
Avant toute chose, il est important de connaître l’histoire du Deep Learning, avant de découvrir dans deux autres parties son fonctionnement puis, pour finir, ses perspectives d’avenir. Le Deep Learning, concept englobé par la data science, est une terminologie relativement nouvelle, contrairement aux réseaux de neurones profonds, qu’elle désigne. La théorie derrière le Deep Learning n’est donc pas récente, et même si de nouvelles méthodes algorithmiques ont permis de révéler son plein potentiel, ses fondements remontent au milieu du XXe siècle.
Les origines du Deep Learning
Le neurone artificiel ou neurone formel
C’est au milieu des années 40 qu’a été formalisée l’idée d’un neurone artificiel, qui est une abstraction mathématique très simplifiée d’un neurone du cerveau humain.
Un neurone artificiel est un outil mathématique qui reçoit des valeurs en entrée, pondère ces valeurs avec des poids (ou coefficients) et retourne une valeur en sortie, en fonction de la somme des valeurs pondérées. La valeur renvoyée par le neurone s’appelle alors une activation. C’est donc bel et bien une abstraction mathématique d’un neurone biologique qui, de façon très simplifiée, reçoit des signaux électriques par ses dendrites, les transforme dans ses synapses et s’active ou non en fonction des signaux reçus. Si un neurone biologique s’active, cela signifie qu’il transmet le signal électrique reçu à d’autres neurones.
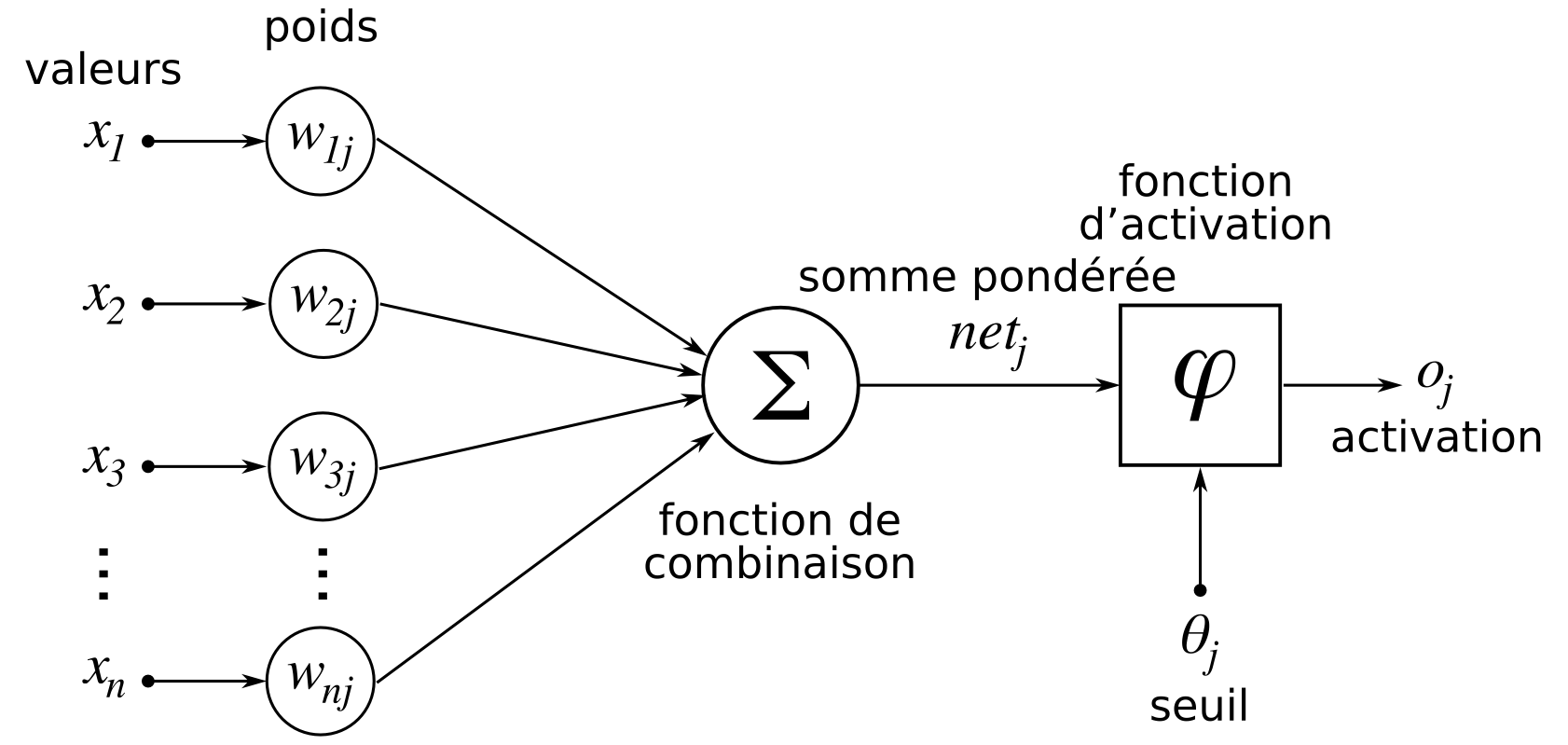
Quelques années plus tard, l’idée du neurone artificiel (ou neurone formel) fut appliquée à un problème de classification binaire : l’algorithme obtenu se nomme le perceptron.
