
Dans cette série d’article, nous verrons comment faire du Machine Learning simplement, par le biais de requêtes SQL dans BigQuery. Pour ce faire, nous nous intéresserons à la tâche d’analyse de sentiments dans des revues IMDB. Nous utiliserons la régression logistique, un des modèles facilement accessible sur BigQuery ML.
Nous allons donc suivre rigoureusement toutes les étapes du processus de l’analyse de sentiments, c’est-à-dire l’envoi des données sur BigQuery, le nettoyage et la préparation des données, la mise en place du modèle de régression logistique, ainsi que son évaluation approfondie pour assurer la fiabilité des résultats obtenus.
Nous explorerons deux méthodes possibles : utiliser directement BigQuery, ou bien passer par l’orchestrateur Saagie afin de réaliser les différentes tâches de manière automatisée sous forme de Pipeline. Le premier article de cette série se concentre sur l’envoi des données dans BigQuery.
Qu’est ce que le Machine Learning ?
Comme nous l’avons vu précédemment dans cet article, Le ML est une sous-catégorie de l’intelligence artificielle qui correspond à l’apprentissage d’une machine ou d’un algorithme. Nous pouvons en distinguer trois sous-catégories :
- l’apprentissage supervisé, qui permet d’apprendre un modèle à partir de données labellisées (ou étiquetées)
- l’apprentissage non supervisé, pour lequel aucune étiquette indiquant la bonne réponse à prédire n’est disponible
- et l’apprentissage par renforcement, dans lequel le modèle a un objectif à réaliser, et tente d’apprendre le comportement le plus efficace pour atteindre cet objectif
À ces trois catégories, nous pouvons également ajouter d’autres types d’apprentissage qui s’inspirent des précédents.
Par exemple, pour l’apprentissage auto-supervisé, il n’y a pas de réel étiquetage des données, mais une labellisation qui est “déduite” des données. Ainsi, pour le modèle de langue BERT, l’une de ses deux tâches d’entraînement est le Mask Language Modeling : un token est masqué dans les phases du jeu de données d’apprentissage, le modèle apprend donc la représentation d’une langue en essayant de prédire ces tokens masqués.
Maintenant que nous avons démystifié ce qu’est le Machine Learning, plongeons dans les raisons pour lesquelles cela suscite tant d’intérêt pour les entreprises.
Les Multiples Avantages du Machine Learning
L’intégration du Machine Learning a révolutionné la façon dont les entreprises abordent l’analyse des données et la résolution de problèmes complexes. En exploitant les algorithmes et les modèles prédictifs, le Machine Learning offre une perspective inédite sur les données, ouvrant la voie à des décisions plus éclairées et à des innovations surprenantes.
En effet, selon Amazon AWS, le machine learning “aide les entreprises en stimulant la croissance, en débloquant de nouvelles sources de revenus et en trouvant des solutions à des problèmes complexes”. Cela permet donc aux organisations de traiter rapidement d’importantes quantités de données de manière automatisée.

Cependant, l’utilisation des algorithmes de Machine Learning nécessite un minimum de connaissances en statistiques et en apprentissage automatique, ainsi que des compétences en programmation, notamment en Python ou R. Ces compétences sont essentielles pour la sélection, la mise en place et l’ajustement des modèles de Machine Learning en fonction des besoins spécifiques de l’entreprise.
De plus, il est important de noter que l’étape du Machine Learning s’intègre généralement dans un pipeline de données, qui est une série d’étapes de traitement visant à préparer les données de l’entreprise pour l’analyse. Ce pipeline peut inclure des processus tels que la collecte, la transformation, la normalisation et la préparation des données. Une solide compréhension de ces étapes est nécessaire pour garantir la qualité des données et l’efficacité du processus.
En outre, la gestion de l’enchaînement de ces différentes étapes dans le pipeline de données est cruciale. Cela implique souvent l’utilisation d’outils d’orchestration et de gestion de flux de travail pour garantir la cohérence et la traçabilité de tout le processus. Une coordination efficace permet de garantir que les données sont préparées de manière fiable pour l’analyse ultérieure, maximisant ainsi la valeur des informations extraites à partir des données de l’entreprise.
C’est là qu’interviennent BigQuery et Saagie. BigQuery est une puissante plateforme d’analyse de données dans le cloud de Google. En ce qui concerne Saagie, c’est une plateforme DataOps d’orchestration de données qui simplifie et automatise le traitement de données à l’échelle de l’entreprise. Dans cet article, nous verrons que combinées ensemble, Saagie et BigQuery permettent de mettre en place rapidement et simplement un modèle de ML, même sans avoir le profil d’un Data scientist, en SQL.
