Si vous êtes un data scientist, il est fort probable que vous ayez déjà entendu parler des notebooks Jupyter et il y a aussi de fortes chances que vous vous en serviez au quotidien !
Qu'est-ce que Jupyter ?
Le notebook est un outil de travail devenu très populaire dans les milieux académique et scientifique pour pouvoir facilement travailler sur du code encore au stade de prototype. Il existe plusieurs systèmes de notebooks, Jupyter est le plus répandu d’entre eux dans le monde de la data science (et au-delà probablement). Mais saviez-vous que la première version de cet outil a été lancée en 2015 ? Cela veut dire qu’en 5 ans, cet outil s’est imposé comme un incontournable dans la boîte à outils du data scientist !
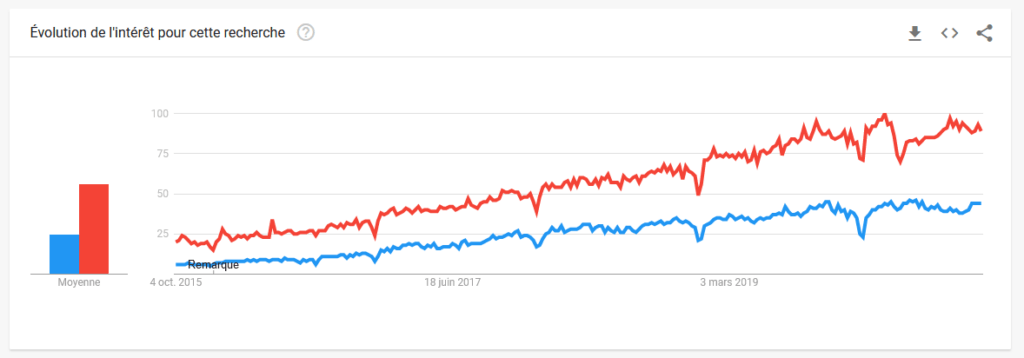
Pour l’histoire, le nom « Jupyter » est un clin d’œil à la planète du même nom et plus largement au domaine scientifique, mais c’est surtout la contraction de Julia, Python et R, trois langages très utilisés dans ce domaine. Cet article présente les points forts de Jupyter qui lui ont permis de devenir si populaire.
Comment fonctionne un notebook Jupyter ?
En détaillant le fonctionnement global d’un notebook, on va déjà voir apparaître plusieurs raisons qui ont rendu cet outil si populaire.
La structure de Jupyter se compose de 3 éléments principaux :
- le notebook à proprement parler, qui est un fichier avec une extension .ipynb. Ce fichier contient votre code ainsi que l’output généré par ce code lors de son exécution ;
- une application web, qui est chargée d’afficher les notebooks et permet à l’utilisateur d’interagir avec ;
- un kernel, chargé d’exécuter le code contenu dans le notebook. Il peut s’agir d’un kernel Python, R…, en fonction du langage que vous utilisez dans votre notebook.
Tout d’abord, creusons un peu plus les spécificités des notebooks :
- ils sont souvent compatibles d’un système de notebook à un autre. Donc vous pouvez lire et modifier un notebook Jupyter sous Google Colab (un autre système de notebook made in Google) et vice-versa ;
- comme dit précédemment, le notebook contient les résultats d’exécution. Ça paraît simple, mais en réalité, c’est extrêmement pratique ! Cela veut dire que vous n’avez pas à envoyer votre code et vos résultats dans deux fichiers séparés (et tout ce que cela implique de confusions entre différentes versions de fichiers ou bien pour savoir quelle partie du code est responsable de quel résultat).
Ces deux raisons font des notebooks un support de travail idéal pour facilement échanger et partager votre travail, qu’il s’agisse d’une analyse de données ou bien d’une proposition d’architecture de réseau de neurones.
Un seul support de travail pour vos langages, où que vous soyez
L’interface de Jupyter est basée sur une application web, c’est-à-dire que vous y accédez grâce à votre navigateur web. Une application web offre beaucoup de flexibilité en termes de déploiement, vous pouvez l’exécuter en local ou bien la déployer sur un serveur distant.
Dans ce dernier cas, vous pouvez déployer un service Jupyter pour donner accès à cet outil à tous les membres d’une équipe tout en centralisant le software et le travail réalisé. C’est justement le but de l’initiative Jupyter Hub ; il existe aussi des solutions dédiées chez les principaux fournisseurs de services Cloud.
