
En Data Science et en probabilités, on est amené à modéliser un grand nombre de données ou un échantillon de valeurs, aléatoires (random en anglais) ou non. Pour cela, plusieurs études sont possibles : le calcul de la moyenne (mean en anglais), de la médiane (median en anglais), de la variance ou de l’écart-type, en fonction de la taille de la population étudiée.
Nous allons donc voir comment modéliser les données en Python notamment grâce à la loi normale ou loi de Gauss.
1. Définition de la loi normale ou loi de Gauss
La loi normale, aussi appelée loi de Gauss ou loi de Laplace-Gauss, est parmi les lois de probabilité les plus utilisées pour modéliser des phénomènes naturels issus de plusieurs nombres aléatoires.
Pas toujours connue dans le monde de la data, la formule de la loi normale est :
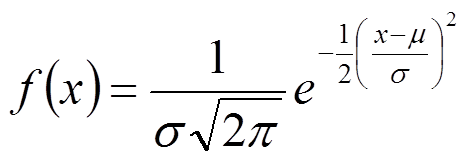
où m représente l’espérance et sigma est l’écart type.
2. Les différents types de modélisation de données
Il existe trois types principaux de modélisation de données :
- La régression linéaire permet de modéliser une donnée quantitative à partir de variables explicatives quantitatives.
- La classification supervisée permet d’expliquer une variable qualitative à partir de variables explicatives quantitatives.
- La classification supervisée permet d’expliquer une variable qualitative à partir de variables explicatives quantitatives.
3. La modélisation d’une distribution de données en Python avec SciPy
Nous allons voir comment modéliser un échantillon de données ou une distribution grâce à la librairie SciPy de Python.
A. Modéliser une distribution
La modélisation de la distribution de données, aussi appelée probability distribution fitting en anglais, est le fait de trouver les paramètres de la ou des lois de distribution de probabilités qui correspondent aux données que l’on cherche à modéliser. Il s’agit donc de savoir quelle loi ou quelle distribution les données suivent comme une loi normale ou une loi gamma, par exemple, puis d’en trouver les paramètres.
Modéliser la distribution normale de nos données permet ensuite de déterminer la fréquence d’occurrence d’un événement.
B. Qu’est-ce que Scipy ?
SciPy (Scientific Python) est une bibliothèque open source créée en 2001 et dédiée aux calculs de mathématiques complexes ou aux problèmes scientifiques.
Une fonction mathématique native et des bibliothèques peuvent être utilisées en science et en ingénierie pour résoudre différents types de problèmes. Elle intègre des algorithmes préinstallés pour l’optimisation, les équations différentielles, l’intégration, les statistiques…
SciPy est une extension de NumPy (Numerical Python), dont nous vous parlions dans un article précédent. Elle permet donc un traitement de données extrêmement rapide et efficace. On utilise SciPy pour la Data Science et d’autres domaines d’ingénierie, car elle contient les fonctions optimisées nécessaires et fait office d’extension de NumPy. Cet outil peut être utilisé pour résoudre une large variété de problèmes scientifiques.
C. Modéliser les données en Python avec SciPy
Il est possible de modéliser un échantillon de données avec la librairie SciPy. Il faut commencer par ajouter la librairie dans le code :
from scipy import stats
Il existe de nombreuses distributions continues (expon, gamma, norm, uniform…) et discrètes (binom, geom, hypergeom…). Pour afficher la documentation d’une distribution, il suffit d’écrire le code suivant :
print(stats.[NOM].__doc__)
Les méthodes les plus courantes pour les distributions continues sont :
stats.norm.median(loc=0, scale=1) : médiane de la distribution
stats.norm.mean(loc=0, scale=1) : moyenne de la distribution
stats.norm.var(loc=0, scale=1) : variance de la distribution
stats.norm.std(loc=0, scale=1) : écart-type de la distribution
Un exemple de code pour afficher une loi normale de moyenne 5.3 et de variance 1 en Python :
# import des librairies
from scipy.stats import norm
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
# Creation de la distribution
data = np.arange(1,10,0.01)
pdf = norm.pdf(data , loc = 5.3 , scale = 1)
#Visualization de la distribution
sb.set_style(‘whitegrid’)
sb.lineplot(data, pdf , color = ‘black’)
plt.xlabel(‘Heights’)
plt.ylabel(‘Probability Density’)
D. Présenter un résultat en Python avec Dash
Il est possible de présenter un résultat dans une web app en Python grâce à la librairie Dash. Une fonction de Dash est d’ajouter de nombreux composants au code de vos web apps, des tags HTML, mais aussi des graphes, des tableaux interactifs (Data Table), avec par exemple une variable aléatoire, des menus déroulants avec beaucoup de variables de customisation à chaque fois.
Nous avons donc vu comment calculer une moyenne (mean), une médiane (median), une variance (var), un écart-type (std) et une loi normale en Python en utilisant SciPy.
Pour cela, il ne faut pas oublier d’importer la librairie avec from scipy import stats et d’afficher vos résultats (print). Vous pourrez ainsi modéliser vos données et calculer des probabilités quelle que soit la taille de votre échantillon de population.





