
Cet article vous explique le phénomène du surapprentissage (overfitting) en data science. Il s’agit de l’un des problèmes les plus récurrents dans le Machine Learning. Nous vous donnons des pistes pour le détecter, le dépasser, et effectuer vos prédictions avec précision.
Comment définir le concept ?
Vous avez sûrement déjà expérimenté, à l’heure du Big Data et de l’intelligence artificielle, une situation qui ressemble à la suivante : vous lancez l’apprentissage d’un modèle de Machine Learning, et vous obtenez des résultats très prometteurs, suite auxquels vous lancez rapidement le modèle en production. Or, quelques jours après, vous vous apercevez que vos clients vous appellent pour se plaindre des mauvais résultats de vos prédictions. Que s’est-il passé ?
Très probablement, vous avez été trop optimiste et vous n’avez pas validé votre modèle avec la bonne base de données. Ou plutôt, vous n’avez pas utilisé votre base d’apprentissage de la bonne manière. Nous allons voir, dans la suite de cet article, comment éviter de commettre à nouveau cette erreur.
Quand on développe un modèle d’apprentissage, nous essayons de lui apprendre comment atteindre un objectif : détection d’un objet sur une image, classification d’un texte en fonction du contenu, reconnaissance vocale, etc. Pour ce faire, nous partons d’une base de données qui va servir à l’entrainement du modèle, c’est-à-dire à son apprentissage pour arriver au but voulu. Or, si nous ne faisons pas bien les choses, il se peut que le modèle considère comme validées, uniquement les données qui ont servi à faire l’apprentissage, ne reconnaissant aucune autre donnée qui soit un peu différente de la base initiale. C’est ce phénomène que l’on appelle « surapprentissage ».
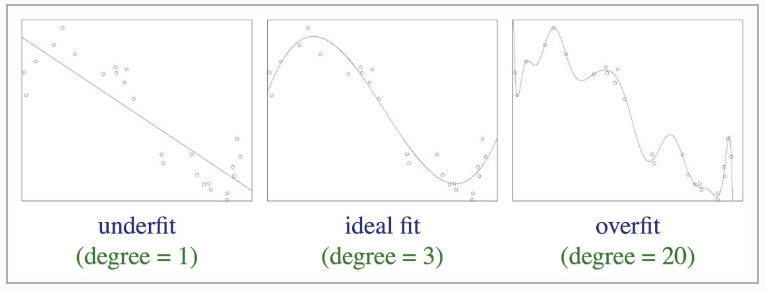
Pour ceux qui sont plus à l’aise avec les représentations spatiales, ci-dessous vous pouvez regarder les trois scénarios différents à l’issue d’un apprentissage. Les points correspondent aux données d’apprentissage, et la courbe représente la réponse de votre modèle. À gauche, vous avez un modèle qui n’a rien appris car il correspond tout simplement à un modèle linéaire qui répond exactement à la même chose qu’on lui demande. Au milieu, vous avez un modèle idéal, qui a compris le problème qu’on lui apprend, mais qui garde une certaine généralisation par rapport aux données d’apprentissage. À droite, il s’agit d’un modèle qui souffre de surapprentissage. En effet, il s’est trop spécialisé sur la base d’apprentissage, et ne fait que coller aux données initiales. Ce modèle sera inutilisable sur des nouvelles données car il ne reconnaitra pas d’autres données.
Comment détecter et résoudre le surapprentissage en Machine Learning ?
De manière intuitive, si votre modèle exhibe des très (trop !) bonnes performances avec les données d’apprentissages, et qu’il n’arrive pas, bizarrement, à faire un bon travail quand il est en production, alors il y a de fortes chances qu’il s’agisse d’un problème de surapprentissage. Plus en profondeur, vous pouvez vous servir de deux notions basiques en Machine Learning : le biais et la variance.
- Le biais est une erreur correspondante à la solution générale trouvée : par exemple, notre modèle a appris simplement à détecter des formes rectangulaires alors que vous vouliez détecter des camions sur des images.
- La variance est une erreur de sensibilité aux données d’apprentissage. C’est-à-dire que le résultat de l’apprentissage va beaucoup varier en fonction de données. Le modèle n’est pas stable. Quand le modèle souffre de beaucoup de variance, alors il y a un surapprentissage.
La solution passe par une bonne organisation de vos données initiales. Il vous faudra faire une « validation croisée ». En quoi cela consiste ? Pour un apprentissage normal, vous divisez vos données en données d’apprentissage et en données de test. Pour la validation croisée, vous allez simplement réaliser plusieurs apprentissages en faisant des itérations où vous allez varier la répartition d’apprentissage et test.
Ainsi, à la fin des itérations, toutes vos données auront servi aussi bien à l’apprentissage qu’au test. Le modèle ayant été contrôlé à travers ces itérations, vous aurez moins de probabilités de vous retrouver avec un modèle surappris. Ci-dessous vous avez une image pour vous expliquer graphiquement comment réaliser la validation croisée.
Construisez bien vos bases d’apprentissage, veuillez à qu’il y ait une bonne variabilité de données. Par exemple, si vous cherchez à détecter des chiens sur une photo, utilisez des photos contenant plusieurs races, tailles, couleurs et positions différentes.
Si, pendant le processus d’apprentissage, vous observez que le modèle converge trop rapidement vers une solution optimale, alors méfiez-vous, il y a des chances qu’il ait surappris.
Si vos données sont trop pauvres, votre modèle aura du mal à apprendre l’objectif souhaité et vous allez vous retrouver avec beaucoup de variance.
Vous pouvez utiliser plusieurs modèles différents pour comparer les résultats avant de lancer un modèle en production. Essayez par exemple un SVM pour valider les résultats d’un réseau de neurones.
Saagie pour optimiser vos projets machine learning
Saagie offre des fonctionnalités qui aident à détecter et à résoudre le surapprentissage. En intégrant Saagie à vos projets de machine learning, vous bénéficiez d’un environnement complet pour la gestion du cycle de vie des modèles. Saagie facilite la création de pipelines de machine learning, la division des données en ensembles d’apprentissage et de test, ainsi que la validation croisée.
En utilisant la plateforme DataOps Saagie, vous pouvez organiser vos données d’apprentissage de manière appropriée, en veillant à ce qu’il y ait une bonne variabilité de données représentatives du problème à résoudre. Cela vous permet de minimiser les risques de surapprentissage en incluant des exemples diversifiés, tels que différentes races, tailles, couleurs et positions dans le cas de la détection de chiens sur des photos.
En intégrant Saagie à vos projets de machine learning, vous pouvez améliorer la performance et la fiabilité de vos modèles, garantissant ainsi des prédictions plus précises et plus généralisables.





