
Difficile de se remémorer la date à partir de laquelle l’IA (Intelligence Artificielle) s’est envolée, surement lors de la montée de la data science. Galvaudée, travestie, usurpée, le moins que l’on puisse dire, c’est que l’IA a suscité autant d’espoirs que de désillusions. Après toutes ces années, peut-on encore croire en l’intelligence artificielle et ses applications ? A-t-on seulement convenu d’une définition commune ? Est-celle au bout du compte une menace plus qu’un progrès ? L’heure des comptes vient de sonner.
Une Définition de l'Intelligence Artificielle et du Machine Learning
Il existe plusieurs écoles et aucune définition n’a trouvé de parfait consensus. Pour ma part, j’ai tendance à croire que l’IA peut se définir comme un ensemble de sciences et techniques visant à concevoir des machines (incluant les matériels et logiciels) autonomes dotées de capacité d’apprentissage et de raisonnement analogues à celles des humains. Elle repose en particulier sur le big data et le machine learning. Autant le big data est bien défini par les entreprises – ne serait-ce que pour évoquer la volumétrie et la richesse des données déstructurées – autant le machine learning peut prêter à confusion.
Le machine learning (ou apprentissage automatique) désigne avant tout la batterie d’algorithmes permettant aux analystes d’extraire de l’information actionnable depuis des minerais de données brutes. Il en existe principalement trois grandes familles :
Les algorithmes descriptifs basés sur le machine learning dit “non-supervisé” :
- Objectif : comprendre / résumer / simplifier les données et leurs relations ; décrire la structure sous-jacente ;
- Particularités : il n’y a pas de variable-cible (à expliquer), pas d’historique labellisé, pas de rétroaction ;
- Exemples d’algorithmes : analyses factorielles, clusterings, règles d’association et autres factorisations matricielles, etc. ;
- Exemples de cas d’usage : analyse de réponses à un questionnaire, segmentation de clients, moteurs de recommandation, etc.
Les algorithmes prédictifs (ou extrapolatifs devrait-on dire) basés sur la machine learning dit “supervisé” :
- Objectif : trouver la relation de cause à effet existant entre des variables en entrée (prédicteurs) et une réponse (variable-cible) attendue en sortie ;
- Particularités : présence d’une variable-cible (à expliquer), historique labellisé, rétroaction immédiate (erreur) ;
- Exemples d’algorithmes : régressions (linéaires, logistiques, Gamma, Poisson), SVM, arbres de décision, random forest, gradient boosting, réseaux de neurones, etc. ;
- Exemples de cas d’usage : prévision de la température ou des ventes, classement automatique d’images, anticipation du churn de clients, analyse de la durée de vie des équipements, etc.
Les algorithmes d’amélioration/optimisation basés sur la machine learning dit “par renforcement” :
- Objectif : améliorer le comportement décisionnel d’un agent autonome (programme agissant comme un automate) évoluant dans un environnement spécifique ;
- Particularités : le système est composant d’un agent, d’un ensemble d’états relatifs à l’agent dans l’environnement, d’un ensemble d’actions et d’un système de récompenses que l’agent souhaite optimiser ;
- Exemples d’algorithmes : processus markoviens, Monte-Carlo, Q-Learning, différences temporelles, algorithmes de bandit, etc. ;
- Exemples de cas d’usage : adversaire pour les jeux (jeux vidéos, échecs, Go, etc.), véhicules autonomes, allocation de ressources informatiques, chimie moléculaire, etc.
Et le Deep Learning dans tout ça
Le deep learning est un sous-ensemble du machine learning désignant une catégorie particulière d’algorithmes : celle des réseaux de neurones à couches profondes. Ces derniers ont explosé au cours des dix dernières années de par leur extrême précision et leur grande versatilité. Il est en effet possible d’utiliser le deep learning pour des problématiques supervisées (réseaux convolutifs pour le traitement des images, réseaux récurrents pour le traitement du texte) ou non supervisées (réseaux auto-encodeurs pour les fraudes, réseaux antagonistes génératifs pour la création d’images). Néanmoins, le deep learning souffre encore d’un problème majeur, celui de l’interprétabilité du fonctionnement algorithmique, ce qui est peut être gênant lorsque des actions métiers doivent découler des paramètres du modèle.