Et peu importe si votre équipe préfère travailler avec Python, R, Julia ou l’un des 40 langages de programmation actuellement supportés par Jupyter. En effet, pour commencer à coder avec un nouveau langage dans Jupyter, il suffit d’installer le kernel d’exécution correspondant à ce langage et le tour est joué.
C’est aussi simple que ça, car oui, les notebooks sont avant tout un support de travail et ne dépendent pas du langage utilisé. On en vient au vrai point fort des notebooks et leur raison d’exister : leur ergonomie !
Une interface idéale pour expérimenter et itérer
On garde évidemment le meilleur pour la fin !
Très simplement, un notebook est un document composé d’un enchaînement de blocs, chaque bloc étant constitué de deux parties :
- une case modifiable dans laquelle vous écrivez votre code ;
- sous cette case se trouve une zone de résultat où s’affiche l’output généré par l’exécution du code.
Et tous les blocs d’un notebook partagent le même contexte, c’est-à-dire que si vous déclarez une variable dans un bloc, vous pouvez la réutiliser dans un autre bloc. Cette organisation est terriblement confortable à utiliser lorsque vous êtes dans la phase exploratoire d’un projet et que vous expérimentez, testez, corrigez, revenez en arrière… sans savoir exactement quelle structure aura votre code final.
Tout d’abord vous n’avez plus à jongler entre votre éditeur de texte et votre console, le code et les résultats sont au même endroit. D’autre part, il devient très facile avec un notebook de fragmenter votre code pour n’en exécuter qu’une partie précise sur laquelle vous souhaitez faire des ajustements ou des essais. Enfin, il est clair que l’équipe derrière Jupyter a fourni beaucoup d’efforts dans le design et l’ergonomie de cet outil, très agréable à utiliser au quotidien et s’enrichissant de jour en jour. La liste des raisons jouant en la faveur de Jupyter risque de s’allonger encore dans les années à venir !
Faites bien plus que du calcul avec vos notebooks !