L’activation d’un neurone dans le cadre d’un perceptron correspond donc à une des deux classes que l’on cherche à prédire. L’apprentissage d’un perceptron correspond à trouver les poids (ou coefficients) du neurone qui permettent de renvoyer la valeur voulue et donc la bonne classe. A l’instar du cerveau humain qui est constitué d’un grand nombre de neurones interconnectés entre eux, on s’est donc vite rendu compte qu’utiliser plusieurs neurones donnait de meilleurs résultats. Cela a donc conduit à des perceptrons avec une couche de neurones et non plus un neurone unique.
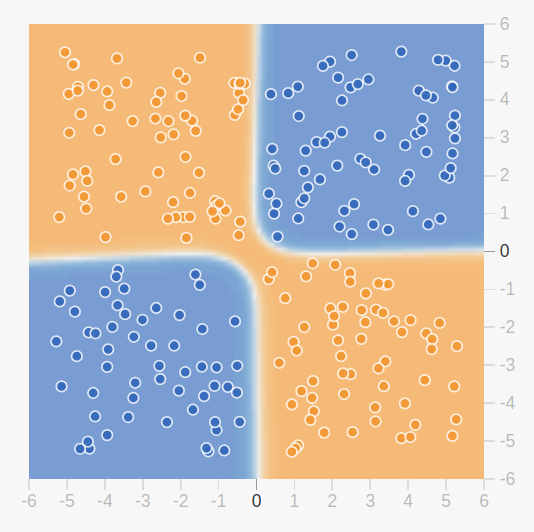
A l’époque, les perceptrons permettaient de résoudre des problèmes de classification binaire simples mais étaient limités par leur incapabilité à résoudre certains types de problèmes (comme la fonction XOR ci dessous).
Le réseau de neurones multi-couches
Pour résoudre ce problème, il est nécessaire de passer d’un perceptron ayant une couche de neurones, à un réseau de neurones avec plusieurs couches ; le perceptron multi-couches. Cependant, le fait d’ajouter des couches à un perceptron rend l’apprentissage de celui-ci plus difficile.
La méthode pour apprendre ce type de réseaux de neurones, appelée rétropropagation du gradient, fut appliquée à un réseau de neurones avec succès pour la première fois au milieu des années 80. Pour rappel, l’apprentissage d’un perceptron consiste à trouver les valeurs des poids des neurones. L’apprentissage d’un perceptron multi-couches correspond donc à trouver les valeurs des poids de l’ensemble des neurones constituant le réseau, ce qui peut potentiellement faire un nombre de poids très important à trouver.
Cette méthode a permis aux réseaux de neurones d’être vraiment utiles pour la première fois en résolvant des problèmes importants comme la reconnaissance optique de chiffres sur des chèques par exemple.
Cependant, il s’est avéré relativement rapidement que, pour résoudre des problèmes plus complexes, il était nécessaire de multiplier les couches dans les réseaux de neurones. Le problème est que cette complexification des réseaux de neurones entraîne deux difficultés :
- Plus le réseau a de couches (plus il est profond), plus il faut de puissance de calcul pour pouvoir faire l’apprentissage et l’utiliser.
- Plus le réseau est profond, moins l’algorithme d’apprentissage (la rétropropagation du gradient) fonctionne correctement.
Ces deux difficultés ont limité l’acceptation et l’utilisation des réseaux de neurones pendant près de deux décennies. En effet, il était fréquent de devoir utiliser des réseaux pour lesquels on ne parvenait pas à faire correctement l’apprentissage.