Il peut être tentant de limiter l’IA au deep learning et au NLP (traitement du langage naturel). En effet, ce sont principalement ces techniques qui ont favorisé l’essor des applications modernes comme les assistants virtuels, le traitement des médias, les véhicules autonomes, etc. On peut cependant également y rattacher des disciplines plus “anciennes” comme les statistiques et probabilités, les automates informatiques et le machine learning traditionnel (celui utilisé par les data miners et actuaires depuis plus de trente ans).
Par ailleurs, on peut également ajouter – au périmètre de l’IA – les sciences cognitives qui sont une grande source d’inspiration dans l’élaboration d’algorithmes de deep learning, et les sciences sociales qui ont permis d’ébaucher les contours de certaines réflexions comme la place de l’IA et la machine dans la société moderne et la construction de comités d’éthique pour protéger les citoyens de potentielles dérives. Sur ce dernier point, l’un des débats les plus répandus est sans conteste celui de la responsabilité des IA en cas de défaillances (par exemple un accident de voiture autonome).
A quoi servent les IA au quotidien ?
Comme toute avancée technologique, les IA permettent des progrès incontestables en termes de confort, d’économies et de développement de services. En entreprise, l’un des principaux chantiers des IA consiste dans le prolongement de la robotisation informatique, c’est-à-dire que l’on cherche à automatiser (ou du moins à accélérer) les tâches ingrates et répétitives des équipes via des techniques de reconnaissance optique de caractères, d’interprétation du texte et de la parole, etc.
Éventuellement, les techniques d’IA peuvent aller plus loin et être un véritable soutien dans l’optimisation de processus métiers et la prise de décision. Par exemple, les modèles de connaissance client – quel que soit le secteur d’activité considéré – visent à détecter efficacement certains signaux faibles ou comportements. Ces derniers permettent aux entreprises d’améliorer l’expérience client en agissant au moment opportun (à une date précise ou près d’un lieu spécifique) pour proposer un service en adéquation avec leurs besoins. Auparavant, on adressait a priori des segments de clients plus ou moins homogènes. Aujourd’hui, le ciblage s’affine et s’effectue post-hoc, c’est-à-dire sur la base d’un historique de comportements observés et de l’analyse de clients similaires. Mais dans la pratique, les erreurs de ciblage sont courantes et imputables au manque de données qualifiées dont disposent les entreprises et au manque d’inclination légitime qu’ont les citoyens vis-à-vis de l’utilisation de leurs données personnelles.
Pour prendre un autre exemple, dans le domaine de la médecine, l’IA peut s’avérer être une aide précieuse dans l’établissement de certains diagnostics comme la détection de tumeurs sur des radios ou scanners. Evidemment, il peut être tentant de se fier à un algorithme qui “a vu passer” des millions de radiographies même si dans certains cas, on préfèrera recouper avec l’avis d’un expert… humain ! Dans tous les cas, l’IA ne remplacera jamais le praticien dans la relation qu’il/elle entretient avec ses patients, ne serait-ce que pour la communication des résultats et l’explication de la bonne démarche à suivre. En effet, la dimension psychologique affecte parfois grandement l’efficacité des traitements. C’est d’ailleurs la raison pour laquelle les études thérapeutiques s’effectuent presque systématiquement en double aveugle afin de neutraliser l’effet placebo/nocebo.
Comment mettre en oeuvre une application basée sur l’IA ?
