
Vous utilisez ou souhaitez utiliser le machine learning, mais vous voulez évaluer vos modèles ? Comment les évaluer ?
Nous vous expliquons les analyses et métriques dans cet article.
1. Qu’est-ce que le machine learning ?
A. Machine learning : définition
Selon Talend, le machine learning est une technique de programmation informatique qui utilise des probabilités statistiques pour donner aux ordinateurs la capacité d’apprendre par eux-mêmes sans programmation explicite.
Comme nous l’avons vu précédemment dans cet article, il existe trois catégories de machine learning :
- l’apprentissage supervisé,
- l’apprentissage non supervisé,
- l’apprentissage par renforcement.
B. Définir un bon modèle de machine learning
Définir un modèle de machine learning est important, mais encore faut-il qu’il soit pertinent. En apprentissage supervisé, l’objectif est de créer des modèles qui généralisent la situation apprise, c’est-à-dire que face à de nouvelles données, la machine est capable d’élaborer des modèles prédictifs.
Il faut cependant faire attention, car de bonnes performances sur le jeu de données qui a permis l’apprentissage ne garantit pas de bons résultats sur de nouvelles données. On cherche donc à modéliser une analyse qui reflète la complexité de la nature des données en évitant les écueils du sous-apprentissage et du surapprentissage.
Il est également important de définir un modèle qui ait un temps de calcul convenable et une utilisation des ressources en mémoire raisonnable pour que l’algorithme d’analyse soit utilisable.
2. Comment évaluer les modèles de machine learning ?
Il existe plusieurs façons d’évaluer les modèles de machine learning. Voici quelques exemples :
A. La validation croisée en machine learning
Dans le cadre d’un apprentissage supervisé, comment connaître la performance d’un modèle de machine learning sur des données dont l’étiquette est inconnue ?
L’idée est de simuler le fait de ne pas connaître les étiquettes sur le jeu d’apprentissage dont les étiquettes sont connues. On va donc séparer le jeu d’apprentissage en deux parties : une pour l’apprentissage et une pour le test. On va ensuite appliquer le modèle sur le jeu de test et le comparer à leurs étiquettes connues pour prédire les performances. Cela nous donne une mesure de performance.
Pour affiner cette valeur, on utilise la validation croisée qui consiste à effectuer cette opération à plusieurs reprises de telle sorte que les ensembles de données connues soient à tour de rôle utilisés comme données d’apprentissage et données de test. On coupe donc les données connues en parties égales dans la mesure du possible (folds en anglais) et on utilise à chaque fois une partie comme jeu de test et le reste comme jeu d’apprentissage.
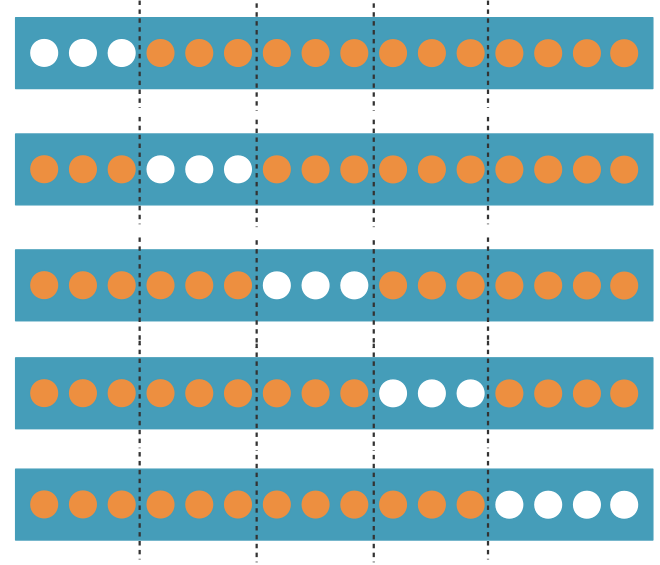
La validation croisée permet donc d’évaluer un modèle de machine learning en ayant la moyenne des performances et l’erreur type sur chacun des folds ou en évaluant les prédictions faites sur l’ensemble des données.
Pour des raisons de temps de calcul, on utilise généralement cinq ou dix folds.