Etes-vous sûr que vous exploitez le potentiel de Jupyter à sa juste valeur ? Dans cette partie, nous allons explorer quelques fonctionnalités et extensions qui font de Jupyter plus qu’un simple outil de calcul.
À noter que nous parlerons ici de Jupyter Lab, qui est une version étendue de Jupyter Notebook classique. Si vous utilisez Jupyter Notebook classique, je vous encourage à prendre un peu de temps pour tester Jupyter Lab, vous serez probablement vite convaincu.
Exploitez tout ce que Jupyter Lab peut vous offrir
Jupyter Lab est basé sur le principe des notebooks, qui est une interface très flexible et facile à utiliser. Mais il propose aussi d’autres fonctionnalités qui vous aideront dans votre travail quotidien.
Tout d’abord, Jupyter Lab vous permet d’organiser votre espace de travail comme vous le souhaitez en affichant différentes fenêtres à la fois. Il suffit de glisser et déposer l’onglet de votre fenêtre où vous le souhaitez, comme sur cette capture d’écran :
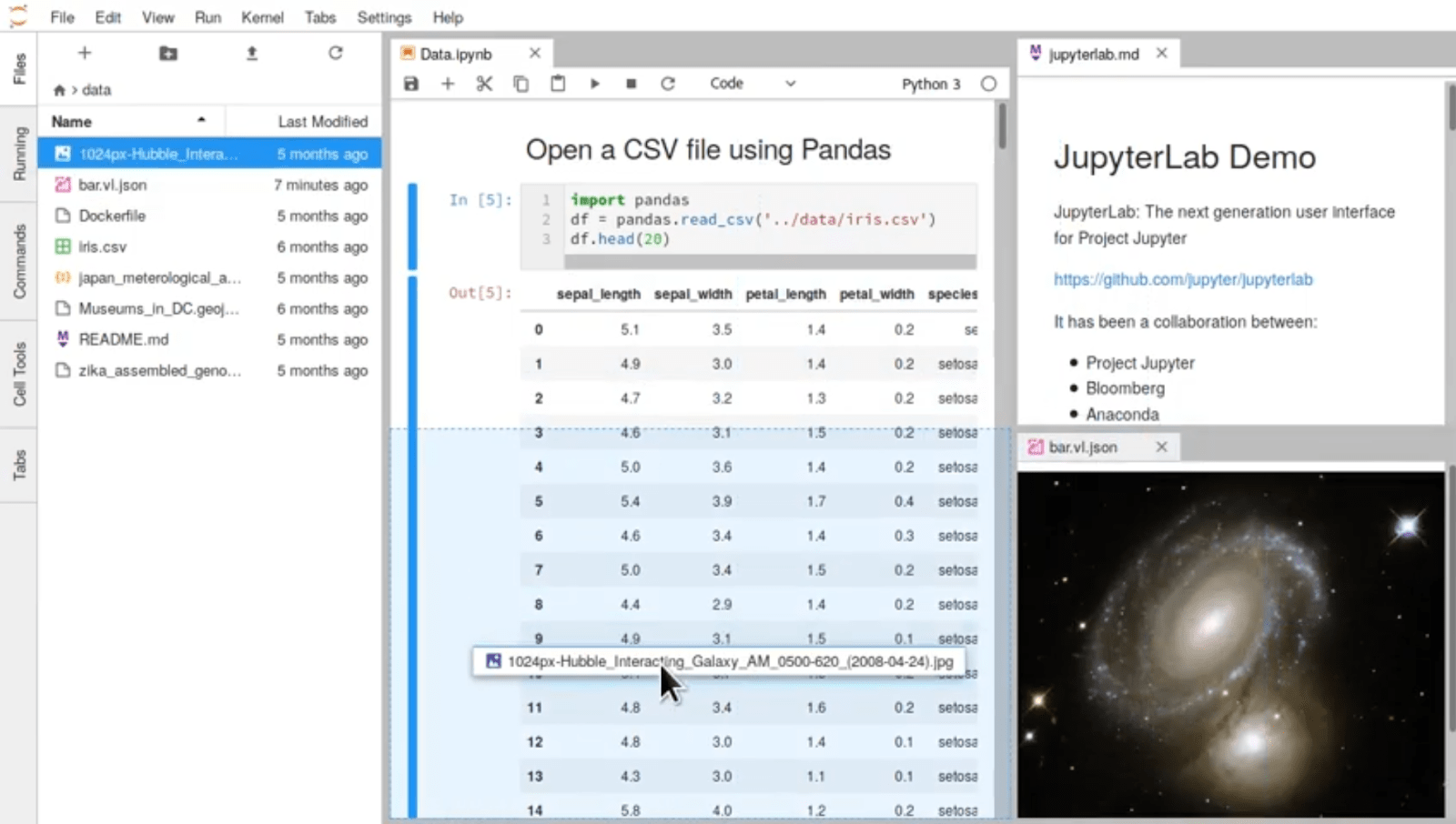
Vous remarquerez par ailleurs sur cette capture d’écran que plusieurs fichiers sont ouverts. Jupyter est capable de lire beaucoup de types de fichiers différents, des notebooks bien sûr, mais aussi des images, des PDF, des fichiers de données csv… (voici un lien pour une liste exhaustive). Cela vous évitera de jongler avec plusieurs logiciels différents.
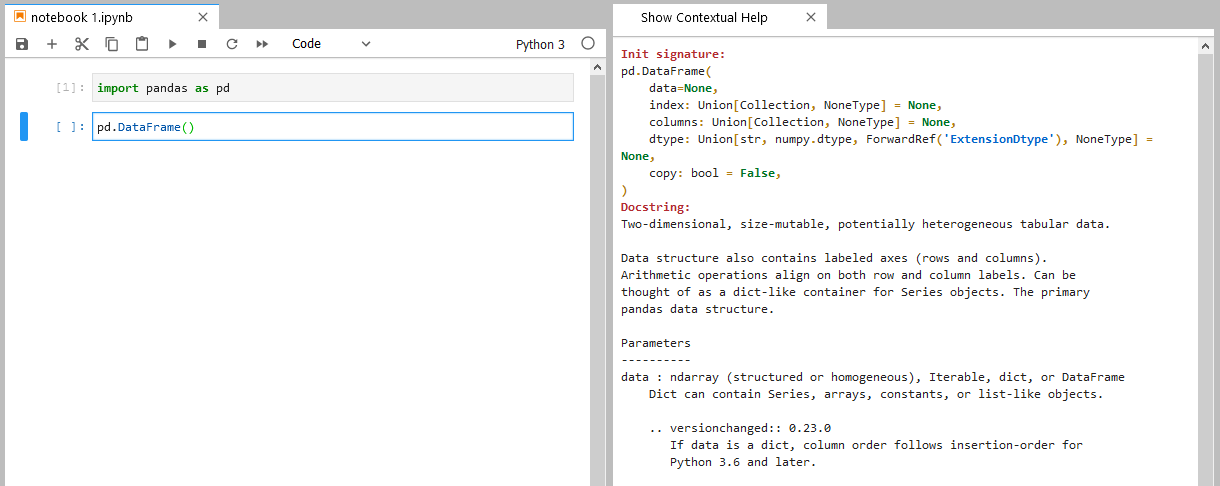
De plus, il est probable que vous ayez un onglet StackOverflow ouvert en permanence dans votre navigateur. Avant de foncer sur internet, pensez à ouvrir l’onglet d’aide contextuelle présent dans Jupyter, vous y trouverez rapidement des informations essentielles. Pour ce faire, appuyez sur « Ctrl + i », le contenu de cet onglet se met à jour en direct pour afficher la documentation de la fonction que vous êtes en train de saisir :
Présentez et partagez votre travail directement
Jupyter est idéal pour faire des analyses de données, mais il peut aussi être un support de présentation et/ou pédagogique puissant.
