
Machine Learning is hard to define and may mean different things but everybody will probably agree that it is an Artificial Intelligence subfield. AI means intelligence exhibited by machines. In Machine Learning, we teach machines to do things. What machines learn allows them to make smart decisions later on. However machines do not learn like us (at least for now), so we teach them through data.
What is Machine Learning?
Machine Learning algorithms give machines the power to learn very complex models and to process a great quantity of information. On the other hand, they are entirely dependant and limited by the learning input (the raw data).
That’s why Machine Learning, to bring value, must be associated with other disciplines as Computer Science (Big Data) and domain expertise. The combination of these desciplines is often called DataScience.
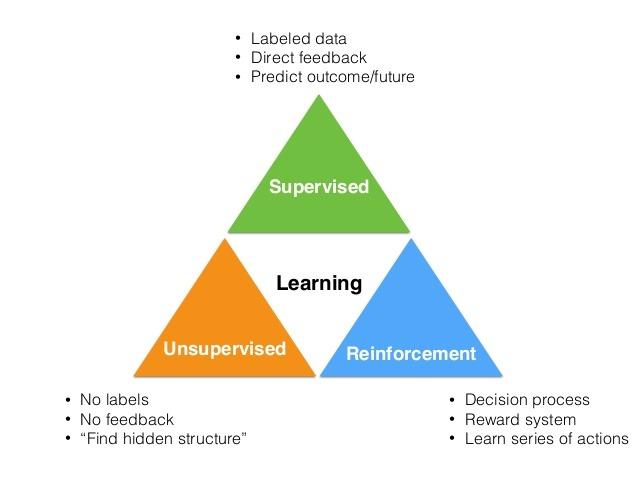
In Machine Learning there are mainly three possible ways of learning things through data:
- Supervised Learning.
- Unsupervised Learning.
- Reinforcement Learning.
Which one should you choose ? It depends on the available data and the problem to solve.
In Saagie, we try to make Big Data and Datascience accessible for everyone, even grandmothers. To make sure no one gets left behind, we will not use typical business use cases to explain Machine Learning concepts but some more familiar examples (with cats and dogs).
Supervised Learning
Let’s start this overview with Supervised Learning. It is probably the most common field. It consists in learning a decision model from data thanks to labels associated with data. Most of the time this is what we refer to when we talk about DataScience models.
Let’s first take an example with a simple task: Image Classification. Try to picture: we have a dataset of many images of cats and dogs. For each image we know if it represents a cat or a dog: that’s the label. We give all the images and their corresponding labels to the model. Then, it should be able to make the difference on its own.
If everything goes well, when showing a new image to the model (but without having its label), it should be able to tell us whether it’s a cat or a dog (if the model learned well).

Let’s formalize it a bit. The input data are shown with the X red square into the figure. This represents a matrix (similar to a table) where each line is what we call an example. Each example has values in columns (features). For each example there is an associated label (Y on the figure). From these data, the algorithm tries to understand how the different features values impact the label value.
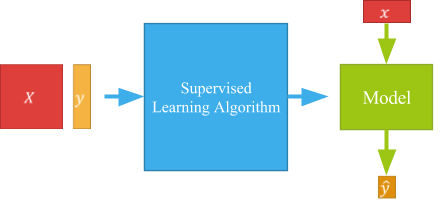
The produced model then contains learnt rules, allowing to predict the label from the features. Thus, when a new data example arrives, the model just applies those rules to predict its label. That’s the point of supervised learning : Predicting an outcome thanks to rules learnt on annotated data.
Ok that’s it for the theory, but what about the use cases? (Remember? No business.) Well there is a huge amount of possibilities. The two main limits are ideas and labeled data. Take a look on some other common use cases:
- Predictive maintenance: In this use case we want to detect when our cat get sick. Since ages, we have been doing preventive maintenance by regularly taking our cat to the vet. However, that’s not optimal because we might have a super healthy cat that doesn’t need regular appointments or a sick cat that really needs one in between the scheduled ones. With predictive maintenance we monitor in real time the vital signs of our cat. For example, we could check its pulse rate, various hormone rates in blood, etc.. From the past data of our cat, we know what are the symptoms of a problem. So, when we detect one in real time, we know that an appointment might be necessary.
- Stock/sales forecast: Here, we want to predict the amount of cat food we need to buy each month in order to optimize the space the food is taking in the cupboard. Thanks to our cat eating habits from the past, we can predict what he is going to eat in the future. However, we have to take into account several things. First, we should take the trend, that is to say that our cat will be more likely to grow his whole life and will therefore eat more and more. Then, we have to take into account other features like the weather: our cat might eat less in summer because it doesn’t have to protect itself from the cold. Finally we should also consider punctual anomalies like the neighbour’s dog eating our cat’s food or our cat suddenly choosing to only eat pizza and no more cat food.

