
Still struggling to make your Big Data / AI project happen? Here is our last piece of advice on the matter, but don’t hesitate to check out our previous articles about the Data Lab and its organisation, the business vision, the POC, the traps and the Data Fabric. Now, let’s find out about the DevOps practices!
What is the DevOps Approach?
Based on the Lean and Agile principles, the DevOps approach brings together operational managers and developers. We speak of “dev” for all that is related to software development, “ops” for the operation and administration of its infrastructure. DevOps practices aim to unify the whole. In practice, it is the automation and monitoring of each step of the creation of a software, from its development to its deployment, but also its operation over time.
DevOps is commonly associated with agility that promotes short cycles, iteration, or more frequent deployments. The purpose of this approach is to continuously deliver a software that is therefore modifiable, which allows both to take into account customer feedback, but also to seize more business opportunities. The main benefits of these practices are also the collaboration of different teams which leads to an accelerated deployment and, therefore, to reduced costs.
Embrace DataOps
Even if DevOps is often only linked to computing, new considerations emerged with data processing, and the approach got replicated and called DataOps. DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization. Basically it is the same approach, applied to data processing applications.
IT teams (IT Ops managers, IT Architect & Coders), Analytics teams (Data Engineers and Data Scientists) and Business (Data Analyst and Data Steward) need to work closely together, now more than ever. To make it easier, collaboration and iterations are key. The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data and data models.
DataOps uses technology to automate the design, deployment and management of data delivery with the appropriate levels of governance and metadata. To show you the specifics, let’s take a look at the DevOps loop and apply it to a data environment.
The Different Steps
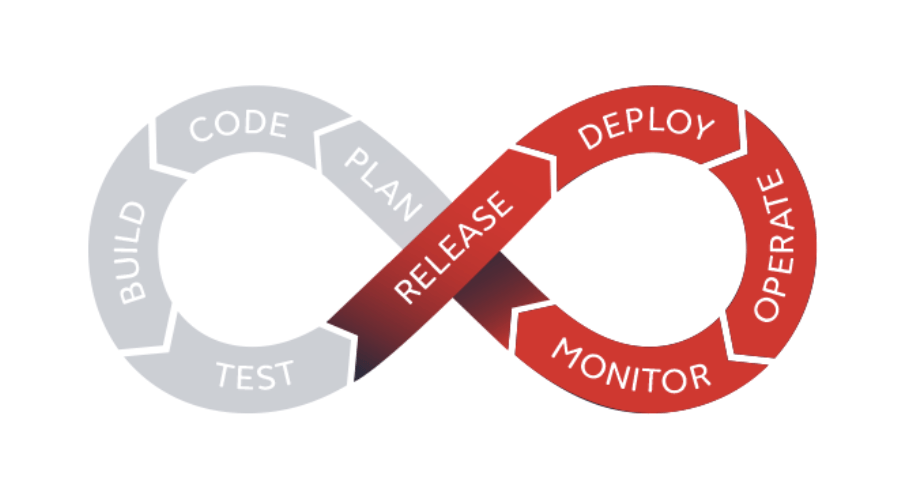
Release & Deploy: These steps being complementary, we introduce them together. To put it simply, the “release” stage is the output of a first stable version of a “package” (set of computer files necessary for the execution of a software, integrating for example code and configurations). The “deploy” stage revolves around its deployment in a specific environment (development, recipe, pre-production, production).
Operate: The “Operate” stage of the DevOps loop will consist “operating” the previously deployed developments (jobs). And this step will break down as follows: scheduling / orchestrating jobs, monitoring the status of all processes, diagnose production issues and control the status and the versions of the different frameworks.
Monitor: It is a work of monitoring and continuous watch. In the Data & Analytics world, this consists in measuring the effects of the model and its subsequent versions on the use case. To summarize, have the improvements made to my use case / model had an impact on my business? (For example, following an update of my churn model, did I get an increase in my false positives?).
Iterate: Traditional development methods (V-cycle type) are not optimized to effectively integrate a feedback loop from business teams. “Iterate” involves offering a new version of a data project by minimizing the delay between two versions (from months to weeks, weeks to days, days to hours).
According to IDC, more than half of French companies who implemented DevOps practices into a project now actually apply it to all of their IT developments. Another proof of its success, 80% of Fortune top 1000 firms will have DevOps implemented by the end of 2019. So, what about DataOps ? Gartner thinks it is one of the key to industrialize a Big Data / AI project.




