
This week, Julien Fricou, Data Engineer at Saagie, was able to ask Alain Hélaïli, Principal Solutions Engineer at GitHub, about the use of the platform. The GitHub CI / CD will hold no secrets for you!
How to create a workflow (yaml file, graphic editor)?
With GitHub Actions, we decided that the philosophy would be to do “pipeline as code” (workflow as code). It is a text editor, therefore a yaml file, with several editing possibilities:
- Via the GitHub graphical interface
- Via other text editors like Visual Studio Code
We chose the “as code” method, with a textual creation, and a visualization of the executions.
The use definition files of build is not new. This principle is found in most CI tools (for Continuous Integration) on the market, such as Jenkins with Groovy, GitLab CI, Travis CI, Circle CI files. We then speak of “Pipeline as Code”, a term resulting from the practice of DevOps. The advantage is being able to store and version the file (often .yaml) defining our pipeline directly.
Is it possible to “convert” a CI / CD chain from another tool (jenkins for example) into a github workflow? If not, what would be your advice?
The conversion aspect is a subject in the maturation phase, this functionality is not yet implemented. The problem in the CI industry is that everyone has special concepts. I don’t think we’ll ever be able to do a completely seamless integration of a workflow from Jenkins to GitHub for example. There is almost always a part to be done manually, quite simply because it is not only a question of a syntax, but of an entire ecosystem to migrate. Some plugins exist or not depending on the tool, and do not necessarily have the same roles. The goal is therefore to reduce this manual part as much as possible, but we will probably not be able to eliminate it completely.
The assessment today is that our customers prefer to keep their pipelines the same because there is perfect compatibility between GitHub and Jenkins or some other tool. When they need to create a new pipeline or do a refactoring, they take the opportunity to switch to GitHub Actions.
How to trigger actions from external events?
It’s all going to depend on what an external event is. At GitHub, we view externality differently from other tools. We have a lot more internal events than other CI solutions. In GitHub Actions, we decided not to just react to code push events or external triggers. We believe that any event can trigger pipelines. For example, if an issue is created or a new member added to a project, it triggers a pipeline.
However, there are four methods for triggering actions:
- APIs: we have APIs made for listening to orders. For example, we have at our disposal a deployment API that was designed as a middleware to ask GitHub to trigger a deployment workflow. So, GitHub will transmit this deployment message to the applications that listen to this message. GitHub Actions is nothing more than a way to listen to these orders, a way to trigger a pipeline.
- Dispatch Repository: this is an event that we send to the repository. This event was created a while ago, it was possible to subscribe to it through webhooks, but it is now handled automatically in GitHub Actions.
- Workflow dispatch: it allows manual triggering of a specific pipeline.
- Crontab: this feature allows you to schedule the execution of a pipeline.
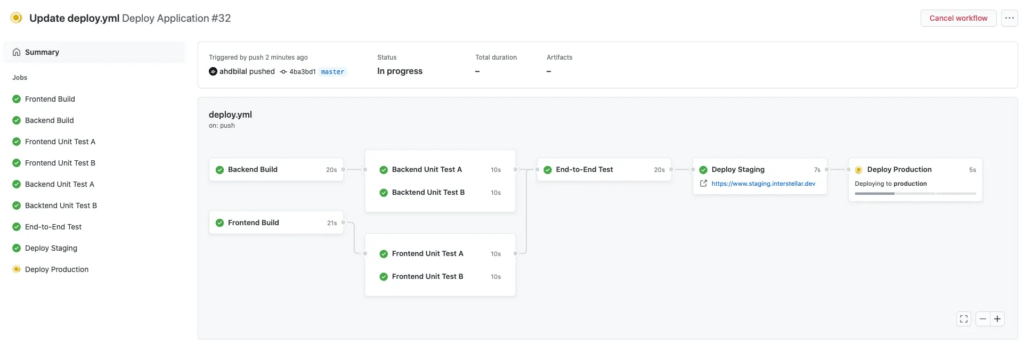
How to monitor actions? Execution time, number of executions ...?
