Chaque année, le nombre d’articles vantant dbt et ses capacités innovantes de transformation de données se multiplient. Depuis sa première version en 2016, sa communauté n’a cessé de croître jusqu’à atteindre le statut de référence parmi les data analysts et engineers.
À notre tour d’en parler !
L’apparition de la Modern Data Stack
Il est difficile d’aborder dbt sans évoquer le concept de Modern Data Stack. La MDS pour les intimes est une nouvelle approche ayant radicalement changé la data integration en se reposant sur des outils 100% cloud et ne nécessitant que peu de connaissance technique de ses utilisateurs. Pensée pour être accessible à des analystes et des utilisateurs métiers, elle requiert relativement peu de configuration et permet de diminuer le temps d’engineering pour se concentrer sur des étapes d’analyse à forte valeur ajoutée.
La Modern Data Stack se compose de différents outils permettant de couvrir l’ensemble de l’intégration des données :
- Un pipeline ELT (Extract Load Transform) complètement infogéré
- Un data warehouse orienté colonnes servant de destination aux données
- Un outil de transformation (tel que dbt)
- Une plateforme de visualisation ou de Business Intelligence
L’émergence de cette approche a suivi le développement du cloud pour offrir davantage de scalabilité face à des volumes de données de plus en plus gros, par rapport à la Traditional Data Stack historiquement on-premise.
Qu’est-ce qui rend dbt innovant ?
Dbt est un outil open-source qui répond au “T” d’ELT (Extract, Load, Transform). Il n’extrait pas ni ne charge des données, mais opère une série de transformations sur des données qui ont déjà été chargées au sein d’un data warehouse. Cette architecture “Transform after load” se démocratise de plus en plus, là où les data engineers privilégiaient auparavant plutôt des architectures ETL (Extract, Transform, Load). Transformer les données avant de les charger dans un entrepôt de données réduisait alors leur volume et la quantité de requêtes nécessaires sur ceux-ci, deux postes de dépense importants que l’adoption massive du cloud a drastiquement fait chuter ces dernières années.
Il permet d’écrire des modèles de données qui peuvent être exécutés en séquence via un DAG (Directed Acyclic Graph).
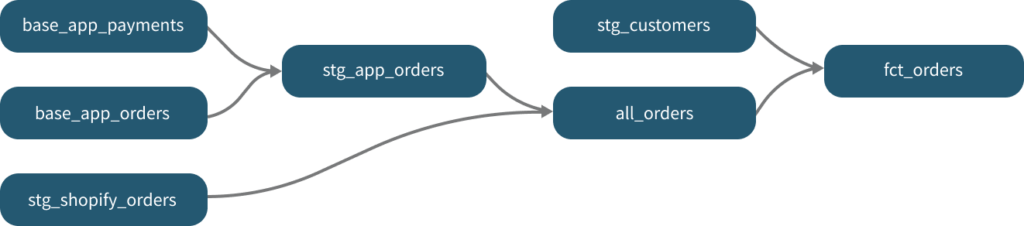
En résumé, il permet de construire des pipelines de transformation via des lignes de commande en SQL comprenant des dépendances entre modèles. Cela élimine par exemple le besoin de réécrire sans cesse le même code pour calculer un indicateur donné au sein de différents projets. Le code devient modulaire, promouvant une plus grande réutilisation entre modèles pour accélérer le temps de développement et augmenter in fine la qualité des données délivrées à l’issue du pipeline. Dbt conseille ainsi de limiter les références à la donnée brute dans son code, privilégiant plutôt la référence à des “base models” en entrée des pipelines, ce qui réduit grandement le risque d’erreurs.
Le séquencement en DAG et la nature modulaire du code, organisé en modèles “base” et “intermédiaires” accélèrent également le processing en n’exécutant les “base models” qu’une seule fois, tout en parallélisant les exécutions au besoin.
La forte adoption de dbt
Ces fonctionnalités simplifiant grandement la tâche des data analysts et data engineers ont conduit à une adoption rapide et large de dbt au sein de la communauté.