Optimisation de Données : BigQuery et Saagie en Action !
Qu’est ce que BigQuery ?
BigQuery est une puissante base de données dans le cloud proposée par Google Cloud. Elle permet d’analyser rapidement et efficacement d’énormes volumes de données, en offrant une évolutivité impressionnante, une intégration fluide avec d’autres services cloud, et une sécurité de premier ordre. Grâce à sa vitesse de traitement et à ses capacités d’analyse en temps réel, BigQuery est l’outil idéal pour obtenir des informations précieuses à partir de vos données.
BigQuery ML permet la création de modèle de Machine Learning de manière simple, puisqu’il suffit d’avoir des connaissances en SQL. Plusieurs modèles classiques/traditionnels sont disponibles en interne (Régression linéaire, Régression logistique, Clustering des k-moyennes, Factorisation matricielle, Analyse des composants principaux (PCA), Série temporelle), mais il est également possible d’utiliser des modèles de Deep Learning à l’état de l’art grâce au Jardin des modèles, ou même des modèles entraînés en externe, le tout grâce à Vertex AI.
Les bénéfices de l’orchestration de BigQuery dans Saagie
Saagie est une Plateforme DataOps qui permet le design et l’orchestration de Pipelines de données. En effet, comme nous l’avons vu précédemment, les données doivent être déplacées, triées, filtrées, reformatées et analysées pour le Machine Learning. Les taches de Machine Learning peuvent elles même être organisées sous forme de pipeline. Dans cette optique, Saagie se place au-dessus de BigQuery, permettant ainsi d’orchestrer les différentes tâches nécessaires à l’analyse de données.
Google Cloud propose également ses propres outils de Design et d’Orchestration de Pipelines comme Composer et Workflow. Composer est notamment développé au-dessus de Airflow (un workflow manager Open source très populaire) et est conçu pour les développeurs. Son interface est donc très technique et requiert beaucoup de configuration pour commencer à l’utiliser. Contrairement à Composer, Saagie est beaucoup plus intuitif et accessible : vous pouvez démarrer avec Saagie en quelques clics.

Saagie propose également de nombreux outils pour mieux développer et gérer vos Pipelines de Machine Learning. La plupart de ces outils sont OpenSources (MLflow, Jupyter Notebooks, Hugging Face), et sont les meilleurs de leur catégorie. À l’inverse, Google vous enferme dans les outils GCP avec les risques de Lock-In associés.
Dernier point, le troubleshooting. Google Composer ne permet pas facilement de comprendre ce qui se passe dans vos pipelines. En cas d’erreur, la collecte de logs n’est pas intuitive et requiert par exemple de mettre en place un composant de collecte de logs, ce qui n’est pas le cas avec Saagie.
D’autres fonctionnalités dans Saagie permettent de mieux gérer la création de Pipeline de Machine Learning dans BigQuery (Resume, Pipeline conditions…). Et bien sûr, Saagie permet facilement l’intégration des bonnes pratiques de développement comme la CICD en proposant plusieurs environnements isolés DEV, PreProd, PROD… avec une intégration poussée avec GitHub, GitLab…
Ainsi, en utilisant Saagie pour orchestrer les différentes tâches liées à l’analyse de données, on peut efficacement simplifier et automatiser le processus. En se plaçant au-dessus de BigQuery, Saagie permet une gestion harmonieuse des pipelines de données, offrant une approche intuitive et accessible pour le développement et la gestion des pipelines de Machine Learning.
Maintenant que nous avons exploré les capacités de Saagie en matière de conception et d’orchestration de pipelines de données, nous nous intéressons plus en détail à l’utilisation de BigQuery pour le Machine Learning dans la partie suivante.
Analyse de sentiments dans des reviews IMDB dans BigQuery
Afin d’explorer l’utilisation de BigQuery pour faire du Machine Learning, nous allons nous plonger dans l’analyse de sentiment appliquée aux avis de films provenant de la base de données d’IMDB. Notre objectif est de déterminer la polarité des critiques, c’est-à-dire si elles sont positives ou négatives.
Dans cet partie, nous traiterons uniquement la première étape de notre tâche d’analyse de sentiments, c’est-à-dire l’envoi des données dans un projet BigQuery.
1. Création d’un projet
La première chose à mettre en place avant de se lancer dans la création de modèle est la connexion à BigQuery, et la création d’un projet. Pour y accéder, il faut commencer par se connecter à GCP avec un compte Google.