C’est notre volonté chez Saagie que de démocratiser la mise en oeuvre de projets analytiques (BI et/ou IA) pour servir les métiers. Nous sommes convaincus que la réussite de ces transformations passent notamment par l’implémentation d’un environnement de travail faisant cohabiter un grand nombre de collaborateurs (développeurs, data engineers, data scientists, exploitants des SI, etc.) ayant chacun ses outils de prédilection. Il convient donc d’orchestrer un grand nombre de technologies hétérogènes et d’automatiser les processus analytiques, tout en conservant de l’agilité et du contrôle pour itérer rapidement, reproduire à plus grande échelle et capitaliser sur les travaux réalisés en parallèle. Enfin, ce type de solution doit permettre de sécuriser les investissements SI en assurant une certaine adaptation et réversibilité, quelle que soit la politique d’urbanisation retenue (cloud, multi-clouds, on-premise, hybride, etc.).
Faut-il craindre les IA ?
Quant au caractère menaçant voire apocalyptique des IA supposées incontrôlables, le web regorge de propos alarmistes – parfois ridicules. Ce n’est pas parce que l’IA et l’IH (Intelligence Humaine) partagent le terme “Intelligence” qu’elles reposent toutes deux sur les mêmes fondements. L’IH est extrêmement complexe à définir et à résumer mais j’ai pour ma part l’habitude de la caractériser comme un ensemble d’aptitudes cognitives permettant aux humains d’apprendre, de comprendre, de communiquer, de penser et d’agir de manière pertinente, rationnelle, logique ou émotionnelle, en fonction de la situation dans laquelle ils se trouvent. On est donc assez loin de la définition de l’IA.
Pour faire simple, on peut dire que l’IA ne fonctionne que par analogie au fonctionnement cognitif humain dans le but de créer des machines un tant soit peu autonomes. Le schéma ci-dessous vise à résumer les piliers sur lesquels reposent respectivement l’IH et l’IA. On remarquera que l’IH repose sur des déclinaisons fonctionnelles d’intelligence, tandis que l’IA se rabat sur des domaines scientifiques.
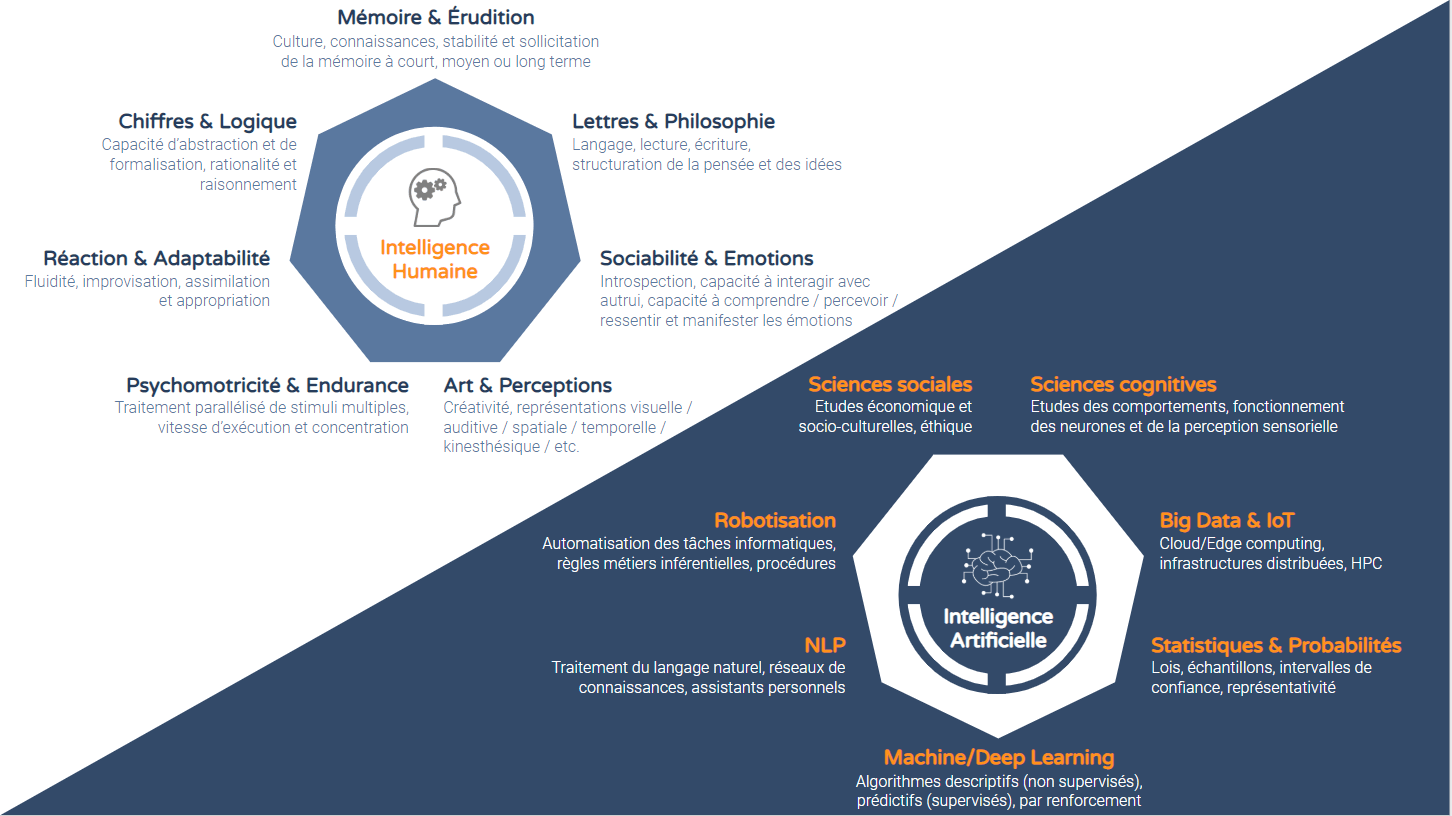