En effet, vous pouvez intégrer dans les cellules de vos notebooks du code HTML ou du code Markdown (pour plus d’informations sur les balises Markdown supportées par Jupyter).
Vous pouvez, grâce à cela, rajouter des tableaux, des images, des titres…, directement dans un notebook. Finalement, votre notebook peut être structuré comme un document Word, tout en gardant ce côté interactif vous permettant de changer un paramètre en direct et mettre à jour les résultats.
De plus, si vous n’avez pas la possibilité de présenter votre notebook en direct à vos collègues, vous pouvez l’exporter sous de nombreux formats :
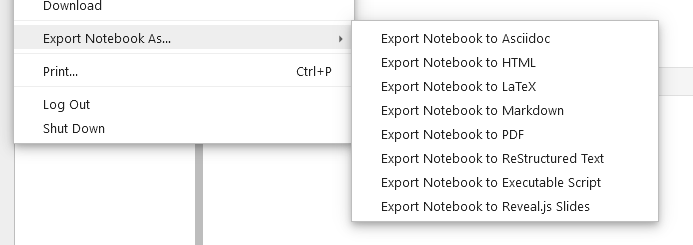
En particulier, vous pouvez choisir d’exporter votre travail au format PDF ou HTML, deux formats très répandus que n’importe qui peut ouvrir avec un simple navigateur web.
Etendez Jupyter avec des extensions pour encore plus de versatilité
Au-delà des fonctionnalités de base présentes, vous pouvez aussi télécharger et installer des extensions pour ajouter de nouvelles fonctionnalités à vos notebooks. Il en existe beaucoup, voici une petite sélection pour encore améliorer la mise en forme de votre travail :
- Plotly + Jupyter : vous connaissez peut-être déjà la librairie Plotly, qui permet de faire de nombreuses visualisations interactives. En installant une extension dédiée, vous pouvez intégrer ces visualisations directement dans vos notebooks pour les rendre encore plus attrayants.
- Encore un niveau au-dessus en matière d’interactivité, il y a Voila, qui vous permet de créer de petites applications web (typiquement un tableau de bord) directement avec un notebook.
- Enfin, Rise, qui transforme votre notebook en une présentation type PowerPoint. Si les diaporamas sont la norme dans votre entreprise, cette extension pourrait vous faire économiser beaucoup de temps en évitant de copier-coller vos résultats dans des diapos.
Finalement, Jupyter Lab est bien plus qu’un outil pour exécuter du code, il se veut très versatile, en particulier si l’on prend en compte les différentes extensions existantes.
Cependant, Jupyter n’offre pas encore une gestion avancée d’un répertoire de fichiers comme peuvent le proposer d’autres IDE tels que PyCharm. Jupyter est donc idéal pour la phase exploratoire et de prototypage d’un projet, mais lorsque vous passez à l’étape suivante et que vous souhaitez développer un outil ou une librairie stable, passer sur un autre IDE sera une sage décision.
Quelques astuces pour gagner en productivité avec Jupyter
Dans cette partie, nous présentons quelques astuces sur Jupyter dont vous pourriez avoir besoin afin de gagner en productivité.
Les raccourcis clavier essentiels pour vos notebooks
Commençons par les bases : les raccourcis clavier !
Si vous avez un peu d’expérience dans le développement informatique, vous n’êtes pas sans savoir que le clavier vous permet d’aller plus vite que la souris pour la majorité des opérations.
