliser des cas d’usage classiques, nous utiliserons des exemples plus familiers comme la classification des chats et des chiens par l’ordinateur.
Machine learning : l’apprentissage supervisé
La technique de l’apprentissage supervisé consiste à associer des étiquettes aux données dans le but que cela se fasse ensuite automatiquement grâce aux algorithmes mis en place. On fait donc apprendre à la machine un modèle décisionnel grâce aux étiquettes préalablement associées aux données.
Prenons l’exemple d’un cas d’usage simple : la classification d’images.
Imaginez : nous avons un jeu de données d’images de chats et de chiens.
Nous, les hommes, savons faire la différence entre une image de chat et une image de chien, mais nous voulons créer un algorithme pour ne plus avoir à faire la classification nous-mêmes. Nous indiquons donc par l’étiquette « chat » ou « chien » ce que représente chaque image d’entraînement au modèle, qui pourra ainsi apprendre à faire la différence sans notre aide.
En découvrant une nouvelle variable de type image, notre modèle de machine learning devrait donc – s’il a bien appris – être capable d’associer lui-même l’étiquette.
Attention cependant aux données d’entraînement choisies, car une image comme celle-ci-dessous poserait problème à notre système d’algorithme, et notre but n’est pas de le piéger. Si les données étiquetées utilisées pour l’apprentissage supervisé ne sont pas représentatives des images qu’il devra classifier par la suite, le modèle ne sera pas performant.

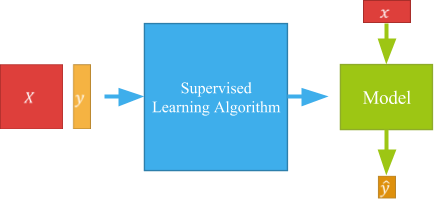
Structurons davantage. Le carré rouge x représente les données entrantes. Il est possible de l’imaginer comme un tableau où chaque ligne est une variable (et donc une image de chat ou de chien).
En colonnes, on trouvera les caractéristiques principales des exemples (pour des images, ce sera les pixels). À chaque exemple, on associera ensuite une étiquette, représentée ici par le y.
Le rôle de l’algorithme de machine learning sera de déterminer quelle étiquette associer aux nouvelles données en fonction des caractéristiques qu’elles présentent.
Ça y est, on arrête avec la théorie, mais à quoi peut-on appliquer ce genre de technique ? Les possibilités sont presque infinies. Les deux principales limites sont votre imagination et les données en votre possession.
Voici quelques cas d’applications :
- La maintenance prédictive : prenons à nouveau un chat, le vôtre si vous en avez un. Vous voulez savoir à quel moment il va rencontrer un problème de santé. En réalité, nous faisons de la maintenance préventive régulièrement en emmenant notre animal chez le vétérinaire. Cela permet d’anticiper les problèmes en connaissant à peu près quand ce genre d’animal sera le plus sujet à des soucis de santé. Cependant, votre chat est unique. Il n’aura peut-être aucun problème et vos rendez-vous chez le vétérinaire auront été inutiles ou, au contraire, il lui en faudra davantage. Grâce à la maintenance prédictive, l’animal peut être supervisé en temps réel : pouls, taux d’hormones… En analysant les données passées du chat, on sait reconnaître avec précision le symptôme d’un problème de santé qui conduira donc à un rendez-vous chez le vétérinaire.
- La prédiction de ventes/stock : soyons honnêtes, en matière de nourriture pour chat, certains mois, les placards en sont remplis et soudain, la pauvre bête n’a plus rien à se mettre sous la dent. Ici, nous allons donc chercher à prédire la quantité de croquettes à acheter chaque mois. En observant les habitudes alimentaires de notre chat, nous pourrons prédire précisément la quantité mensuelle à acheter. Facile, n’est-ce pas ? Cependant, les choses se compliquent puisque l’on doit prendre certains critères en considération pour avoir un modèle pertinent : chaton, votre chat mangeait moins, on peut donc penser qu’en grandissant, il mange de plus en plus (c’est la tendance). Par ailleurs, il mange peut-être davantage en hiver pour se protéger du froid (c’est la saisonnalité). Et en plus de tout cela, imaginons qu’il décide soudainement que la nourriture que lui donne votre voisine est finalement davantage à son goût !