Le succès des années 2000
La méthode a connu un regain d’intérêt au milieu des années 2000 quand il fut prouvé qu’il était possible de faire un pré-apprentissage des réseaux de neurones profonds grâce à des méthodes non supervisées.
Ce pré-entraînement permettait de réduire les difficultés d’apprentissage connues précédemment sur les réseaux profonds. C’est cette découverte qui a permis de relancer quelque peu la recherche dans le domaine, alors qu’une solution à l’autre problème commençait à apparaître : l’utilisation des cartes graphiques pour faire les calculs.
Les cartes graphiques sont des composants des ordinateurs qui gèrent l’affichage des informations à l’écran. Ces composants sont pensés pour pouvoir effectuer en parallèle un grand nombre de calculs mathématiques simples. Or, il s’avère justement que l’apprentissage et l’utilisation d’un réseau de neurones requiert un très grand nombre de calculs mathématiques très simples, et que ceux-ci peuvent être en grande partie parallélisés. Les cartes graphiques (ou GPU) sont donc des composants bien plus adaptés que les processeurs classiques pour l’apprentissage et l’utilisation des réseaux de neurones.
L'avènement grâce à ImageNet
Cependant, l’événement qui déclencha vraiment le renouveau des réseaux de neurones ainsi que l’apparition du terme Deep Learning fut le concours de reconnaissance et classification d’images ImageNet de 2012. Ce concours, effectué tous les ans, met en compétition des équipes de recherche du monde entier pour classifier automatiquement des images selon 1000 catégories différentes.
En 2012, l’équipe qui l’ emporté l’a fait avec un réseau de neurone profond, une première pour cette compétition. En effet, la grande complexité de la tâche semblait jusque-là trop importante pour pouvoir utiliser des réseaux de neurones. Fait marquant, la solution de cette équipe faisait presque moitié moins d’erreurs que celle de l’équipe en seconde position du concours.
Leur solution se basait sur un réseau de neurones très profond pour l’époque (8 couches). L’apprentissage du réseau fut possible grâce à l’utilisation de GPUs et grâce à un ensemble de nouvelles techniques permettant de faciliter l’utilisation de la rétropropagation du gradient (notamment en changeant la façon dont les neurones retournent leur valeur d’activation).
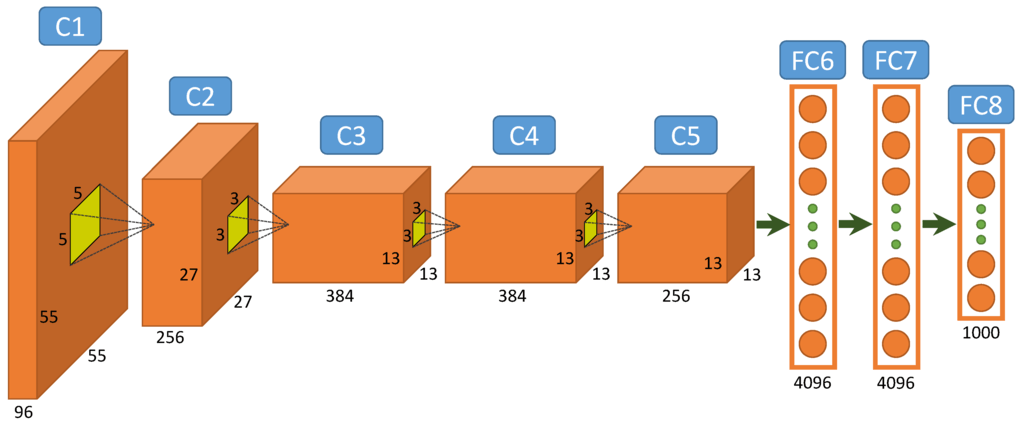
L’année suivante, toutes les meilleures équipes utilisaient des réseaux de neurones et aujourd’hui, plus personne n’utilise de méthodes différentes pour cette compétition.
Les réseaux de neurones profonds (ou Deep Learning, le mot “Deep” faisant référence à la profondeur des réseaux, c’est à dire à leur grand nombre de couches) trouvent donc leurs origines dans des approches relativement anciennes, mais leur exposition actuelle est due à un ensemble de nouvelles avancées technologiques et algorithmiques très récentes.