Cela reste valable lorsque vous travaillez sur des notebooks ! Durant une session de travail, vous serez amené à réaliser, plusieurs centaines de fois, certaines opérations telles que rajouter une case, ou exécuter le code contenu dans une case.
Par conséquent, connaître les raccourcis clavier de ces opérations simples vous fera gagner du temps. Il existe beaucoup de raccourcis par défaut dans Jupyter, en témoigne l’image ci-dessous tirée de ce blog :
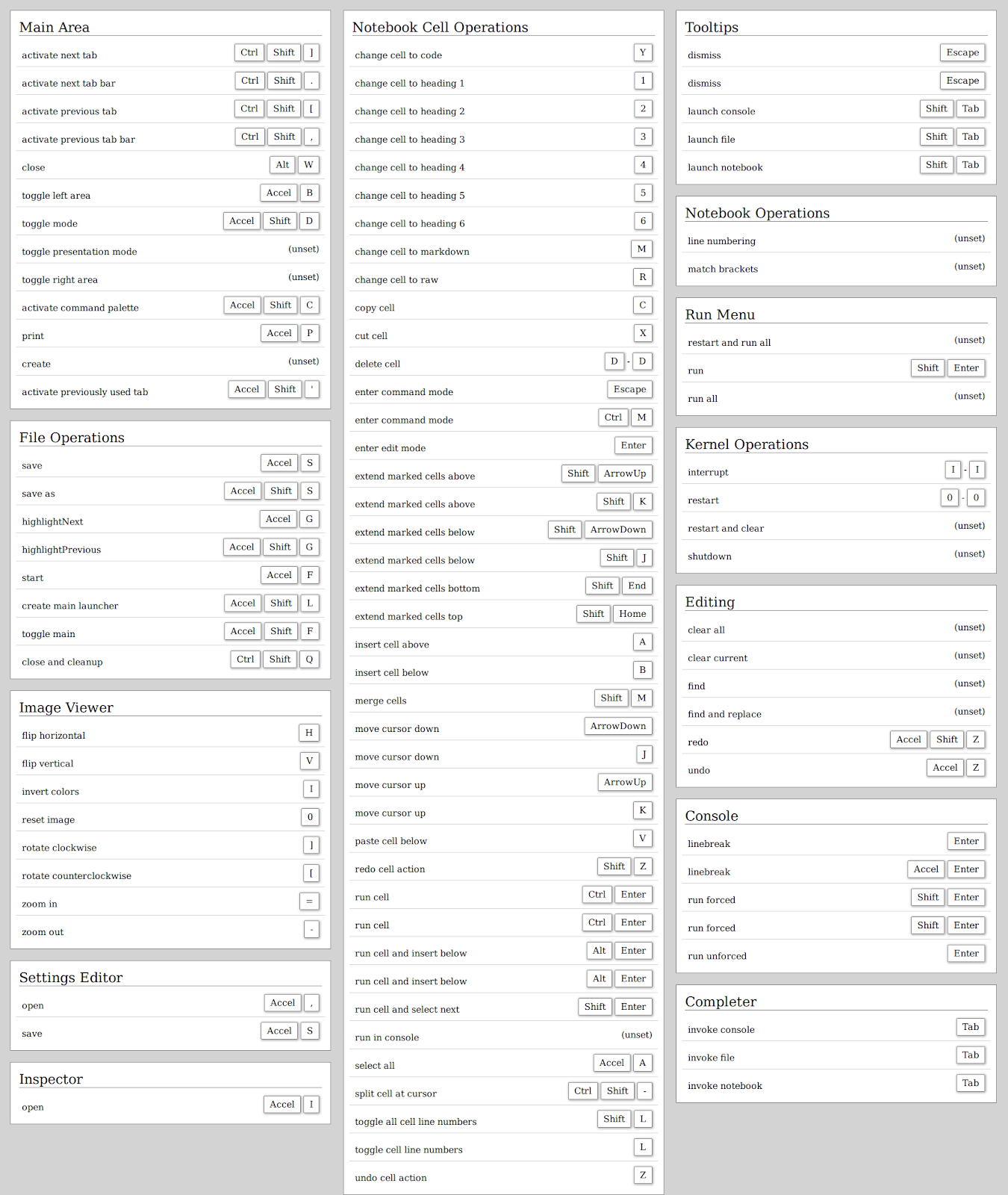
Attention, il s’agit des raccourcis par défaut de Jupyter Lab, il peut y avoir quelques différences si vous utilisez la version classique Jupyter Notebook.