- Churn detection: There, we want to know when the stray cat we have been feeding for the last two years will decide that the grass is greener on the other side of the fence and leave us. Thanks to the numerous stray cats we have been feeding in the past, we know what are some of the underlying factor that explain a cat churn. However, this is a difficult problem since we don’t know the cat’s entire life. We can only see how he acts with us. Maybe this cat has a hidden second life that could explain its churn but we won’t have any ideas of that.
- Life Event Detection: Rather similar to churn detection, but maybe a bit easier. According to our cat’s behaviour, we try to detect if it is experiencing a big event in its life. Like if it is expecting a happy event or going to buy a car, you know, the kind of stuff cats do.
Unsupervised Learning
Unsupervised Learning is the second big field in machine learning. There we have data but no label. So we will not be able to learn to classify cats or dogs the same way. But we will rather try to find a structure in data that we could interpret.
The Learning will not be a two-ways process like in Supervised Learning. Here we do not learn on some data to predict things for future data. In Unsupervised Learning the structure will be found according to feature values of the different examples composing our data.

Let’s still consider our dataset of dogs and cats Images but without labels this time. We have the images but we can’t tell the machine what they represent. An application of Unsupervised Learning could be to find that the underlying structure of the dataset of images defines two groups of similar images (also called clusters). Each data point (an image in our example) would be assigned to either cluster during the learning (the clustering). And finally, thanks to a specific domain expertise of cats and dogs, we could define that one cluster contains cat images and the other one contains dog images.
Unlike supervised Learning, we don’t have any ground truth here. So it’s harder to know if the learnt model is relevant. Here rather than testing on other data, we often check if our clusters fit well to data (that is to say that each cluster is compact, different and well separated from the others) or if they are in accordance with our domain expert vision.
Many methods of Unsupervised Learning are used as a kind of preprocessing step to have a better representation of data for further Supervised models for example.
However there are also use cases where Unsupervised Learning can be used alone :
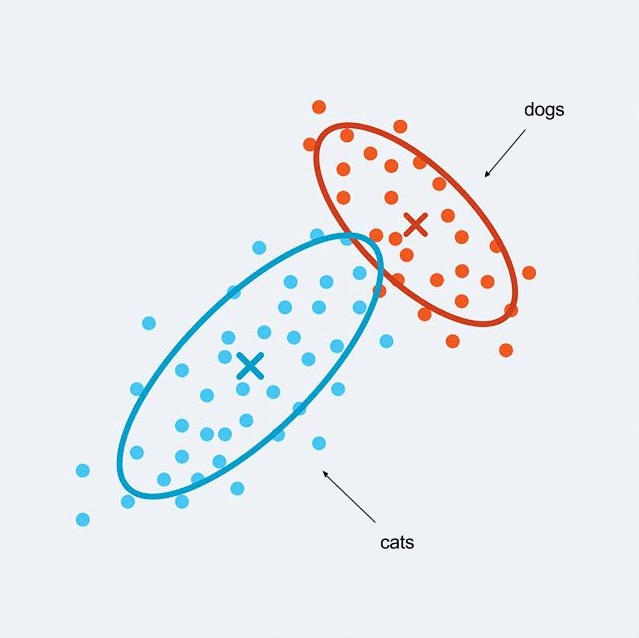
- Outlier detection: Here we want to detect cats that stand out from the others. We train a clustering on data and the ones that do not enter in any cluster are considered outliers. You may also find an outlier cluster with every outliers.
The image above shows that in Unsupervised Learning we need to pay attention to what data we take into consideration according to what we are searching for. If we look at the cats’ colors, the left one is obviously the outlier but if we check if they are looking at the camera it’s the middle one who stands out.