Définition du Deep Learning
Depuis quelques années, le Deep Learning est particulièrement mis en avant dans les médias à travers ses applications en Intelligence Artificielle. Cette discipline, sous-domaine du Machine Learning, a remis depuis peu à elle seule l’IA sur le devant le scène. Aujourd’hui, la recherche dans le domaine est presque intégralement focalisée sur le Deep Learning, ayant notamment permis des avancées majeures en traitement d’image et de texte. Essayons de voir ce qui se cache derrière ce terme devenu aujourd’hui populaire et qui reste malgré tout abstrait et mystérieux.
Les bases du Deep Learning : le Machine Learning
Le Machine Learning “classique” a pour objectif de donner à une machine la capacité d’apprendre à résoudre un problème sans devoir programmer explicitement chaque règle. L’idée du Machine Learning est donc de résoudre des problèmes en modélisant des comportements grâce à un apprentissage basé sur des données.
Cependant, avant de pouvoir modéliser un problème à travers un algorithme de Machine Learning, il est souvent nécessaire d’effectuer un bon nombre de transformations sur les données. Ces transformations, qui sont faites manuellement, sont dictées par le problème métier que l’on cherche à résoudre, et par le choix de l’algorithme utilisé. Ce traitement de données (communément appelé feature engineering en anglais) est souvent très chronophage et peut nécessiter une expertise métier afin d’être pertinent.
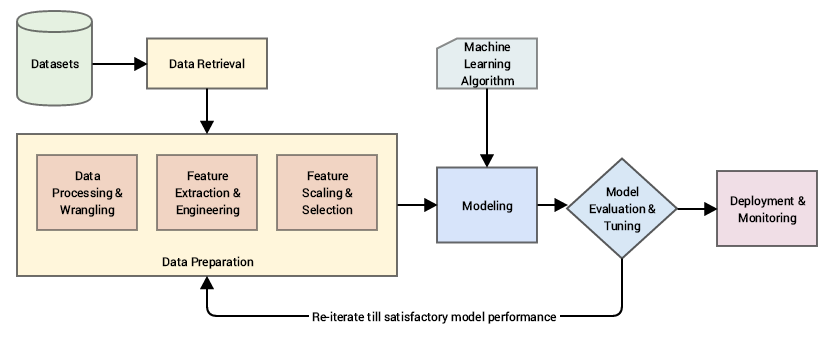
On peut voir ces transformations de données comme la construction d’une représentation du problème qui pourra être facilement comprise et interprétée par l’algorithme de Machine Learning.
A quoi sert le Deep Learning ?
L’idée du Deep Learning est de construire automatiquement cette représentation pertinente des données à travers la phase d’apprentissage, évitant ainsi une intervention humaine. On parle donc d’apprentissage par représentation. Un algorithme de Deep Learning va apprendre des représentations hiérarchiques de plus en plus complexes de données. Ce type d’algorithme est donc adapté aux données de signaux (Images, textes, sons,…), car, par essence, celles-ci sont très hiérarchiques.
Comment fonctionne le Deep Learning ?
Les réseaux de neurones profonds ne sont pas un simple empilement de couches de neurones. En effet, pour résoudre des problèmes de plus en plus complexes, il n’est pas suffisant d’ajouter toujours plus de couches. Les deux grosses problématiques des réseaux de neurones, qui sont la difficulté d’apprentissage et la complexité calculatoire croissante avec le nombre de couches, sont en effet toujours présentes. Les solutions apportées par les recherches récentes permettent de limiter ces problèmes mais pas de les régler complètement.
Il est donc nécessaire de présenter des approches différentes suivant les problèmes que l’on cherche à résoudre. Il existe en pratique différents types de réseaux de neurones profonds qui visent à résoudre différents problèmes.
Analyse d'image
Par exemple, pour analyser les images de façon pertinente, il est important d’analyser la hiérarchie des objets définis par les pixels plutôt que chaque pixel séparément. Les réseaux de neurones qui analysent les images sont appelés réseaux convolutionnels puisqu’ils utilisent des couches de neurones particulières appelées couches de convolutions. Ces couches de neurones scannent en quelque sorte l’image pour détecter les caractéristiques intéressantes de celle-ci (pour le problème à résoudre). La superposition de plusieurs couches de convolution permet de détecter des caractéristiques hiérarchiques de plus en plus complexes dans une image.
AlexNet, le réseau de neurones ayant remporté ImageNet en 2012, était un réseau de neurones convolutionnels profond composé de 5 couches de convolutions et de trois couches de neurones plus classiques.