Ces raccourcis ne sont pas tous essentiels, alors nous avons dressé une sélection de 10 raccourcis dont vous aurez très probablement besoin pour chaque session de travail.
Il est important de savoir que les raccourcis ne sont pas actifs en permanence, cela dépend si vous êtes en mode édition (en train de modifier le contenu d’une case) ou en mode commande (vous n’avez pas de curseur actif dans une case particulière). Nous les avons donc séparés en différentes catégories.
Remplacez la touche « ctrl » par son équivalent sur votre système d’exploitation si nécessaire.
Raccourcis valables en mode édition :
- « tab » : comme sur la majorité des environnements de développement, permet de compléter automatiquement une ligne,
- « shift + tab » : affiche l’aide contextuelle, le docstring d’une fonction, si disponible,
- « échap » : permet de passer en mode commande.
Les raccourcis classiques tels que « ctrl + C » / « ctrl + V » sont valables pour l’édition du code.
Raccourcis valables en mode commande :
- « B » et « A » : permet d’insérer une case, au-dessus de la case actuellement sélectionnée pour « A » (= above) ou bien en-dessous pour « B » (= below),
- « D – D » (2 appuis successifs sur D) : supprime la (ou les) cellule(s) actuellement sélectionnée(s),
- « Z » : annule la dernière opération réalisée sur les cellules (telle qu’une suppression par exemple),
- « entrée » : permet de passer en mode édition sur la case sélectionnée,
- « C », « X » et « V » : permet de respectivement copier, couper et coller une ou plusieurs cellule(s).
Raccourcis valables dans les deux modes :