Puis, il faut accéder à BigQuery afin de créer un nouveau projet, ou d’en sélectionner un existant.
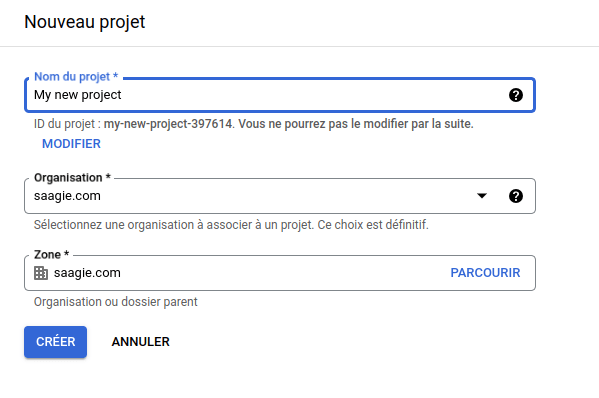
À partir de là nous pouvons accéder à BigQuery avec ses nombreuses fonctionnalités : la liste des projets existants apparaît à gauche, et au centre, nous avons la possibilité de créer nos premières requêtes, ainsi que de charger nos données dans BQ, ce que nous allons faire dans la sous-partie suivante.
2. Récupération des données et envoi dans BQ
Une fois notre projet accessible dans BigQuery, nous pouvons nous lancer dans la mise en place des différentes étapes nécessaires à l’analyse de sentiments. Tout d’abord, il nous faut des données. Nous avons identifié le dataset de revues IMDB, il faut donc commencer par l’envoyer dans notre projet sur BigQuery afin de pouvoir le traiter. Pour cela plusieurs solutions :
- le site officiel IMDB propose de télécharger son jeu de données, régulièrement mis à jour. Il faudra cependant filtrer les informations qui nous intéressent et les réorganiser, cela demande beaucoup de traitement manuel
- HuggingFace propose une version du jeu de données facilement récupérable en Python
- Enfin la version la plus simple en passant par l’interface de BigQuery est d’utiliser la version mise à disposition sur Kaggle. Le jeu de données est ici au format csv, avec une colonne contenant les reviews, et une contenant les labels
Nous choisissons donc de télécharger le jeu de données sur Kaggle et nous allons l’envoyer sur BQ.
Pour cela, cliquer sur un des boutons AJOUTER et remplir le formulaire :
- Il s’agit d’un fichier local puisqu’on l’a téléchargé précédemment
- Sélectionner le fichier grâce au bouton Parcourir
- Sélectionner le projet que l’on vient de créer
- Créer un ensemble de données
- Nommer la table
- Activer la détection automatique du schéma
- Enfin, valider avec le bouton “Créer la table”
Nos données sont maintenant importées dans BQ. On peut en avoir un aperçu avec une première requête SQL permettant de visualiser nos 50 premières lignes.
SELECT * FROM `my-new-project-397614.IMDB_dataset.IMDB_table` LIMIT 50
Après avoir vu comment envoyer des données dans BigQuery, passons maintenant à une approche plus détaillée où nous aborderons la même tâche, mais cette fois en utilisant l’API Client Python depuis l’environnement de Saagie.
Comme discuté précédemment, l’utilisation de l’orchestrateur Saagie permettra d’automatiser chaque étape du processus d’importation et de manipulation de données, offrant ainsi une solution plus fluide et plus efficace pour l’analyse de données dans BigQuery.
Comment utiliser BigQuery dans Saagie
Plongeons désormais dans l’utilisation de BigQuery au sein de l’écosystème Saagie. Cette combinaison offre un ensemble de fonctionnalités puissantes pour l’analyse de données, simplifiant ainsi le processus de gestion, de requêtage et d’exploration de volumes massifs de données à travers BigQuery, le tout orchestré de manière transparente dans l’environnement de Saagie.
Dans cette section, nous allons découvrir comment exploiter ces fonctionnalités pour notre projet d’analyse de sentiments dans des revues IMDB, en nous appuyant sur les outils de BigQuery dans le cadre de Saagie pour réaliser des analyses efficaces et automatisées. Ici, nous nous concentrerons uniquement sur l’envoi des données dans BigQuery. Pour cela, il est nécessaire de pouvoir s’authentifier, ainsi que de pouvoir se familiariser avec la plateforme Saagie, ce que nous verrons dans les parties suivantes.