Les cas d’usages les plus fréquents en analyse d’image sont la classification d’images (trouver la catégorie de l’objet principal de l’image), la détection d’objets (trouver où sont situés tous les objets de l’image, ainsi que leur catégorie) et la segmentation d’image (déterminer pour chaque pixel de l’image à quelle catégorie il appartient). Ces trois cas d’usage présentent une complexité croissante. Cependant, avec suffisamment de données, les réseaux de neurones actuels permettent d’obtenir des performances similaires à celles des humains, voire supérieures pour ces problématiques.
Traitement de texte
Les données textuelles ont une complexité supplémentaire qui est liée à leur structure ordonnée. Il y a en effet une temporalité dans du texte. La compréhension d’une phrase dans un paragraphe peut nécessiter de connaître le contexte et donc d’avoir compris les phrases précédentes de ce paragraphe.
Les réseaux de neurones qui permettent de traiter ce type de données temporelles sont appelées réseaux récurrents. Ces réseaux analysent les mots du texte un par un (voir les caractères pour certains) et gardent en mémoire les informations qui semblent pertinentes. Comme pour les réseaux de neurones plus classiques, les réseaux récurrents se basent sur une théorie antérieure à l’ère du Deep Learning. En effet, les réseaux récurrents les plus fréquemment utilisés sont appelées LSTM (Long Short Term Memory) et ils ont été inventés en 1997. La puissance de calcul ainsi que de nouvelles méthodes pour faciliter l’apprentissage ont encore une fois permis leur application à plus grande échelle depuis 2012.
Les cas d’usages les plus fréquents en analyse textuelle sont la classification de texte (de quoi parle le texte ?), l’analyse de sentiment (le texte est-il positif ou négatif ?), la traduction automatique et la modélisation de langage (quel est le prochain mot ou le prochain caractère de ce texte ?). Sur certains cas d’usages comme la classification ou la traduction, les réseaux de neurones présentent des performances qui se rapprochent de celles des humains. Néanmoins, il y a encore des tâches pour lesquelles les réseaux en sont loin, comme par exemple l’analyse de sentiment lorsque de l’ironie est en jeu.
Auto Encoders
Les réseaux de neurones ne se limitent pas forcément à des problématiques d’apprentissage supervisé, même si cela reste leur utilisation principale. En effet, il existe aussi des réseaux de neurones qui permettent de faire de l’apprentissage non supervisé.
Les plus utilisés dans ce domaine sont probablement les Auto Encoders. Ces réseaux n’ont pas pour objectif de prédire ce qui se trouve dans une image ou un texte mais seulement de chercher à trouver une représentation pertinente et compressée de l’image ou du texte en tirant justement parti du pouvoir de représentation des réseaux de neurones.
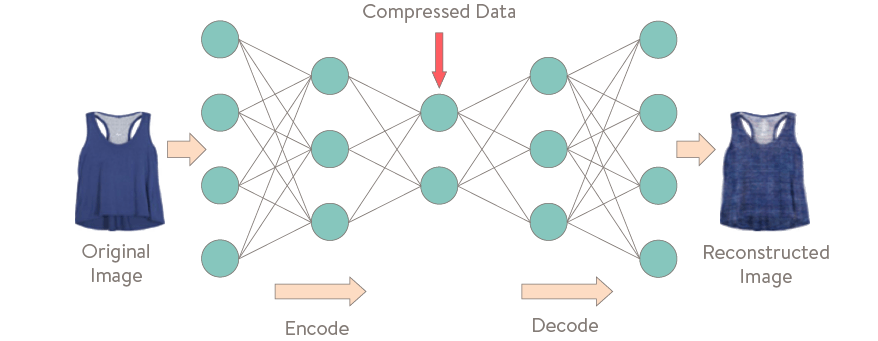
Le but d’un Auto Encoder est d’être capable de régénérer intégralement les données passées en entrée. La représentation trouvée par le réseaux de neurones doit donc contenir assez d’informations pour être capable de faire la génération. L’objectif de reconstruction force la représentation compressée intermédiaire à être pertinente. Les représentations trouvées par l’Auto Encoder pourront ensuite être utilisées pour d’autres tâches, comme de la classification par exemple.
GANs
Enfin, il existe aussi des modèles capables de générer du nouveau contenu. Le but de ces réseaux de neurones est de comprendre la structure de données dans un cadre non supervisé. L’idée sur laquelle se basent ces réseaux est que si l’on est capable de générer du contenu qui est indiscernable des données initiales, c’est que l’on a réussi à comprendre la structure de ces données.