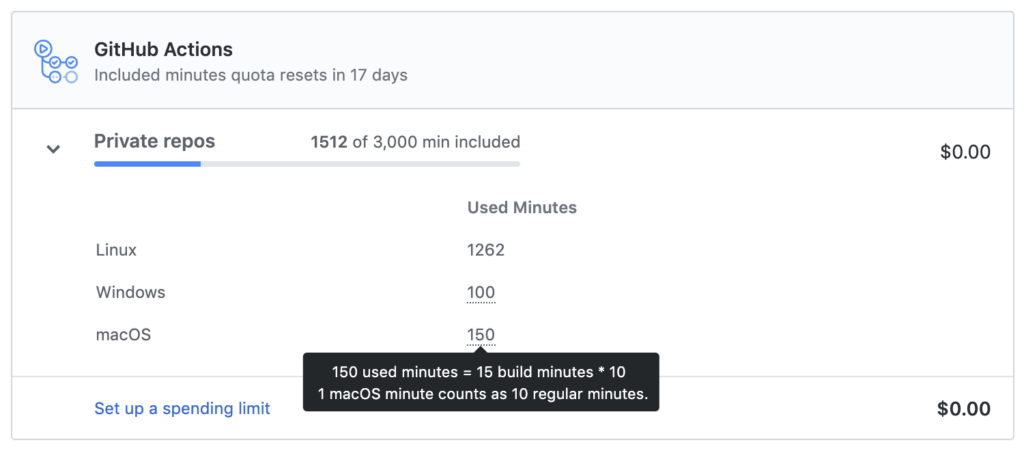
In the GitHub graphic interface, it is quite possible to view the execution time. You only need to go to the “settings” tab of the organization, then to the “Billing” page to find the aggregation of all the time consumed by the GitHub Actions (in minutes). This is also where it is possible to export a usage report with a detail per repository.
In addition, all this data is also accessible by API: users can create their own monitoring tables, workflow by workflow. All this can be done on Rest or GraphQL, APIs allowing to retrieve all this information.
Why choose hosting on GitHub over internal hosting?
Nowadays, choosing between internal or external hosting is not mandatory. Indeed, the GitHub Enterprise offer is based on 2 pillars:
- GitHub Enterprise Cloud (SaaS) : Single Sign-On (SSO), support, audit logs
- GitHub Enterprise Server : either public cloud provider, or physical servers
Users can now choose the first, the second, or both solutions depending on the project, at no extra cost.
Those who are still on internal hosting generally have constraints on the location of the data, data centers, etc. It is also often because IT is not yet ready for cloud deployment. We must also not forget the inertia of the “on prem” culture, which we do not yet know where it will lead.
On the other hand, the advantage of SaaS is to avoid the management of an infrastructure and this saves a significant amount of time. This option also allows you to access new features faster than on physical servers.
With Covid-19, some companies have found that they are not well enough equipped for developers to code remotely. In the last months, we have therefore seen a change in practices: many companies, previously reluctant to the cloud, have turned to SaaS because it was no longer possible otherwise.
What are the security best practices for the build and publishing of private Docker images?
If I open the debate beyond Docker, we have worked a lot on the notion of securing dependencies (for example Docker image or JavaScript library) with our Dependabot tool. If there are vulnerabilities in versions, Dependabot recommends upgrading to updated versions which offer a solution for the flaw. However, it is essential to remain attentive to the origin of the dependencies – where they come from, how they were created – and to put in place the tools that allow you to track vulnerabilities and be able to update them very quickly.
Dependabot can also systematically monitor technologies used in projects and send pushes encouraging users to upgrade. In this way, we are able to be proactive, and limit the technical debt of users in the long term.
Besides, we have for some time had the notion of registry on out platform, called GitHub Packages, where a Docker registry is available and we are currently in the process of moving to a Container registry in order to integrate the Open Container Initiative (OCI) standard which standardizes more aspect of the management of a container. It will of course always be possible to store elements in a public or private way.
How to manage the versions of libraries / softwares used by the runners (new version of gradle, change of Python environment ...)?
This is a big topic! With GitHub Actions, we are trying to provide a hybrid system of use, cloud or on-premise mode, strategy, and Virtual Machine (VM) or Container.
If we are based on the simplest case, i.e. in cloud mode, and we want to run a pipeline on an agent provided by GitHub, then we will be directly on VMs and it will be easier to configure VMs rather than installing a software. Indeed, the VMs that we make available are already loaded with softwares adapted to Ubuntu, Windows or Mac. So, rather than installing Java for example, an action gives the command to configure a specific version of Java. If the requested version is compatible with the pre-installed one, nothing happens. Runtime setup time is much faster this way, which will optimize developer feedback time, provided the environment offered by GitHub is tailored to user needs.
In the event that users have more specific needs on an ad hoc basis, then we perform installations, but this requires download and installation times for each run.
On the other hand, in the case where specific needs are more frequent, it is more relevant to create a container with a pre-installation of all the software necessary to run the pipelines. In this situation, container download time will be required, but it will no longer be necessary to load and install these software at each run, so there will be no more time to set up the entire environment. .