Compte de service, et API Client
Pour commencer à utiliser BigQuery avec Python, la première étape consiste à créer un compte de service. Il faut donc se rendre dans l’onglet IAM et administration, dans la section Comptes de service, et cliquer sur CRÉER UN COMPTE DE SERVICE. Après avoir rempli les différentes informations nécessaires à la création du compte, nous retrouvons notre compte dans la liste des différents comptes de service existants.
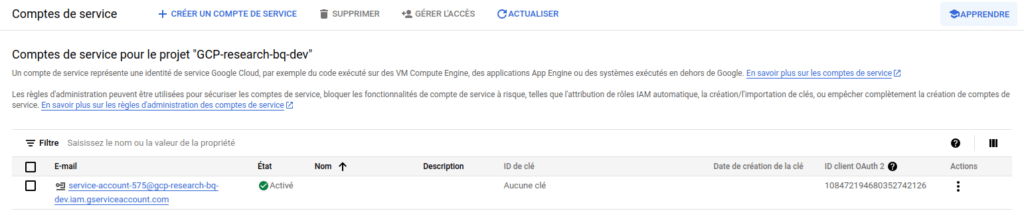
Il nous faut ensuite ouvrir la liste des actions possibles, à droite de la ligne, et choisir Gérer les clés. À partir de cette nouvelle page, nous pouvons ainsi ajouter une nouvelle clé, en créant une clé JSON. Le fichier JSON associé à ce compte est automatiquement téléchargé lors de sa création. Cette clé doit être gardée précieusement, puisque c’est celle-ci qui servira à nous authentifier auprès de BigQuery dans Python. En cas de perte, il nous faudra en créer une nouvelle.
Une fois le compte de service créé et le fichier JSON téléchargé, il suffira de s’identifier via l’API Client Python pour envoyer des requêtes à BigQuery. Pour cela, nous devons utiliser la clé JSON et l’identifiant du projet (project_id).
Cette authentification permet de sécuriser les connexions à BigQuery. Une fois cette étape d’authentification terminée, nous sommes prêts à envoyer des requêtes à BigQuery et à commencer à travailler avec nos données. Dans la partie suivante, nous ferons nos premiers pas avec la plateforme Saagie.
Pipeline d’analyse de reviews IMDB avec BigQuery dans Saagie
Maintenant que nous pouvons nous authentifier en Python, nous allons commencer la construction de notre Pipeline d’analyse de sentiments dans Saagie.
Première utilisation de la plateforme et authentification sur BigQuery
Bienvenue sur la plateforme Saagie.
Nous allons ici créer un projet pour l’occasion : BQ_IMDB.
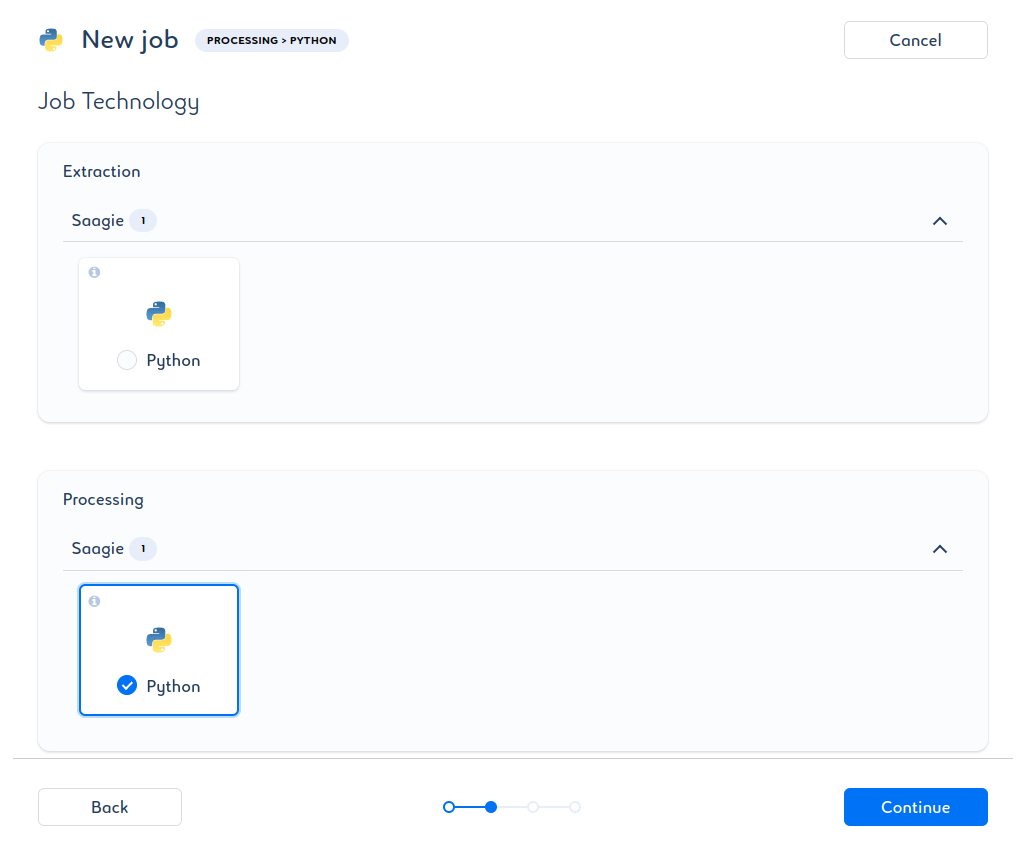
Parmi les technologies proposées, nous n’aurons besoin que de Python dans le catalogue officiel Saagie.
