L’orchestration de traitements hybrides est devenue essentielle dans le paysage complexe des systèmes d’information actuels. Dans cet article, nous explorerons comment Saagie simplifie cette orchestration en permettant aux entreprises de combiner efficacement des traitements internes et externes, tout en minimisant les déplacements inutiles de données. Découvrez comment cette approche novatrice offre flexibilité et efficacité dans la gestion des workflows de données.
Défis de l'orchestration des données dans un paysage complexe des systèmes d'information.
Un SI toujours plus complexe
Le nombre d’applications gérées par les grandes entreprises ne cesse de croître. Alors que la DSI d’un grand groupe ne gérait en moyenne “que” 976 applications en 2022, elle en gère maintenant 1061 soit une augmentation de 8,7% (source: Connectivity Benchmark 2023 par l’éditeur Mulesoft).
Si cela peut paraître anodin, il faut se rappeler que 85 applications supplémentaires représentent des intégrations à réaliser avec le reste du SI, des équipes pour piloter ces applications ainsi que leur intégration, de la coordination supplémentaire et surtout de nombreuses erreurs potentielles dans les différents flux de données entre applications.
Cette évolution du nombre d’applications est notamment liée à l’évolution du cloud computing dans les entreprises. De plus en plus d’entre elles se tournent vers les cloud providers et une application peut tout aussi bien être un développement in-house, un logiciel SaaS de compatibilité, un service tel que Big Query ou encore un ensemble de Lambda chez AWS. Cela crée donc un besoin d’orchestration de composants pouvant être tout internes autant qu’externes au SI de l’entreprise.
La donnée, cette grande voyageuse
La donnée est une grande voyageuse: une étude réalisée en 2021 par l’Agence De l’Environnement et de la Maîtrise de l’Energie estime en effet que le trajet moyen d’une donnée est de 15 000 km. Que ce soit d’un point de vue pratique (temps de traitement), économique (bande passante) ou sociétal (écologique), déplacer la donnée sur une telle distance ne fait aucun sens. Pourtant, plus d’application dans la DSI veut aussi dire plus de trajet pour la donnée.
Dans nos différents traitements, nous allons donc vouloir rassembler des données provenant de différentes sources, les nettoyer, les combiner, les organiser et les préparer pour leur analyse ou leurs usages opérationnels. Le voyage de la donnée passe par bon nombre de workflows allant de l’extraction, de la préparation, de la modélisation jusqu’à la visualisation. Un exemple très concret et lié à la gouvernance des données en est l’uniformisation : afin de pouvoir exploiter la donnée exposée au sein de différentes applications, il faut la réconcilier et standardiser sa représentation de manière indépendante des sources la fournissant initialement.
Ces nombreux workflows n’ont pas nécessairement lieu au même endroit, ni dans un même temps. Il faut donc les monitorer et les orchestrer les uns par rapport aux autres.
Ce besoin était déjà présent au sein d’un SI entièrement intégré. De nombreuses entreprises ont en effet des traitements nécessaires à leur fonctionnement séquencé au travers de plusieurs applications, que ce soit à des fins opérationnelles ou pour du reporting interne vers le top management. C’est encore plus vrai dans le monde du cloud computing où les SI clients sont souvent hybrides voir multi-cloud. Il y a donc une situation où d’une part l’utilisation de ces services facilite le travail de la DSI mais où d’autre part cela induit de plus fort mouvements de données et de plus grands besoins de réconciliation puisque la représentation de la donnée n’est plus à la main de la DSI.
L’orchestration de traitement externe avec Saagie
Le rôle premier de Saagie chez nos clients est d’orchestrer ces traitements de données. Ces traitements sont en général développés par nos clients en Python, Java ou Spark ou autres technologies supportées par notre plateforme. Ces traitements s’appuient en général sur les API des différentes applications et services afin de récupérer des données ou déclencher des actions. Il s’agit donc d’activités de développements réalisés par les Data engineers, Data scientists et par les équipes techniques de la DSI. Sur le long terme, le temps de développement initial s’efface face au temps de maintenance et d’évolutions de ces développements dans une stack data qui continue, elle aussi, d’évoluer.
Fort de l’expérience de ce qui est réalisé avec nos clients, nous avons voulu simplifier les interactions avec certains services au travers de ce que nous avons nommé des jobs externes : des traitements qui sont déclenchés par Saagie mais qui ne s’exécutent pas sur notre plateforme !