- Réduction du taux d’attrition : restons avec nos chats. L’intérêt ici est de savoir à quel moment le chat de gouttière que nous nourrissons depuis deux ans va finalement se dire que l’herbe est plus verte chez le voisin. Grâce au grand nombre de chats que nous avons nourris, nous pouvons déterminer le facteur qui les pousse à nous quitter. Cependant, il reste difficile d’être certain de la raison puisque nous ne connaissons pas grand-chose de la vie du chat, sinon son comportement avec nous.
- Détection d’événements : il s’agit d’un cas similaire à celui du taux d’attrition, mais un peu moins compliqué. En machine learning, l’apprentissage supervisé aidera à déterminer, par l’analyse du comportement de notre chat, s’il vit un événement particulier ou s’il s’apprête à en vivre un. Il peut s’agir par exemple de l’achat d’une voiture, même si ce genre d’événement sera peu fréquent chez un chat.
Machine learning : l’apprentissage non supervisé
Ici, plus d’étiquette à disposition, le principe est d’identifier une structure dans les données afin de l’interpréter.
Contrairement à l’apprentissage supervisé, l’action ne se fait pas en deux temps. On ne se sert plus d’éléments étiquetés passés pour faire de la prédiction, mais on s’intéresse à la structure des caractéristiques de nos données.

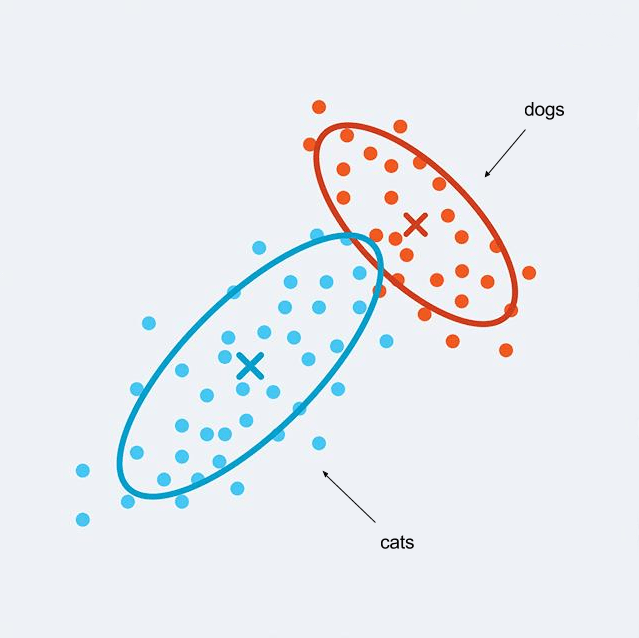
Alors on reprend notre jeu de données d’images de chats et de chiens, mais on n’est plus capable de dire à la machine s’il s’agit de chats ou de chiens (plus de données étiquetées). On lui demande d’analyser les caractéristiques de nos images variables pour les interpréter.
Ici, cela pourrait permettre l’identification de 2 groupes d’images similaires (clusters). Chaque point de données (dans notre exemple point = image) sera alors placé dans l’un des deux groupes selon ses caractéristiques pendant le regroupement (clustering). On pourrait ainsi conclure que l’un des groupes correspond à des images de chats, et l’autre à des images de chiens.
L’apprentissage non supervisé se distingue donc aussi par le fait qu’il n’y a pas de vérité absolue dans les résultats. Il est donc plus difficile de savoir si le modèle obtenu est pertinent. Afin de s’assurer de la légitimité des résultats, on préfèrera donc vérifier si les groupes constitués correspondent bien aux données (que chaque cluster est compact, différent et indépendant des autres clusters) et que les clusters trouvés ont un sens d’un point de vue métier.