Nous n’avons pas besoin d’App pour le moment, rien n’est donc sélectionné sur l’écran suivant.
Vient ensuite la gestion des droits. Ici, c’est à vous de voir comment gérer les droits d’accès à votre projet, dans notre cas, nous ne donnerons pas les accès à d’autres groupes.
Après avoir cliqué sur Create Project, notre projet est créé, nous allons pouvoir réaliser notre premier Job dans Saagie.
Pour créer un Job Python, il faut avoir à disposition un fichier .py ou un fichier .zip qui contient le fichier .py avec le code à exécuter, si nécessaire, un requirements.txt avec la liste des librairies python à installer ainsi que leur version, et d’autres fichiers nécessaires à l’exécution du code et que vous aurez définis. Dans notre cas, nous fournirons donc un .zip contenant :
- Le requirements.txt avec afin de pouvoir importer différents packages python nécessaires comme l’API Client BigQuery, Pandas, etc
- La clé JSON, qui nous permettra de nous authentifier
Chaque Job devra contenir le code d’authentification utilisant la clé JSON et le project id du projet BigQuery. Pour plus de simplicité, nous stockons le project id dans la liste des variables d’environnement de projet.
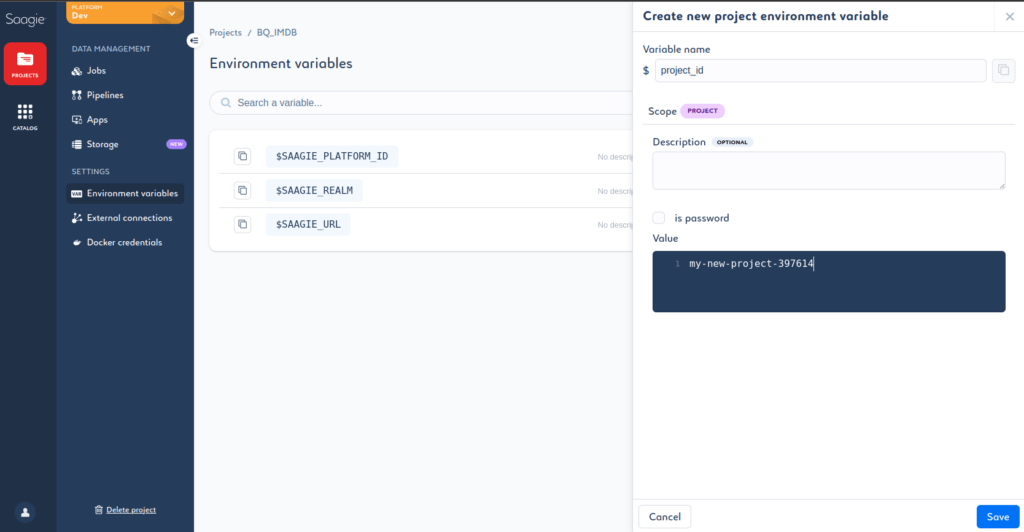
Nous pourrons ensuite accéder aux différentes variables d’environnement au moment de la création des Jobs, dans la console d’exécution.
