
Deuxième article de notre livre blanc : “Du Data Lab à la Data Factory : Comment passer les initiatives Big data / IA de l’expérimentation à la production ?”. Grâce à notre article précédent, vous savez maintenant tout du Data Lab, il est donc temps de passer à l’étape suivante : le Proof Of Concept. « Mais comment se passe un POC ? » dîtes-vous. Vous vous posez la question, nous répondons.
Qu'est-ce qu'un POC ?
Aussi appelé « démonstration de faisabilité », le POC (Proof Of Concept) est une expérimentation qui sert à montrer la valeur d’une idée. Dans le domaine de l’IA et du Big Data, il s’agira de démontrer la valeur d’un cas d’usage ou d’une méthode à partir d’un lac de données. Mais produire de la valeur à partir d’un Data Lake n’est pas si simple pour le Data Scientist. Il lui faudra donc travailler en étroite collaboration avec le Data Engineer au long des deux étapes majeures :
- La préparation de la donnée
- L’algorithmie
Le préparation de la donnée : l’étape la plus longue
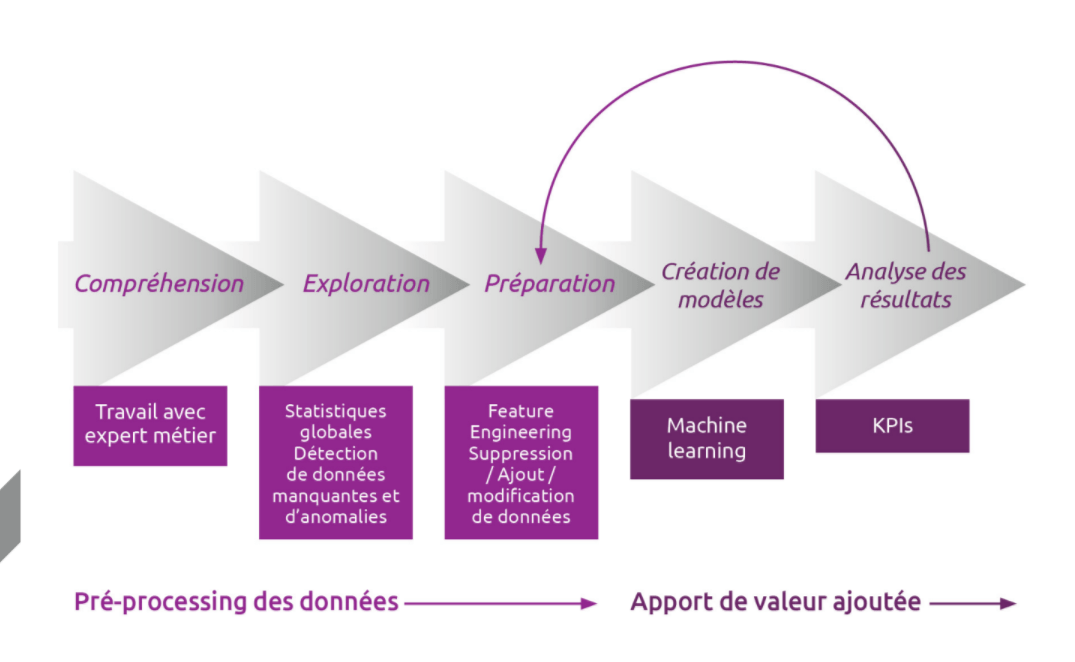
Cette étape de préparation est bien souvent la plus longue dans un projet Big Data / IA / Data Science. On estime qu’elle prend près de 80% du temps. Il s’agit de comprendre les données, de les explorer puis de les préparer.
Compréhension : il est indispensable de comprendre ses données et d’identifier celles qui ont de la valeur. Il est possible que beaucoup ne soient même pas utilisées en fonction du cas d’usage défini, mais il arrive aussi parfois qu’il en manque. Il faut alors, avec le ou les experts métier, comprendre lesquelles seront utiles et déterminer s’il est nécessaire d’aller chercher de l’Open Data ou d’autres sources de données.
Exploration : il faut alors chercher les données intéressantes. Il faut aussi déterminer leur fiabilité, et c’est ici que les KPIs (moyenne, variance, quartile, catégorie, saisonnalité…) entrent en jeu. Intervient enfin la mise en évidence de données manquantes (champs vides, anomalies…). Tout cela prend du temps, on estime ainsi que 80% du code sert à l’exploration.