Différentes méthodes d’apprentissage non supervisé servent principalement à préparer les données. Cela permet d’avoir une image plus claire de la structure des données avant d’aller plus loin dans leur analyse par les entreprises en utilisant d’autres méthodes.
Cependant, elle se suffit à elle-même dans les applications suivantes :
- Détection d’anomalies : ici, le but est d’identifier les chats qui sortent du lot. On lance donc un regroupement et tous les points de données qui n’entrent dans aucun cluster sont considérés comme des anomalies. Il est aussi possible de détecter une anomalie sous forme de groupe entier composé de différents chats qui n’entrent dans aucun des autres groupes. Sur l’image ci-dessous, quel chaton est l’anomalie ?

Vous vous dites que la question est un peu bête, que l’anomalie saute aux yeux : l’unique chat noir sur la gauche de l’image. C’est parce qu’il s’agit d’un piège, tout dépend du critère qui définit l’anomalie.
Le chaton noir pourrait bien être une anomalie, mais cela ne serait le cas que si l’on recherche une anomalie en fonction de la couleur du pelage. En revanche, si l’on s’intéresse à la direction du regard des chatons, c’est celui du milieu qui est notre anomalie. D’où l’importance de l’analyse a posteriori avec une expertise métier du modèle.
- La détection de fraudes est sans doute le cas d’usage le plus commun de la détection d’anomalies. Ici, on part donc à la chasse aux tricheurs. Dans notre cas, il pourrait s’agir du chat qui va manger chez le voisin. Nous nous basons donc sur les données relatives aux habitudes alimentaires de nos chats.
- Dans chaque groupe, on aura donc des chats aux habitudes similaires. Ceux qui mangent de façon atypique en seront exclus. La difficulté est de ne pas confondre un chat qui mangerait peu (ce qui constitue une anomalie) simplement car il est petit, et un véritable tricheur (ce qui constitue une fraude).
- Segmentation de marché : le but ici est de faire une étude de marché afin de mieux comprendre les comportements de nos chats. Nous savons que tous nos chats sont différents et pourtant, nous les traitons de la même manière. Mais nous voulons changer et offrir des services personnalisés.
- En matière de nourriture, par exemple, il est possible d’adapter les doses ou le type de croquettes grâce à un regroupement. Attention tout de même aux critères définis, car comme pour la détection d’anomalie, un mauvais choix de critères de reconnaissance peut rendre un regroupement inutile.
Machine learning : l’apprentissage par renforcement
En étudiant les techniques d’apprentissage supervisé et non supervisé, probablement 99 % des cas d’applications du machine learning sont couverts. Mais vous êtes resté jusqu’ici, alors intéressons-nous au petit pour cent restant.
L’apprentissage par renforcement est un peu similaire à la manière dont un bébé apprend. Tout comme le nourrisson, au départ, la machine ne connait rien et doit donc apprendre (learning) par l’action. Elle tente et, en fonction des résultats obtenus, elle décide s’il s’agissait d’une bonne décision. Après de nombreuses tentatives, si la machine a bien appris de ses erreurs, elle devrait sans cesse s’améliorer jusqu’à ne prendre que de bonnes décisions (intelligence).

Les cas d’usage de l’apprentissage par renforcement sont plus restreints. Le milieu de la robotique, avec l’intelligence artificielle, est celui dans lequel il est le plus commun. De cette manière, on peut apprendre à un robot à faire toutes sortes d’actions, comme attraper une balle ou manger, par exemple. Cela lui donne de nombreuses applications pour les entreprises ou les clients.
Ce type d’apprentissage pourrait aussi s’appliquer aux dispositifs intelligents de pilote automatique ou d’aide à la conduite pour les voitures ou les drones. On l’utilise aussi fréquemment pour apprendre aux machines à jouer aux échecs ou à des jeux vidéo comme Pac-Man ou Mario. Enfin, il est aussi beaucoup utilisé dans le marketing et la publicité en ligne pour personnaliser et adapter les annonces selon chaque utilisateur. Mais comment ? On y vient.