Les GANs (Generative adversarial networks) ou réseaux antagonistes génératifs sont probablement les réseaux génératifs les plus prometteurs. L’apprentissage d’une telle tâche est difficile et passe par l’utilisation de deux réseaux antagonistes. Un des deux réseaux a pour objectif de générer des données aussi proches que possible de la réalité alors que le but du deuxième réseau est d’être capable de faire la distinction entre les vraies données et les données générées par le premier réseau. Les réseaux sont dits antagonistes car ils sont en compétition au cours de l’apprentissage. En entraînant les deux réseaux en parallèle, ils s’améliorent chacun dans leur tâche respective. A la fin de l’apprentissage, on obtient ainsi un réseau capable de générer des données très proches de la réalité.

Les GANs ont été utilisés avec succès pour générer des données mais aussi entre autres pour coloriser des images en noir et blanc, pour augmenter la résolution d’images ou reconstruire des images partiellement effacées. Cependant, la très grande difficulté d’apprentissage des GANs limite encore beaucoup leur potentiel qui semble pourtant très prometteur.
Deeper is better ?
Pourquoi le Deep Learning fonctionne si bien comparé aux algorithmes plus classiques de Machine Learning ? Une première partie de réponse semble être la nature d’algorithme d’apprentissage par représentation du Deep Learning. En effet, cette façon d’apprendre permet de construire automatiquement les caractéristiques les plus utiles pour résoudre un problème. Le travail manuel d’ingénierie des données est donc beaucoup moins présent lorsque l’on utilise du Deep Learning plutôt que des algorithmes de Machine Learning plus classiques. Cette absence de travail manuel permet de tirer pleinement profit des volumes de données très importants et de la puissance de calcul qui sont désormais à disposition depuis l’émergence du Big Data.
Une seconde partie de réponse pourrait se trouver dans la capacité de généralisation du Deep Learning. En effet, contrairement aux algorithmes plus classiques, qui apprennent des solutions ne fonctionnant que pour un seul problème, les solutions trouvées par les réseaux de neurones profonds peuvent souvent être appliquées à d’autres tâches similaires (moyennant quelques adaptations). On appelle cela le Transfert Learning. Il est ainsi par exemple possible d’utiliser des réseaux de neurones ayant été appris sur les images de la compétition ImageNet et de les réadapter pour qu’ils puissent reconnaître de nouveaux types d’objets. Cette méthode permet de gagner du temps puisqu’il n’est pas nécessaire de tout apprendre au réseau, la base des connaissances lui permettant de distinguer une image d’une autre ayant déjà été apprise.
Cette capacité de transfert de tâche est possible encore une fois grâce aux représentations hiérarchiques de plus en plus complexes obtenues durant la phase d’apprentissage. En effet, les premières couches des réseaux de neurones apprennent à chercher des caractéristiques très simples dans les images (des droites, des courbes, des couleurs, etc…). Ces premières caractéristiques sont en grande partie indépendantes du problème à résoudre, elles sont donc pertinentes et réutilisables pour un grand nombre de tâches différentes. Lorsque l’on fait du Transfert Learning, on coupe en quelque sorte la partie du réseau qui est spécifique à une tâche particulière et on garde la partie généraliste.
L’apprentissage de très gros réseaux de neurones étant un processus long et compliqué, le transfert learning a très probablement eu un rôle vraiment important dans la démocratisation du Deep Learning.
Les perspectives d'avenir du Deep Learning
Maintenant que vous êtes à l’aise avec le Deep Learning et que vous en connaissez mêmes les origines, il est temps de s’intéresser à son avenir. La Recherche actuelle dans le domaine est exceptionnellement active et de nouvelles architectures de réseaux de neurones, de nouveaux types de couches et de nouvelles techniques d’apprentissage apparaissent très régulièrement. Les performances des réseaux depuis AlexNet en 2012 n’ont pas cessé de s’améliorer de façon assez impressionnante.
La preuve, les situations où le Deep Learning bat l’humain se multiplient (Go, Poker, Jeux videos, etc…), même dans des domaines où la suprématie de l’humain sur l’algorithmie semblait indiscutable. Et pourtant, il reste de très nombreuses pistes d’améliorations pour le Deep Learning. En voici quelques unes.