Préparation : il s’agit du pré-processing et du feature engineering. Le premier permet la suppression des variables trop faibles ou avec trop de champs manquants, la suppression des valeurs aberrantes (ex : 0 quand la data n’est pas disponible). Le second est parfois appliqué pour compléter la préparation afin de calculer de nouvelles caractéristiques utiles aux futurs modèles sur la base de données actuelles.
Notre conseil : adopter l’approche Agile !
« Fail Fast, Try Again »
Ne pas foncer tête baissée est primordial. Pour le bon déroulement du projet, une démarche agile (Scrum, Kanban) consistant en échanges itératifs avec confrontation des résultats avec les équipes métier (Expert métier et Product Owner) est selon nous la voie à suivre. Chaque item (partie d’un cas d’usage) dépend donc de la réussite des différents KPIs. Pour en savoir plus, nous vous conseillons aussi de lire cet article de référence (pour les anglophones) sur le sujet.
L’algorithmie : la valorisation des données
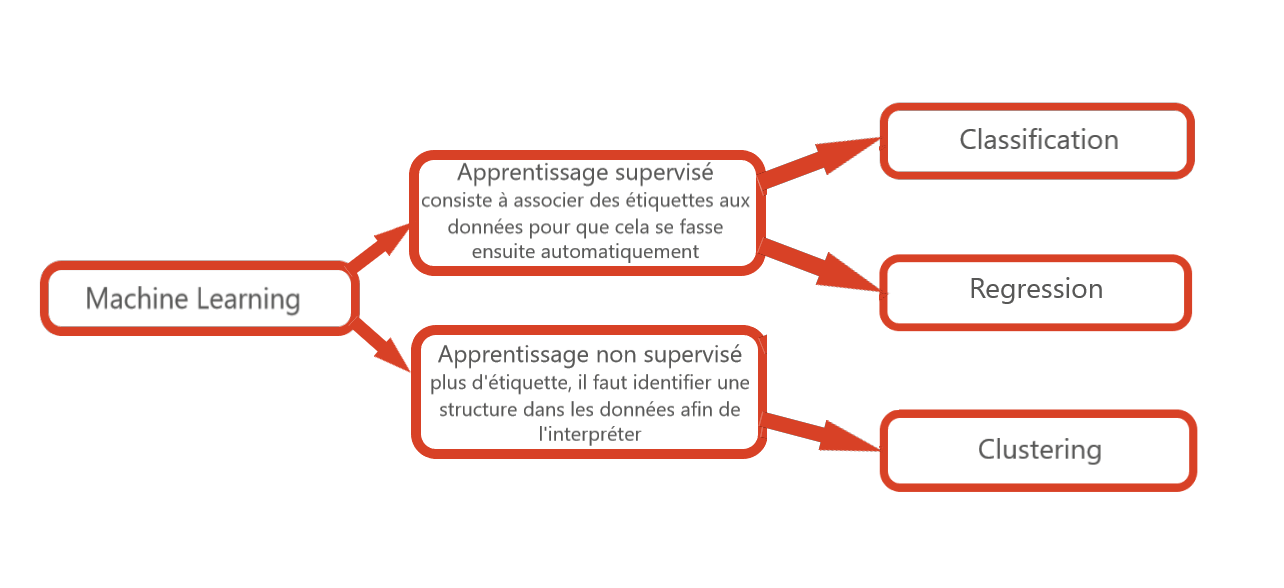
Les données sont donc prêtes, il s’agit maintenant d’en tirer de la valeur. Pour cela il faut mettre en place des algorithmes, souvent de Machine Learning, tels que des méthodes de régression, de regroupement (clustering) ou encore de classification. On s’attardera ici sur les principaux cas métiers :
- La prédiction : en analysant l’historique et les tendances, la prédiction permet d’anticiper les ventes ou encore l’état des stocks.
- Les anomalies : il s’agit ici de détecter les données qui ne sont pas cohérentes avec l’ensemble d’un set de données, puis de déterminer si l’anomalie est avérée ou aberrante.
- La segmentation : c’est le fait de regrouper des données parcellaires mais qui ont des caractéristiques identiques (des clients de différentes régions mais avec un salaire similaire).
Vous êtes maintenant un connaisseur chevronné du Data Lab et du POC (on ne devient expert qu’en lisant le livre blanc), mais connaissez-vous l’importance d’échanger avec les métiers lors d’un projet de Data Science ?