Premier Job : Récupération des données et envoi dans BigQuerry
Pour la création de notre premier Job, qui charge les données IMDB dans BigQuery, il faut tout d’abord ouvrir un éditeur de texte ou un IDE, et se préparer mentalement à coder en Python. Afin de pouvoir utiliser l’API Client BigQuery, et de pouvoir s’authentifier, nous commençons par créer une première fonction, qui prend en paramètre le chemin d’accès du fichier JSON, et le project id, et qui nous renvoie un objet Client nous permettant de communiquer avec BigQuery.
from google.cloud import bigquery
from google.oauth2 import service_account
def set_credentials(json_path, project_id):
credentials = service_account.Credentials.from_service_account_file(json_path)
client = bigquery.Client(credentials= credentials, project=project_id)
return client
En Python, les données IMDB sont facilement accessibles grâce à la librairie Datasets de HuggingFace. Nous créons donc une fonction qui charge le jeu de données puis le convertit en Dataframe Pandas.
from datasets import load_dataset
import pandas as pd
def load_dataset_from_hugging_face():
datasets = load_dataset("imdb")
train_imdb = datasets["train"].to_pandas()
return train_imdb
Jusqu’à présent, nous avons seulement chargé les données dans une Dataframe, mais celles-ci n’ont toujours pas été envoyées sur BigQuery. Pour réaliser cela, nous utiliserons un objet Client et le project_id, ainsi que notre fonction précédente load_dataset_from_hugging_face() , qui nous permet de charger les données HuggingFace dans une DataFrame Pandas.
Puis, le dataset est mélangé. Les 4 lignes suivantes envoient les données sur BigQuery : Nous commençons par définir le nom de notre table en incluant le nom de l’ensemble de données défini sur BigQuery, ce qui nous donne IMDB_dataset.IMDB.
Ensuite, grâce au client et le project_id, les données sont directement envoyées dans le projet BigQuery.
Enfin, la dernière étape de notre fonction consiste à ajouter la localisation des données dans une variable d’environnement de Pipeline sur Saagie, car cette information nous sera. Pour cela, nous nous référons à la documentation Saagie, en ajoutant cette venv dans le fichier “/workdir/output-vars.properties”.
def load_local(client, project_id):
df = load_dataset_from_hugging_face()
df = df.sample(frac=1, random_state=66).reset_index(drop=True)
database_path = "IMDB_dataset.IMDB"
job = client.load_table_from_dataframe(df, f"{project_id}.{database_path}")
with open("/workdir/output-vars.properties", "w") as f:
# Writing data to a file
f.write(f"DATABASE={database_path}")
return job
La fonction est maintenant terminée, il ne nous plus qu’à assembler le tout, ajouter un parser pour récupérer les arguments donnés en paramètre du Job, créer un client à partir de ces informations, et enfin utiliser notre fonction d’envoi des données :
from google.cloud import bigquery
from google.oauth2 import service_account
import argparse
import logging
import pandas as pd
from datasets import load_dataset
import os
parser = argparse.ArgumentParser(description='Send IMDB dataset from HuggingFace to BigQuery.')
parser.add_argument("--json_path", type=str, help="Path to the json authentification file", required=True)
parser.add_argument("--project_id", type=str, help='Big Query project ID', required=True)
args = parser.parse_args()
logger_info = logging.getLogger().setLevel(logging.INFO)
def set_credentials(json_path, project_id):
credentials = service_account.Credentials.from_service_account_file(json_path)
client = bigquery.Client(credentials= credentials, project=project_id)
return client
def load_dataset_from_hugging_face():
datasets = load_dataset("imdb")
train_imdb = datasets["train"].to_pandas()
return train_imdb
def load_local(client, project_id):
df = load_dataset_from_hugging_face()
df = df.sample(frac=1, random_state=66).reset_index(drop=True)
database_path = "IMDB_dataset.IMDB"
job = client.load_table_from_dataframe(df, f"{project_id}.{database_path}")
if not os.path.exists("/workdir/"):
os.makedirs("/workdir/")
with open("/workdir/output-vars.properties", "w") as f:
# Writing data to a file
f.write(f"DATABASE={database_path}")
return job
client = set_credentials(args.json_path, args.project_id)
result = load_local(client, args.project_id)
logging.info("DATASET LOADED INTO BIGQUERY")
Le code du Job se termine avec un message de log afin de vérifier que tout s’est bien déroulé. Une fois ce code sauvegardé dans un fichier Python, il faut donc créer un fichier .zip avec le code Python, le fichier JSON, ainsi qu’un requirements.txt qui contient la liste de toutes les librairies importés en Python et leur version.