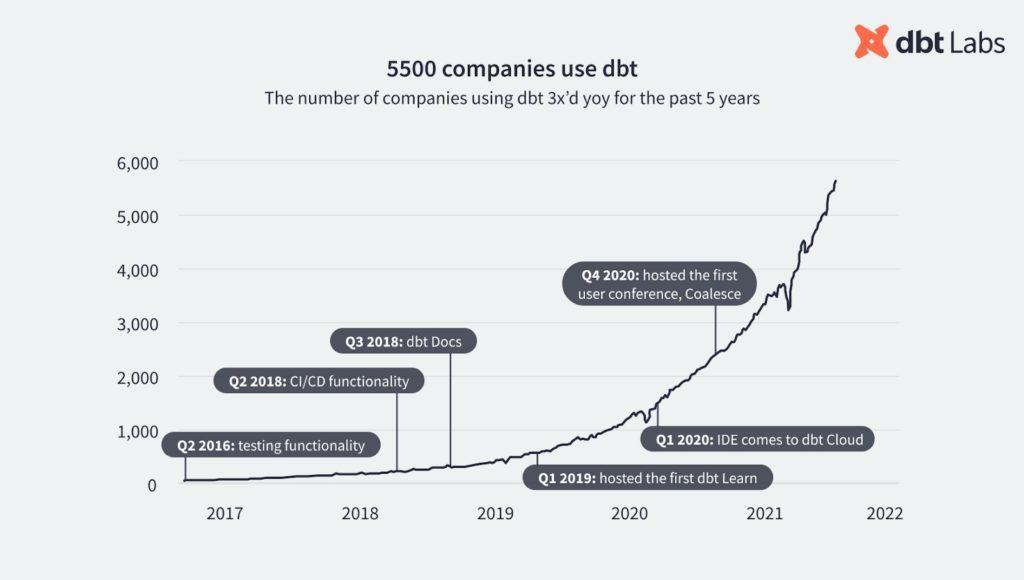
Chaque année, dbt Labs, éditeur de la solution, avance avoir constaté une croissance d’environ 200% du nombre d’organisations utilisant son outil, pour atteindre aujourd’hui 16000 entreprises utilisatrices et 50000 membres au sein de sa communauté Slack. Cela en fait alors l’un des projets open-source les plus en vogue du moment dans la sphère du data engineering.
Pour venir compléter dbt Core, une interface en ligne de commande proposée sous licence open-source, l’éditeur offre aussi dbt Cloud, un IDE (Integrated Development Environment) en ligne proposant une interface visuelle pour développer, ordonnancer, documenter et superviser ses jobs. Mis à disposition sous licence commerciale, cet outil compte pour sa part 3000 clients à l’heure actuelle selon dbt Labs.
Cette adoption rapide est sans doute accélérée par la compatibilité de dbt avec les entrepôts de données les plus utilisés dans le cloud, notamment Google BigQuery, Snowflake, Amazon Redshift ou encore Postgres.
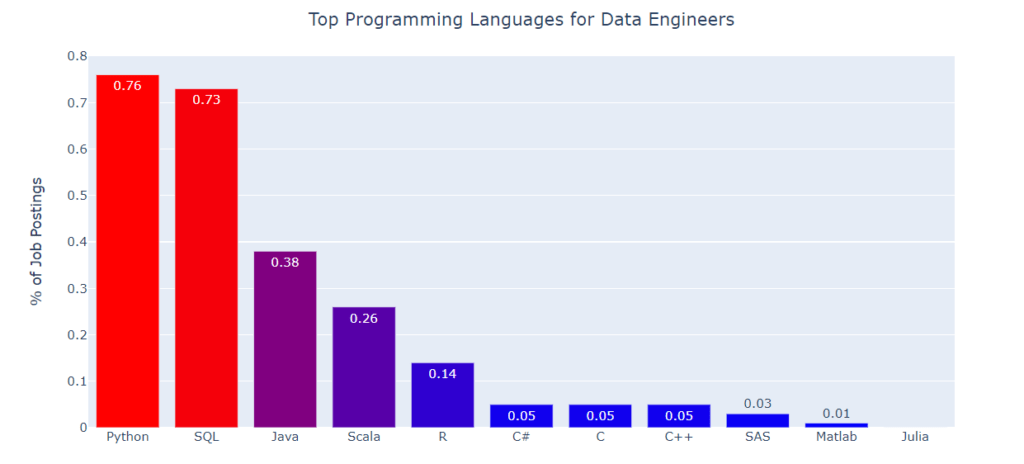
Bien que paraissant progressivement passer de mode il y a encore quelques années, SQL, langage de requêtage au cœur de dbt voit au contraire son usage résister au sein des équipes data. Ainsi, bien qu’ayant été détrôné par Python, des connaissances en SQL étaient selon KDNuggets encore demandées dans 73% des annonces d’emploi de data engineers en 2021. Cela supporte alors la tendance observée par dbt, qui devrait se prolonger dans les prochaines années.
Saagie intègre dbt à son catalogue de technologies
Constamment à l’écoute de nouvelles technologies innovantes à proposer à ses utilisateurs pour adresser leurs besoins data & analytics, Saagie vient d’ajouter dbt Core à son catalogue de technologies de jobs. Disponible dans sa version 1.2, les utilisateurs de Saagie peuvent ainsi exécuter des projets dbt en tant que jobs Saagie et les intégrer au sein de pipelines conditionnels, avec une couche standardisée d’ordonnancement, de versioning et de supervision.
Cette technologie rejoint la sélection de plus de 40 contextes d’exécution offerts au sein de la plateforme DataOps de Saagie, allant de frameworks open-source tels que Python, R ou Spark à des applications Docker comme Jupyter Notebook, MLFlow ou Grafana, en passant par des connexions à des technologies commerciales comme AWS Batch ou EMR.