- « shift + enter » (ou « ctrl + enter ») : de loin le plus utile, permet d’exécuter le code contenu dans la case actuellement sélectionnée,
- « ctrl + B » : permet d’afficher ou de cacher le panneau latéral contenant entre autres l’explorateur de fichier.
Si vous le souhaitez, vous pouvez compléter ou modifier les raccourcis clavier en navigant dans l’onglet « settings » puis « advanced settings editor » dans Jupyter Lab.
Rendez-vous service en utilisant les magic commands
Jupyter se base en partie sur un autre projet appelé IPython, qui est un terminal interactif pour Python. Jupyter a donc des choses en commun avec IPython et notamment certaines fonctionnalités.
En particulier, l’une des fonctionnalités IPython que l’on retrouve dans les notebooks Jupyter : il s’agit des magics commands.
Il s’agit de petites commandes qui ne sont pas du code Python mais qui permettent d’effectuer des opérations sur le code lui-même.
Là encore, il en existe un très grand nombre, sans même compter celles que vous pouvez rajouter avec des librairies externes. Vous pouvez trouver une liste complète avec toutes les options disponibles.
Contrairement aux raccourcis claviers, vous ne vous en servirez pas à chaque session de travail. En revanche elles peuvent vous faire gagner un temps considérable le jour où vous en avez besoin ! Voici donc une sélection :
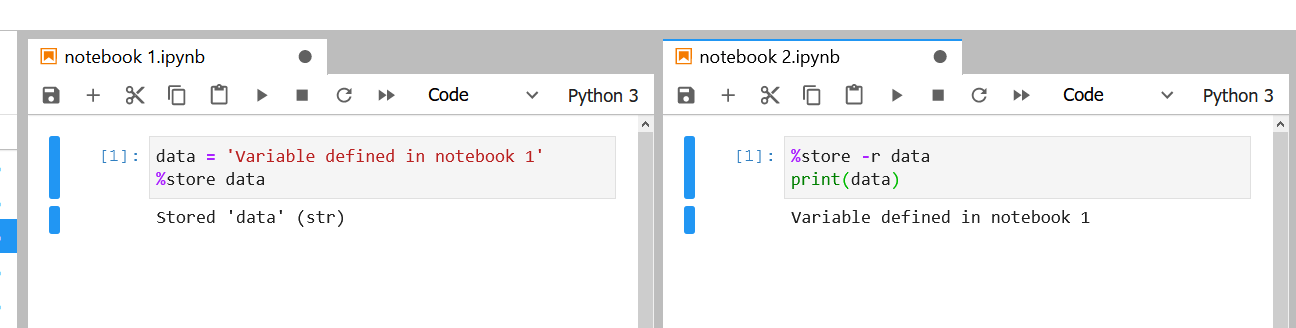
%store pour le partage des données d’un notebook à l’autre, comme montré dans l’image ci-dessous :
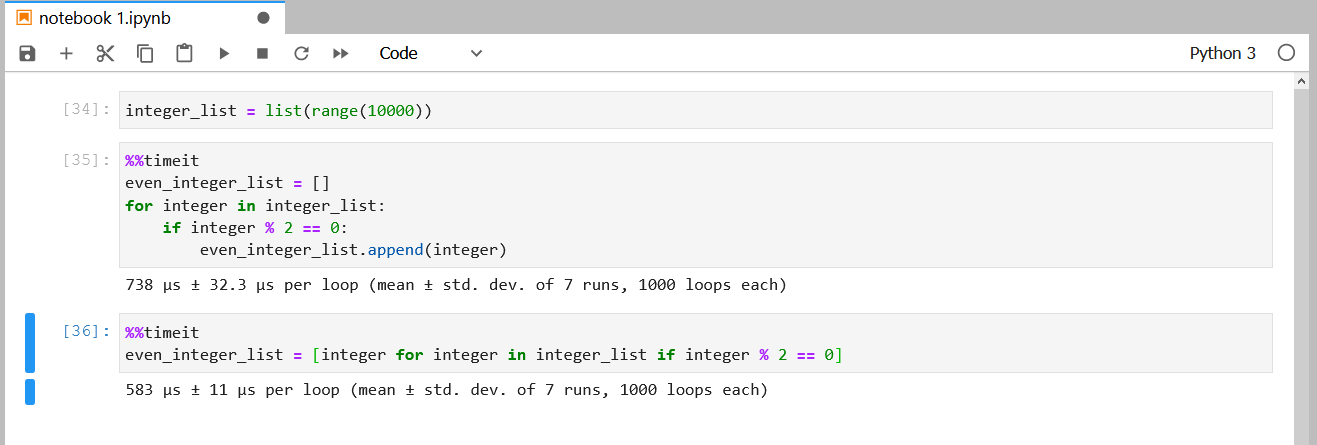