Dans notre cas, cela donne :
pandas==2.0.3
protobuf==4.24.3
google-api-core==2.11.1
google-auth==2.21.0
google-cloud-bigquery==3.11.3
google-cloud-core==2.3.3
google-crc32c==1.5.0
google-resumable-media==2.5.0
googleapis-common-protos==1.59.1
datasets==2.14.5
Il suffit maintenant de se rendre sur la plateforme Saagie pour la création de notre premier Job :
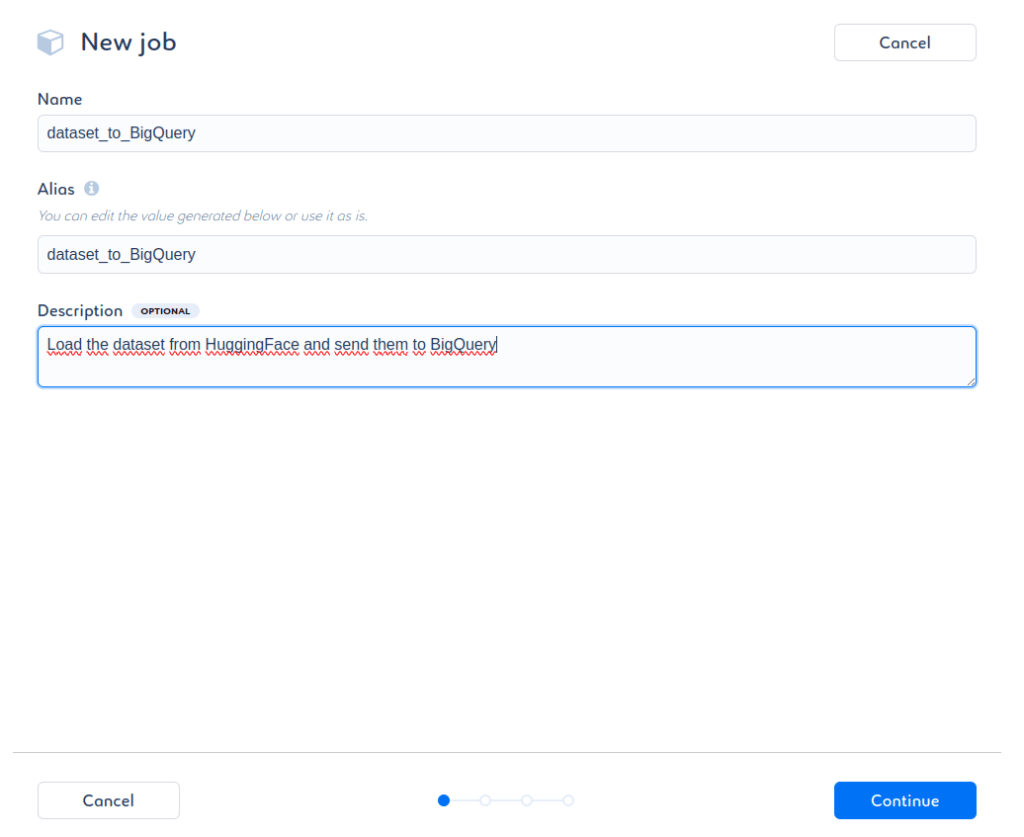
On renseigne les différentes informations nécessaires :
On choisit la technologie du Job :
Il est maintenant temps d’ajouter le code à notre Job. La version de Python recommandée est celle par défaut. Le package correspond au fichier .zip. Enfin, il faut saisir la commande à utiliser pour lancer le code Python.
Il faut toujours commencer par l’instruction Python, vient ensuite le nom du fichier à exécuter (notre code se trouve dans __main__.py). Puis, ajouter les arguments si nécessaire.
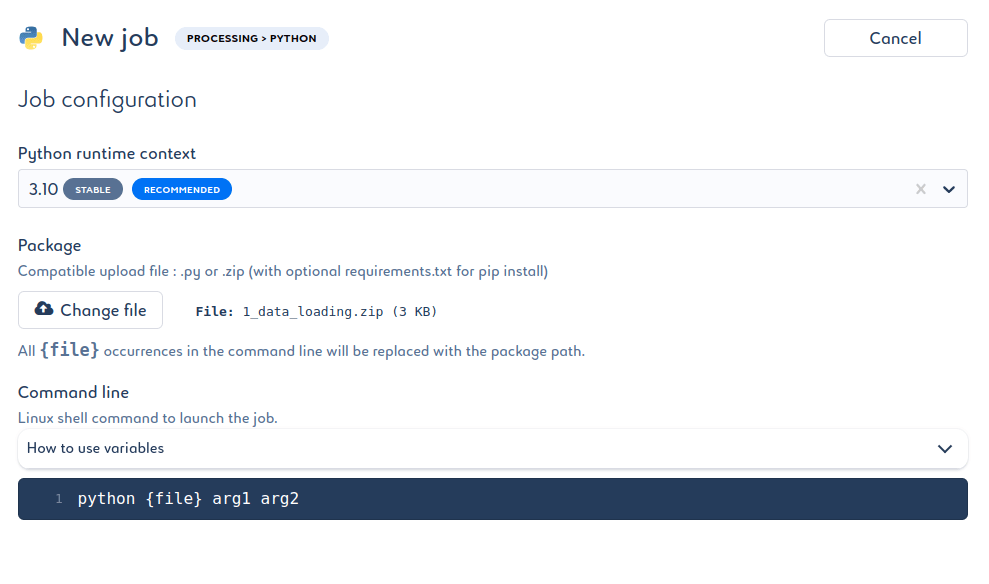
Dans le code, nous avions définit 2 arguments récupérés par le parser :
- le fichier JSON avec --json_path
- l’identifiant du projet avec --project_id
Le fichier JSON étant dans le package, il suffit d’indiquer que celui-ci est dans le même dossier que le code, en précisant évidemment son nom : ./my-new-project-397614.json.