On a pu lire certains posts farfelus relatifs à l’émergence prochaine d’une IA forte qui supplanterait l’humanité dans tous les domaines, ou tout du moins, serait dotée d’une conscience (artificielle), attribut jusqu’alors exclusif aux humains et animaux. Aujourd’hui, si personne n’a pu démontrer l’existence – ni l’absence – théorique de la conscience artificielle à base de circuits électroniques, on est en revanche certain des obstacles industriels majeurs se dressant devant elle : il faudrait en effet l’équivalent d’un quart du parc nucléaire français pour faire fonctionner un réseau de neurones artificiels comportant autant de neurones biologiques que le cerveau humain. Autant dire que le bilan énergétique d’un pseudo-cerveau artificiel est catastrophique et qu’il est probablement certain que cela ne suffise pas à approcher le moindre contour de la conscience, tant le fonctionnement physiologique du cerveau humain est fondamentalement différent. Pour plus de précisions sur ce sujet, je vous invite à consulter cet article qui décrit dans quelle mesure il est difficile, voire impossible, de comprendre les mécanismes de la conscience et qu’aucune technologie – même quantique – ne permettra de lever toute la vérité sur la question.
En synthèse, il est toujours bon de se rappeler que, de par sa conception même, les IA sont intrinsèquement superficielles et sans “âme”. Elles ne font bien souvent qu’imiter naïvement certains attributs humains ou extrapoler un certain nombre de décisions sur la base de grands volumes de données de référence. Alors oui, elles apportent un confort indéniable dans nos vies et améliorent considérablement certains pans de la recherche. En ce sens, elles nous complètent parfaitement, et c’est bien cela que l’on souhaite. On est heureusement loin de l’idée d’un grand remplacement des travailleurs. Toutefois, il est clair que la connaissance (même basique) des grands principes de l’IA, en particulier du machine learning, sera une nécessité pour un grand nombre de professions, tout secteur confondu. Les métiers s’adapteront continuellement aux nouveaux outils et aux nouveaux enjeux sociétaux, ceci dans une logique de dépassement de soi et de progrès. Il est donc primordial pour les entreprises d’anticiper ces évolutions et d’embrasser le changement plutôt que de craindre l’arrivée de ces nouvelles données et technologies.