%%time et %%timeit qui permettent de mesurer le temps d’exécution d’une cellule. C’est utile pour comparer la performance de différentes méthodes. %%time mesure sur seule exécution, tandis que %%timeit lancera automatiquement plusieurs fois le code pour une évaluation plus précise :
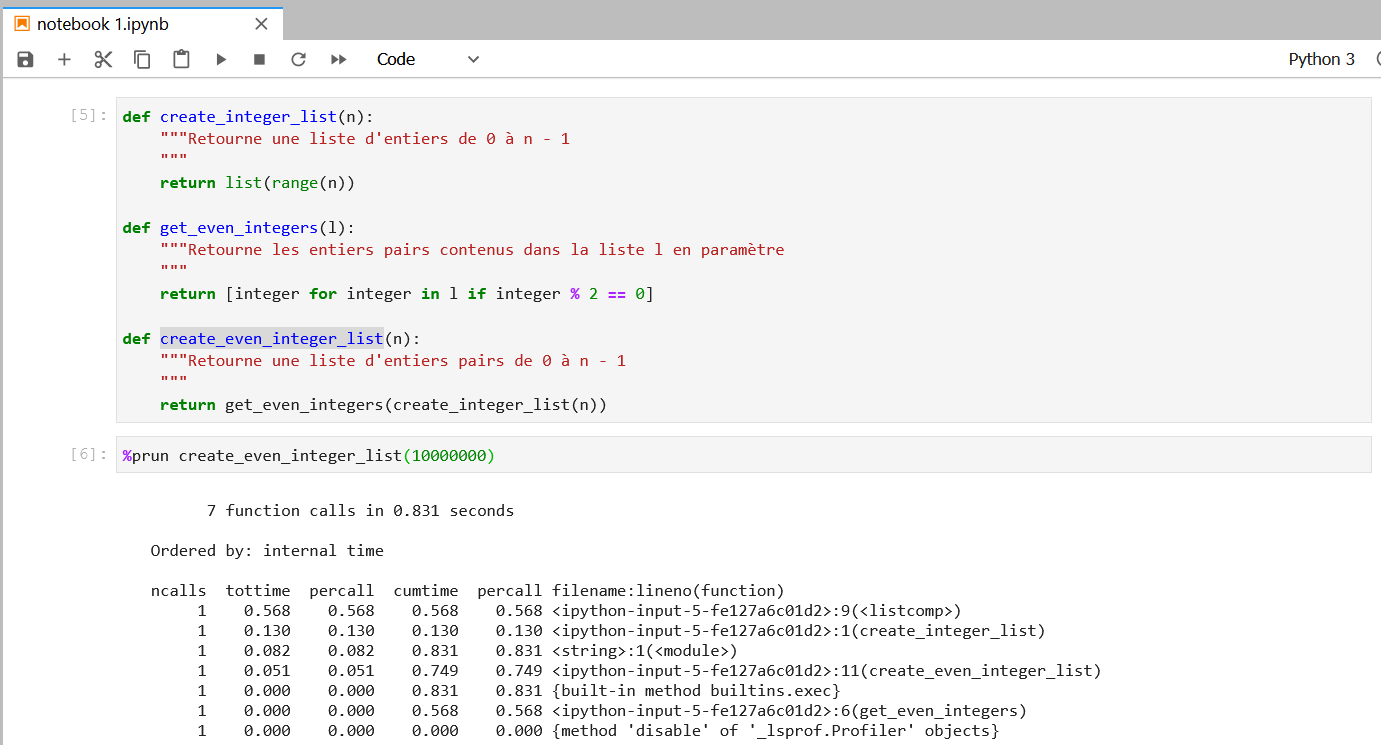
%prun est assez similaire mais donne le temps d’exécution pour chaque fonction appelée, ce qui est très pratique lorsque votre code commence à se complexifier :
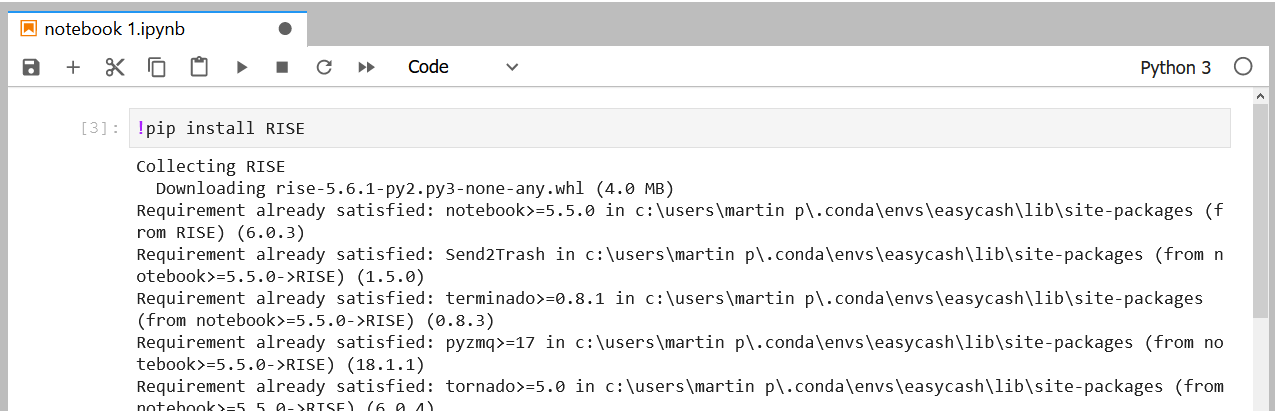
Dans la même veine, une commande parfois utile est « ! » suivi d’une instruction : cette instruction sera exécutée directement dans la console de votre ordinateur. Par exemple, vous pouvez installer une librairie directement depuis un notebook, comme ci-dessous :
Si vous êtes déjà familier avec ces quelques raccourcis clavier et magic commands, vous pouvez lire plus en détails la documentation de Jupyter Lab. Vous y trouverez beaucoup d’autres conseils pour améliorer votre maîtrise de cet outil.
Jupyter & Saagie
Saagie et Jupyter forment une combinaison puissante pour les professionnels de la data. Alors que Saagie fournit une plateforme DataOps complète pour la gestion et l’orchestration des projets data, Jupyter offre un environnement interactif et flexible pour l’analyse et la manipulation des données.
Grâce à l’intégration de Jupyter dans Saagie, les utilisateurs peuvent bénéficier des fonctionnalités avancées de Jupyter tout en tirant parti des capacités d’orchestration et de gestion de projet de Saagie. Ils peuvent développer et exécuter des notebooks Jupyter directement dans l’interface de Saagie, ce qui facilite le flux de travail et favorise la collaboration entre les équipes.