L'interprétabilité
En analyse d'images
Une de ces pistes est liée à la compréhension des réseaux de neurones. Les algorithmes de Deep Learning sont assimilés à des boîtes noires. C’est-à-dire que lorsque un réseau de neurones prend une décision, il est difficile d’expliquer pourquoi celle-ci a été prise. En effet, la décision d’un réseau de neurones passe par l’activation ou non de milliers de neurones, il n’est donc pas humainement possible de tout analyser.
Une autre difficulté se trouve dans les représentations apprises par les réseaux de neurones. En effet, celles-ci sont abstraites pour les humains, elles ne sont pas lisibles et compréhensibles (on dit qu’elles ne sont pas symboliques). Ainsi, quand un neurone s’active, il est difficile d’expliquer pourquoi. La Recherche dans ce domaine a réussi à régler en partie ce problème en trouvant une méthode pour générer des images fictives qui activent fortement certains neurones. Avec cette méthode, il devient possible de comprendre ce que chaque neurone cherche dans une image.
Une autre approche pour améliorer l’interprétabilité des réseaux de neurones est d’étudier les zones de l’image en entrée qui ont intéressé le réseau. Cela peut permettre de détecter des problèmes dans l’apprentissage du réseau si l’on découvre qu’il s’intéresse à des régions ou des caractéristiques dans des images qui n’ont aucun sens.


En analyse de texte
Lorsque l’on travaille sur de l’analyse textuelle, il est aussi possible d’analyser à quel moment chaque neurone s’active et donc de comprendre ce qu’ont appris ces neurones.

On se rend compte que ces méthodes sont des explications à posteriori des réseaux de neurones. Une fois que l’apprentissage d’un réseau est fini, on cherche à le comprendre en analysant ses composants. Ces méthodes sont encore très manuelles et peu viables à grande échelle. Il reste encore beaucoup de travail pour être capable d’interpréter de façon fiable et robuste les comportements des réseaux de neurones.
En terme de sécurité
Une autre piste d’amélioration est la robustesse des réseaux de neurones contre les attaques. Il est aujourd’hui relativement facile d’apprendre à tromper un réseau de neurones si l’on a accès à l’ensemble de ces poids. Il devient possible de trouver des failles dans le réseau et de modifier très légèrement une image pour la faire passer pour autre chose. Un humain ne verrait pas la différence, mais pour le réseau, il s’agit d’une tout autre image.
Il existe d’autres types d’attaques des réseaux, par exemple les attaques par patch. Il s’agit d’appliquer un patch spécial sur n’importe quelle image pour tromper le réseau. Le patch est construit de façon à être extrêmement spécifique pour le réseau, il va ainsi en quelque sorte écraser toutes les autres caractéristiques de l’image. Ainsi un patch spécifique “grille pain” fera passer n’importe qu’elle image pour une image de grille pain.
Ces types d’attaques pourraient avoir des répercussions critiques dans des systèmes où les réseaux de neurones aident à prendre des décisions importantes (dans les véhicules autonomes par exemples). Il faut cependant relativiser leur impact, pour pouvoir mettre en place ces attaques, il est nécessaire d’obtenir des informations sur le réseau qui, en théorie, ne sont pas accessibles. Il s’agit cependant quand même d’un réel problème, beaucoup de recherche est donc faite (avec succès), pour limiter ou bloquer les effets de ces attaques.
L'apprentissage des réseaux
D’autres pistes visent à améliorer le point faible des réseaux de neurones profond : la très grande quantité de données nécessaire à l’apprentissage. En effet, le Deep Learning, qui se veut quelque peu inspiré du cerveau est (encore) incapable d’apprendre aussi bien que celui-ci.
Few-shot Learning
C’est pourquoi des approches visent à faciliter l’apprentissage pour pouvoir résoudre les problèmes où il n’est pas possible d’avoir un grand nombre d’échantillons labellisés. Il est nécessaire dans ces conditions de réussir à faire apprendre un réseau avec très peu d’exemples. On parle de Few-shot Learning (ou K-shot learning). En général ces méthodes se basent sur l’idée du Transfert Learning (si un réseau de neurone sait déjà résoudre une tâche, il est possible de lui apprendre à en résoudre une autre similaire avec peu d’exemples).
Ces approches cherchent à s’adapter aux types de données auxquels on a aujourd’hui accès. L’immense majorité des données produites actuellement est soit non supervisée (aucun label n’est associé aux données), soit semi-supervisée (il y a quelques labels mais une majorité de données non labellisées). En réussissant à tirer parti des connaissances et des informations contenues dans ces données, il pourrait devenir possible de construire des modèles bien plus complexes et performants que ceux que l’on a actuellement.