Concernant le project_id, nous l’avions précédemment ajouté dans les variables de projet Saagie, il suffit alors de le récupérer avec le symbole $ : $project_id. Ceci nous donne :
python __main__.py --json_path ./my-new-project-397614.json --project_id $project_id
L’écran suivant permet de définir les ressources disponibles pour faire fonctionner le Job, nous laisserons ces valeurs par défaut.
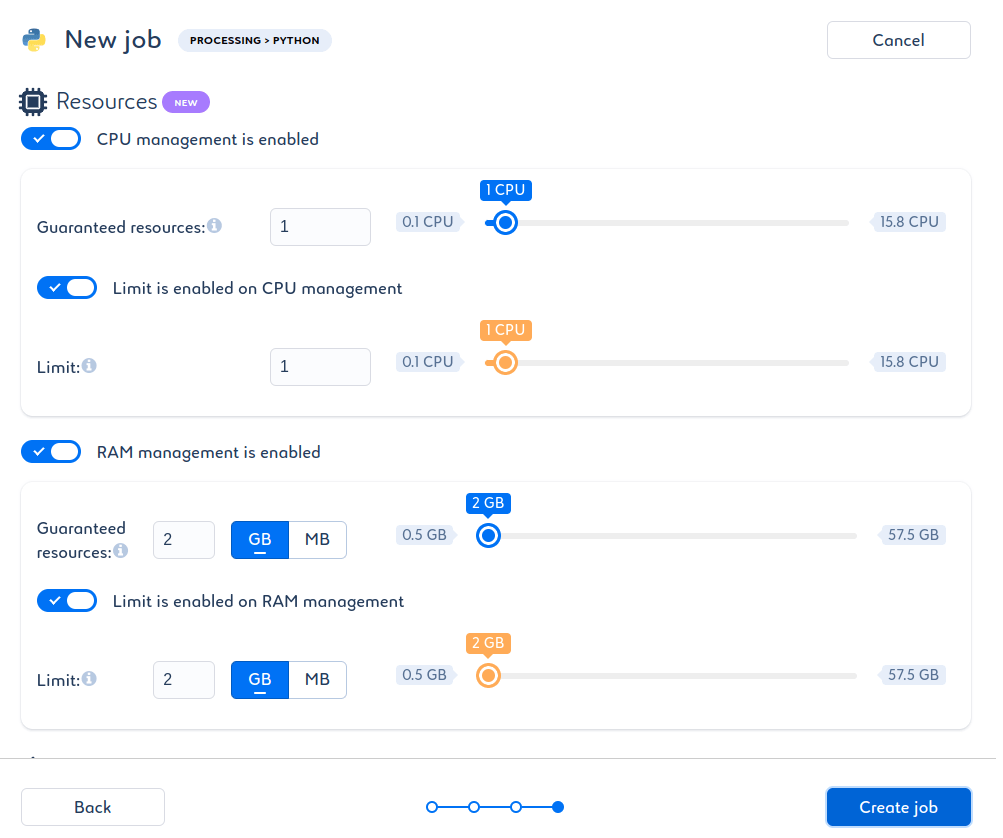
Félicitations, vous venez de créer votre premier Job dans Saagie !
Pour le tester, il suffit de cliquer sur le bouton Run.
Ce premier volet de notre exploration des pipelines de données arrive à son terme. Dans le prochain article, nous verrons en détail l’étape de prétraitement des données IMDB. Restez connectés pour découvrir la suite captivante de notre voyage à travers l’analyse de données avec BigQuery et Saagie.
Découvrez la simplicité d’utilisation et la pertinence de Saagie en action avec notre démo live !