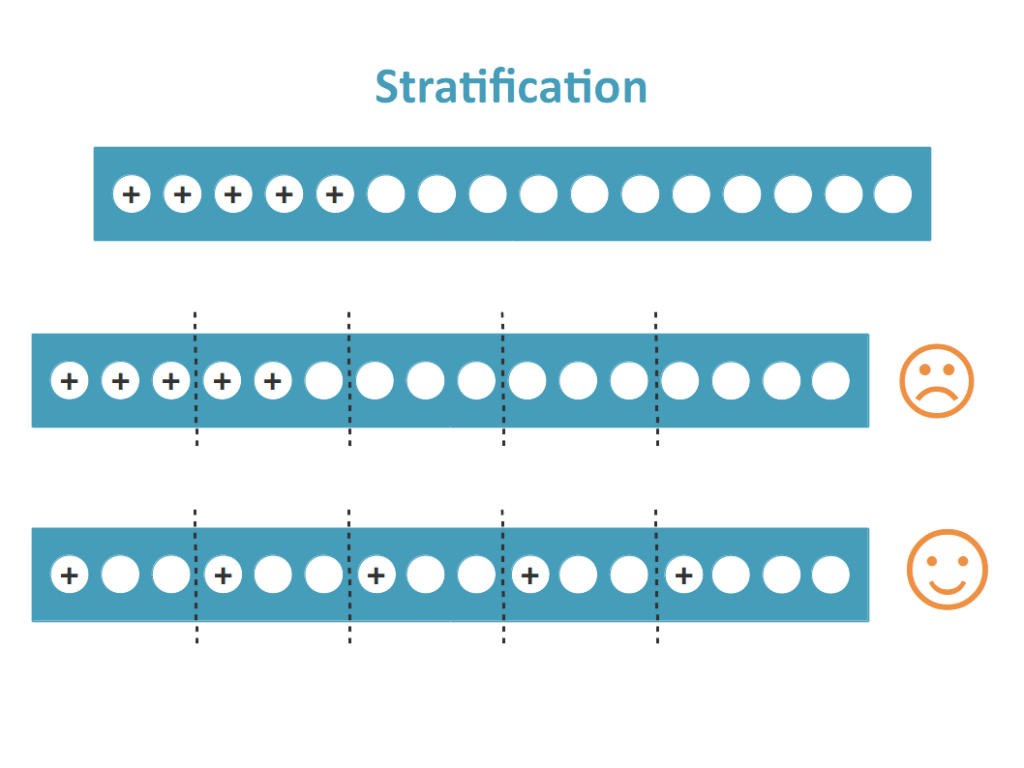
Pour cette méthode, il est important d’appliquer la stratification. La stratification est un processus qui consiste à diviser les données connues en folds homogènes avant l’échantillonnage, c’est-à-dire répartir les étiquettes pour que chaque fold ressemble au maximum à un petit jeu de données connues.
B. La matrice de confusion en machine learning
La matrice de confusion est un outil qui permet de savoir à quel point le modèle de machine learning est « confus », ou qu’il se trompe. Il s’agit d’un tableau avec en colonne les différents cas réels et en ligne les différents cas d’usage prédits.
Prenons l’exemple d’un test médical, la matrice sera la suivante :
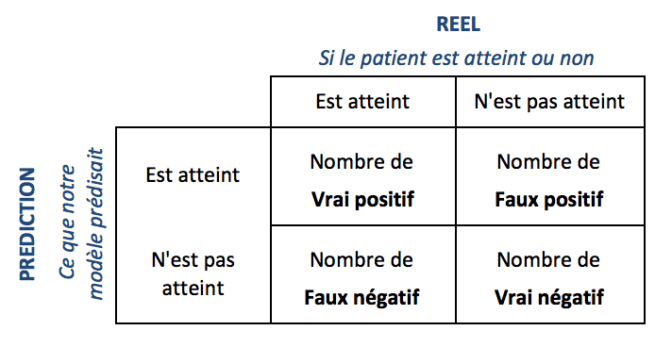
On obtient donc les quatre valeurs suivantes :
- Vrai positif (VP), les valeurs réelles et prédites sont identiques et positives. Le patient est malade et le modèle le prédit.
- Vrai négatif (VN), les valeurs réelles et prédites sont identiques et négatives. Le patient n’est pas malade et le modèle prédit qui ne l’est pas.
- Faux positif (FP), les valeurs réelles et prédites sont différentes. Le patient n’est pas malade, mais le modèle prédit qui l’est.
- Faux négatif (FN), les valeurs réelles et prédites sont différentes. Le patient est malade, mais le modèle prédit qui ne l’est pas.
L’étude de ces valeurs prédictives permet de définir si le modèle de machine learning est fiable, dans quels cas il commet des erreurs et dans quelle mesure.
Pour approfondir le sujet, nous vous conseillons la formation d’OpenClassrooms : Evaluez les performances d’un modèle de machine learning.
Il est donc important de choisir un modèle de machine learning adapté au besoin. Il est ensuite possible d’évaluer ce modèle avec différentes méthodes comme la validation croisée et la matrice de confusion.
Saagie et le Machine Learning
Saagie ne pourra pas remplacer l’expertise d’un Data Scientist, mais il améliorera ses processus de travail en jouant le rôle clé de catalyseur de ses projets de machine learning.
Saagie est une plateforme révolutionnaire qui combine intelligence artificielle et machine learning pour offrir une solution complète de gestion de projets. En intégrant des fonctionnalités avancées de machine learning, Saagie permet aux utilisateurs de développer, déployer et surveiller efficacement des modèles prédictifs. Que vous soyez un expert en data science ou un utilisateur non technique, Saagie simplifie le processus en fournissant des outils conviviaux et des interfaces intuitives. Avec Saagie, vous pouvez explorer et analyser vos données, créer des modèles personnalisés, les entraîner sur des ensembles de données massifs, et déployer vos modèles pour des prédictions en temps réel. Grâce à son infrastructure évolutive et ses capacités de suivi des performances, Saagie vous permet de maximiser les avantages du machine learning et de prendre des décisions éclairées pour votre entreprise.