The most common use of outlier detection is probably fraud detection. There we want to find the cheaters. For example the cats that are eating in the neighbour’s dog bowl. We will analyze the past eating behaviour of our cats. In each cluster we should find cats that have a similar appetite. The ones with an odd behaviour will be out of the big clusters. The difficulty here is to be able to make the difference between the cats that have an odd behaviour, like a very small cat who eats very little and the real cheaters.
- Customer Segmentation: Here we want to make a cat market analysis in order to really understand our cats behaviours. We know that we have different types of cats but we actually feed them all the same way. We want to provide them the best food service possible. A way to do this is by making a clustering on cats and adapting the food service to each group. For this use case, and as in outlier detection, the domain expertise is very important because the segmentation must be done on the right features in order to be meaningful. A very good clustering on wrong features is useless.
Reinforcement Learning
With Supervised and Unsupervised Learning, we saw the two main fields covering maybe 99% of the use cases in Machine Learning. If you are only business focused you can probably stop the reading here.
However there is still another cool way to teach things to a machine and that is reinforcement Learning. This approach is a bit similar to the way a baby would learn things. Indeed, at the start the machine does not know anything. It will try something and according to the results it will decide if it was a good or a bad decision. After many tries, if the model learned well, the machine will become better and better and, eventually, only take good decisions.

The uses of Reinforcement Learning are really differen. It’s mostly used in robotics to teach new behaviours to robots, like teaching a robot to catch a ball or eat for example.
It could also be used in self driving devices like cars or drones. Another common use case is to teach machines to play games like chess or video games like pac-man, mario, starcraft… Finally another use could be online advertising where we learn which ad to show to which user by testing it and analyzing the results. In this use case, Reinforcement Learning is a bit like a super AB-testing.
So how does it work ? In reinforcement learning an ‘agent’ will take decisions step by step thanks to data it will get from the environment. Then the environment will answer a Reward (it will tell whether the action was a good one or a bad one). According to the reward, the agent will alter its rules of decision to act better in the future. The long term goal of reinforcement Learning is to maximise the rewards.
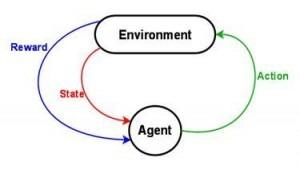
The difficulty lies in the fact that actions taken by the agent might change the environment, and the agent might get its reward a long time after its action. It then becomes hard to know which actions led to which reward.
Ok let’s take an example to make this clear. For Reinforcement Learning, examples with cats and dogs won’t do. We need robots! So let’s imagine we have a robot dog (of course) and we want to teach it to walk and explore the world. The environment consists in all the data that the robot gets through its sensors.
Let’s say that the only sensor of our robot is a camera so its environment is an image. Its reward will be the distance traveled and the robot integrity.
So the robot gets an image, uses it to take a decision: It decides to make a step and then gets a new image according to its new position. The aim of the robot is to travel the farthest possible without breaking down. The robot is going to travel and when it will encounter an obstacle, let’s say a wall, it will learn after some tries that going right into the wall might not be the best decision to travel far. It will then learn after some times to go around the walls and finally to avoid them completely.
The problem is that at the start, the agent does not have any landmark. If our robot, through its wandering, ends up at the border of a canyon, it will get an image that it has never seen before. So it will probably take the decision to go forward to improve its travel distance. However it will obviously fall down and end it’s travel abruptly.
That’s probably the main problem of reinforcement learning. If you want to learn a drone to fly on its own from the beginning, you should better have a lot of drones! Because they will experience all sort of crashes in order to understand what to do not to actually crash. That’s why most of the time a simulating environment is used at least for the early training.
So in this post, we saw the principal approaches in Machine Learning. Which one to use depends on the available data and the problem that must be solved. Machine Learning is based on Mathematics and allows us to make very powerful models and applications but it’s not magic. There is always the need for a domain specific expertise if you want to have meaningful and useful outputs.