Finally, the third option would be to have on prem agents, hosted in any environment. At this time, it is necessary to know the absorption capacity of varieties of environments of the agent, in order to know the number of agents to house. These are issues that are more difficult to manage on a daily basis.
From experience, it is usual to standardize the tools used. Some of our customers have deployed agents on Kubernetes clusters, which has allowed them to create groups of labeled agents. This notion of label will help determine what types of agents are needed to run the pipelines.
Why use GitHub workflows rather than an external tool like Jenkins, Travis, etc? What are the advantages and disadvantages?
The main advantage of using GitHub Actions when you are already a seasoned GitHub user is that there is no integration to do. Second, the ability to choose between a Cloud or on prem deployment allows for increased agility. Finally, we now offer access to Mac resources for iOS developments, which also saves valuable time.
Traditionally, with many of the existing CI solutions, using workflows involves a significant level of complexity. In fact, building a pipeline is like creating a lot of shell code or manipulating a lot of Docker images, which can sometimes be difficult to debug. With GitHub actions, if I need to use Docker, I will directly take the GitHub action that was created, give it the right parameters, and it is Docker that provides preconfigured actions allowing me to write very little code in fine. Today, the entire ecosystem (Azure, AWS, Sonarqube) makes this kind of action available, which prompts developers to do little configuration and write very little code.
Users can also create their own actions to enrich their pipelines. There are two ways to do this.
- Either by providing a Docker container
- Or by creating an action in Javascript because the node environment is already present.
As for the downsides, in case the users already have an existing Jenkins or Travis, you have to relearn the actions. So there could potentially be a learning curve problem.
In addition, GitHub Actions is only 18 months old. We therefore still need to reflect on certain functionalities. The takeaway is that GitHub Actions does not yet have the same level of industrialization as Jenkins, for example, but neither does it have the complexity. We hope to make a number of improvements, especially on the industrialization part, in the coming months!
In the future, would it be possible to have “full” workflow templates for certain types of projects?
In a GitHub organization, it is possible to access a repository (named .github) in which are stored templates (issue template, settings template, pipeline template, etc.) available to the entire organization . Thus, when creating a new pipeline, the appropriate templates will automatically be offered to users. This is a first step.
We are now thinking about the notion of fragment of pipelines, with the libraries of fragments of pipelines that will be able to live independently of each other. It is also possible to have pipelines calling others via a “repository dispatch” event.
Can we or will we be able to test the workflows locally in order to reduce the feedback loop?
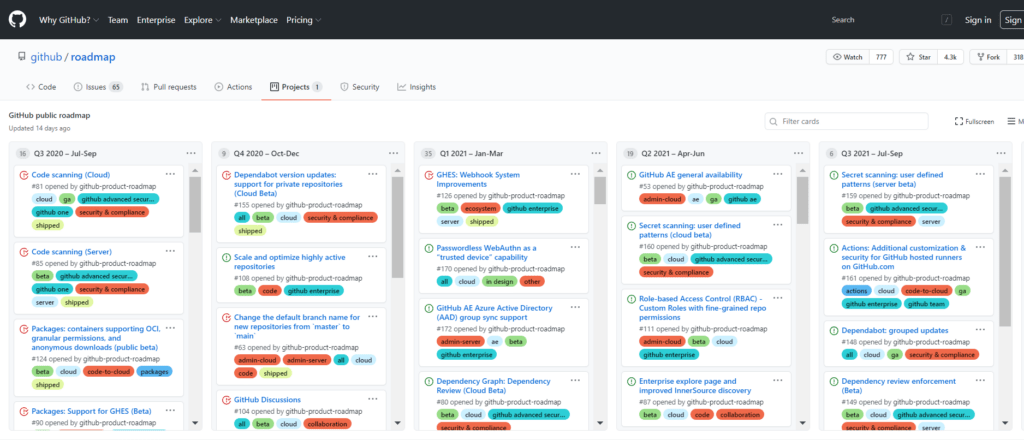
I would like us to go further on this subject, but we have not yet addressed it. However, there is an opensource project (https://github.com/nektos/act) which allows you to test a workflow in local, which helps in particular to debug an action, and to test its outputs. We would obviously like to go even further, which is why we have developed a roadmap available on our site, allowing our users to have visibility on the next features.

After 15 years in the software industry, Alain joined GitHub in 2015 as a Solutions Engineer. He is dedicated to strengthening relationships between developers and operations teams, and helping companies understand how to build better software, faster. A strong supporter of Open Source, Alain has a very interesting take on how businesses use GitHub to collaborate on code and create amazing things every day.