Ils s’appuient ainsi sur la réalité de plus en plus hybride de nos clients : pourquoi déplacer de la donnée brute, au prix de la bande passante, lorsque le cloud provider fournit déjà les outils permettant de la traiter et que ceux-ci sont par ailleurs déjà souvent utilisés par nos clients. Il est donc ainsi possible de ne déplacer que de la donnée raffinée, nécessaire elle à d’autres traitements et reporting. D’un point de vue développement, il y a là aussi gain de temps puisque les équipes peuvent se concentrer sur le traitement métier sans avoir à traiter la mécanique de connexion à ces différents systèmes.
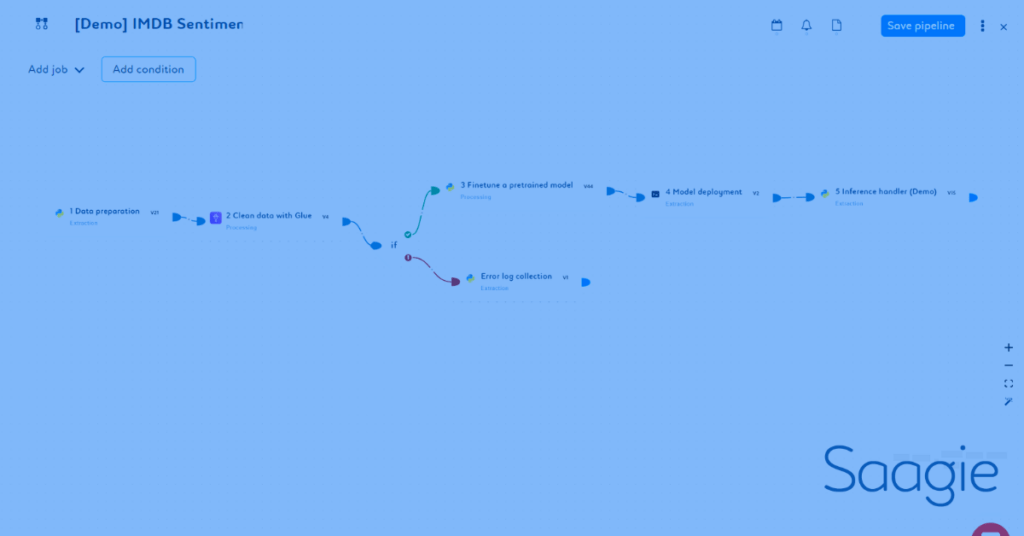
Exemple d'une orchestration de techno sur Saagie et AWS
Il est ainsi possible simplement depuis notre interface de se connecter à son compte AWS afin d’accéder à différents traitements créés.
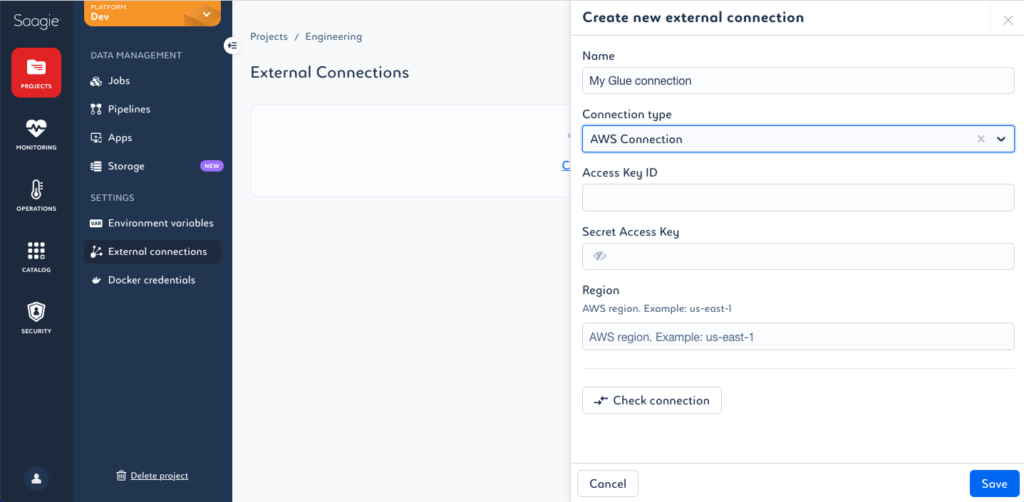
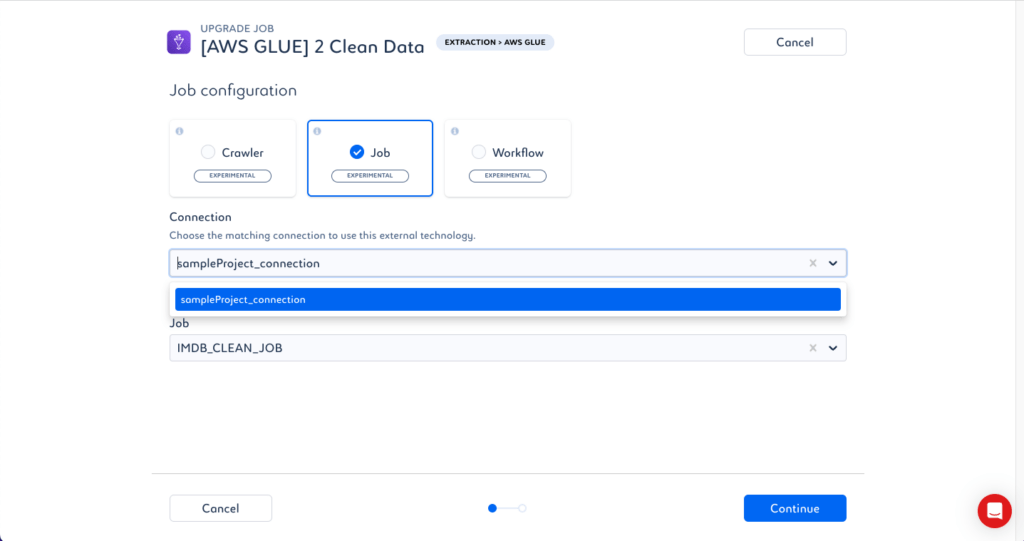
Une fois la connexion établie et validée, il devient alors possible de déclencher depuis des pipelines Saagie des traitements déjà scriptés dans des services tels que Glue ou Lambda tout en réalisant des traitements accédant à d’autres sources de données du SI.
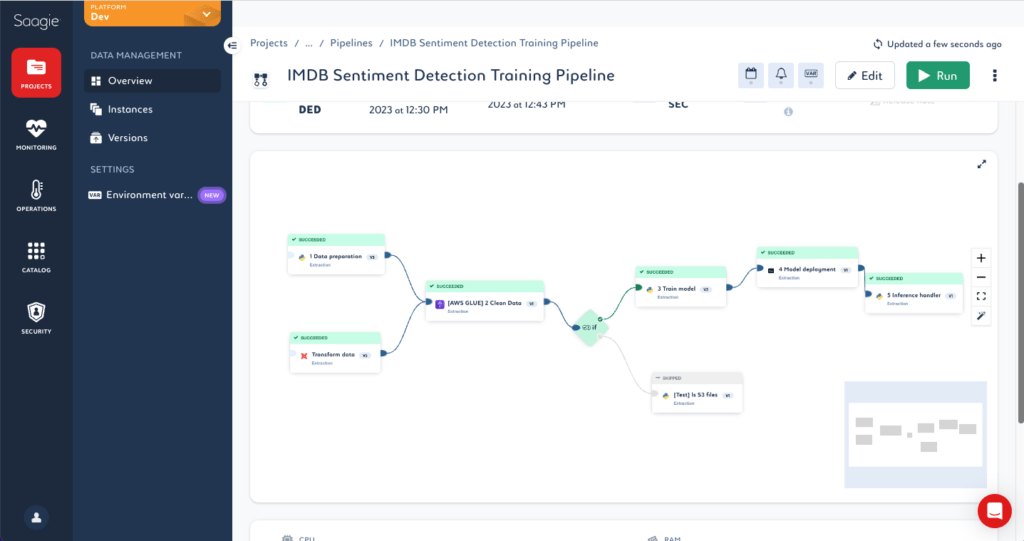
Ces jobs peuvent ensuite être utilisés au même titre que n’importe quel traitement Saagie au sein de pipelines plus ou moins complexes :
Un SDK qui apporte des solutions pour l'orchestration !
Bien que Saagie fournisse un catalogue de technologies par défaut, il sera bien sûr impossible de couvrir l’intégralité des services existant sur le marché. C’est pour cela que nous fournissons également un SDK permettant aux entreprises d’intégrer les technologies utilisées qui ne feraient pas encore partie de notre catalogue.
SGBDR, NoSQL, Datawarehouses, Datalakes, Lakehouse, applications accédées par API ou fonctions clouds; la liste et la complexité des systèmes stockant et exposant de la donnée n’a fait qu’augmenter, au même rythme que la donnée elle même, imposant des traitements de plus en plus important et coûteux afin d’en tirer un sens et des décisions. La chaîne de traitement permettant de transformer la donnée en information n’est aujourd’hui ni linéaire ni même limitée géographiquement pour une entreprise. Saagie permet d’orchestrer et de piloter des traitements réalisés au sein même de la plateforme comme via des services externes en offrant des facilités de type no-code quant à l’utilisation de ces dernières.