Multi Task Learning
Dans l’optique d’obtenir les réseaux les plus génériques possibles, certaines approches s’intéressent aussi à l’idée d’apprendre à résoudre en même temps plusieurs tâches différentes (on parle de Multi Task Learning). Ce genre d’approche paraît très prometteuse puisque les humains semblent apprendre de cette façon. En effet, en étant capable de comprendre les similarités entre différents problèmes, on devient capable de résoudre ceux-ci de manière plus rapide et plus performante.
Enfin, un certain nombre d’approches cherchent à rapprocher le fonctionnement des réseaux de neurones profonds du fonctionnement du cerveau humain. Un enfant est capable d’apprendre une langue de façon extrêmement rapide et avec une quantité de données très faible. De même, il sera capable de comprendre de nouveaux concepts en observant, et sans avoir besoin qu’on lui explicite chaque détail un grand nombre de fois. L’apprentissage humain est donc bien plus performant que celui du Deep Learning et il est de plus largement non supervisé. Nous ne comprenons pas vraiment comment fonctionne le cerveau humain durant l’apprentissage mais il est relativement sûr de penser que les mécanismes utilisés sont différents de ceux présents dans le Deep Learning. Presque tous les réseaux de neurones profonds actuels sont appris avec l’algorithme de rétropropagation du gradient et bon nombre de chercheurs pensent que c’est en trouvant un meilleur moyen de faire cet apprentissage que l’on pourra améliorer les performances et se rapprocher du fonctionnement du cerveau humain. De nouvelles méthodes commencent à émerger, comme de l’apprentissage des réseaux par renforcement ou par des algorithmes génétiques, et il est probable que les années à venir voient de nouvelles avancées dans ce domaine.
L'analyse des connaissances
Pour finir, il semble intéressant de s’attarder sur un exemple donnée par Andrej Karpathy (actuellement directeur de l’IA chez Tesla) sur l’analyse des connaissances. Il y présente cette image.

Cette image est amusante. Mais elle l’est seulement pour un humain. En effet, la quantité d’informations qu’il est nécessaire de connaître et comprendre pour pouvoir analyser cette image est très importante. Un humain fait cette analyse sans même s’en rendre compte mais c’est quasiment impossible pour les machines actuelles. Une petite liste non exhaustive de ce qu’il faut comprendre:
- Il y a des hommes en costume dans un couloir.
- Il y a de nombreux miroirs dans la pièce et donc certaines personnes sont seulement des reflets.
- L’homme au milieu est Barack Obama.
- Il était président des Etats Unis au moment de la photographie.
- Un homme est sur une balance, en train de se peser.
- Barack Obama a son pied sur la balance et appuie dessus.
- Les lois de la physiques impliquent que le poids affiché sur la balance sera plus important.
- On sent que la personne sur la balance est troublée car le poids affiché n’est pas celui qu’elle connaît.
- Les personnes du fond sont amusées de voir la confusion de la personne sur la balance.
- Un président ne fait, en général, pas ce genre d’action, ce qui rend l’image plus amusante.
En allant encore plus en détails, on réalise la complexité de la tâche de compréhension de ce type d’image, tâche pourtant évidente pour un humain.
Pour qu’une machine puisse comprendre ce genre d’image, en plus de reconnaître tous les objets et personnes présentes, il est nécessaire qu’elle ait accès à de vastes connaissances et qu’elle soit capable de les traiter. La représentation des connaissances et leur traitement en IA se sont beaucoup basés sur la manipulation de nombreuses règles symboliques manuelles. Ces systèmes sont souvent très longs et compliqués à mettre en place en plus de demander une implication humaine importante. Il faudra probablement réussir à s’abstraire de ces règles symboliques pour obtenir des systèmes capables de comprendre les images comme celle ci-dessus.
Le futur de l’IA pourrait donc passer par des systèmes combinant de l’apprentissage par représentation (du Deep Learning) avec des moyens de raisonnement complexe. Il reste cependant encore beaucoup de travail.
Vous pouvez utiliser Saagie afin de vous accompagner dans vos projets deep learning et data science. Saagie est une plateforme DataOps qui facilite le déploiement et l’exécution de modèles de deep learning. Grâce à ses fonctionnalités avancées de gestion des clusters et de suivi des performances, notre plateforme permet aux utilisateurs de tirer pleinement parti des avantages du deep learning pour des applications variées.