En apprentissage par renforcement, un « agent » va prendre des décisions en temps réel en fonction des données qu’il reçoit de son environnement. Lorsqu’il prend une décision, les données qu’il obtient de l’environnement (qu’on appelle récompenses) lui permettent de savoir ensuite s’il s’agissait d’une bonne ou d’une mauvaise décision. En fonction de ce résultat, l’agent modifiera son comportement.
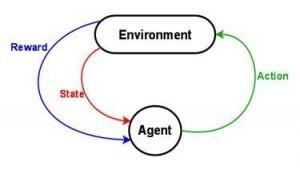
Le problème est que les conséquences de sa décision peuvent prendre du temps à lui parvenir. L’agent peut donc en prendre de nouvelles entre-temps et on ne sait plus quelle décision a conduit à telle récompense.
Prenons un exemple : on doit malheureusement laisser nos chats et nos chiens de côté, il nous faut un robot ! Prenons donc un robot chien (évidemment !) à qui on souhaiterait apprendre à marcher et à explorer le monde qui l’entoure. Notre robot aura donc un ou plusieurs capteurs, et son environnement sera représenté par toutes les données qu’il recevra via ce ou ces capteurs. Disons que le nôtre n’a qu’un capteur (raison budgétaire) et qu’il s’agit d’une caméra frontale.
Son environnement est donc une image, sa récompense est son intégrité physique en fonction de la distance parcourue. Notre robot reçoit une image, prend la décision de faire un pas et reçoit donc une nouvelle image. Son objectif est d’aller le plus loin possible sans être abîmé. Notre petit robot va donc avancer et rencontrer des obstacles. S’il fonce dans un mur, il associera le fait d’avoir pris un coup et de possibles dommages à ce mur, et ne le refera plus afin de pouvoir continuer à se déplacer. Au fur et à mesure, il apprendra à les contourner avec précision puis finalement à les éviter complètement.
Ici, la difficulté est que notre petit robot ne sait rien au départ, et contrairement à nous, n’a pas d’instinct de danger, par exemple. Donc s’il s’avance près du bord d’une falaise, il lui faudra en tomber pour apprendre qu’il s’agit d’une mauvaise décision et la prochaine fois, effectuer la reconnaissance de la falaise. Cependant, la chute aura déjà mis fin à sa vie de petit robot.
C’est probablement le problème majeur que l’on rencontre en apprentissage par renforcement. Si vous souhaitez apprendre à un drone à voler seul, il vaut mieux avoir les moyens d’avoir plusieurs drones, car ils devront rencontrer un grand nombre d’obstacles afin d’apprendre à les éviter à l’avenir. C’est pourquoi on utilise souvent une simulation d’environnement au début pour apprendre les règles fondamentales avant de passer à la réalité.
Saagie et le Machine Learning
En conclusion, Saagie propose une plateforme DataOps complète pour la gestion des projets data. Grâce à cette plateforme, les entreprises peuvent exploiter le potentiel du Machine Learning pour prendre des décisions plus éclairées et résoudre des problèmes complexes. En intégrant cette technologie avancée dans leurs opérations data, elles peuvent bénéficier d’analyses approfondies et d’une meilleure efficacité. Saagie ouvre de nouvelles perspectives passionnantes pour les entreprises qui souhaitent tirer parti du Machine Learning et exploiter pleinement le potentiel de leurs données.
Voilà qui conclut donc notre étude des différentes manières d’approcher le concept du machine learning. Les données disponibles et le problème à résoudre seront les principaux critères pour faire votre choix entre les trois types d’apprentissage.
Le machine learning est basé sur les mathématiques et l’informatique et permet de créer des modèles complexes, mais ce n’est pas de la magie. Une bonne définition du problème à résoudre ainsi qu’une expertise du domaine avec par exemple les processus de réseaux de neurones sont nécessaires si vous voulez en tirer tous les bénéfices souhaités.





