
January tends to be a good time for European senior executives to get inspiration from innovative startups by visiting CES in Las Vegas. They often accept at the same time invitations from large software companies in Silicon Valley and Seattle delivering a smoothly packaged marketing message on the advantages of a Cloud strategy. The invariable result is a strategic decision “we need to do more on the Cloud’.
How to Decide to Move Projects on the Cloud?
At the same time Chief Data Officers or Business Owners often get frustrated by the incapacity of IT departments to provide access to data and the appropriate tools in time to experiment with BI and analytics-driven use cases. They also decide to move projects to the Cloud.
Although motivations may differ, the results tend to be similar:
On the one hand:
- Enthusiasm on the potential of the Cloud (on demand, pay-as-you-go, elasticity…)
- A great way to experiment use cases and new technologies
While on the flip side
- Setting up data projects requires a variety of tools (and skill sets to use them) that differ between public cloud vendors.
- While initial pricing is attractive there is a clearly identified risk of vendor lock-in as soon as you move away from basic IaaS Compute and Storage services
- There are compliance concerns on data location, the US Cloud act, anonymization of datasets and data governance
- Organizational bottlenecks exist to make the right people work together on data
- Lack of cohesion with legacy IT systems, with Cloud projects risking to be dubbed as non-core or even shadow-IT.
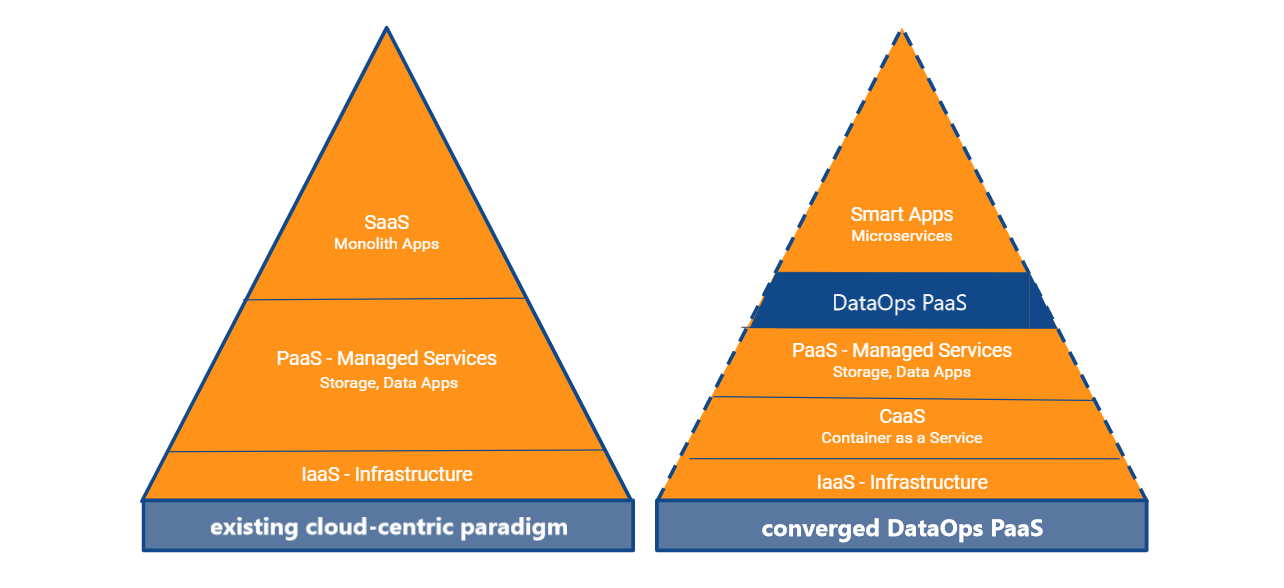
The DataOps PaaS
Few data projects are industrialized and this is most particularly the case with the more complex AI-driven initiatives: hard to achieve ROI, lots of time spend on plumbing and severe project delays. The challenge is how convergence will materialize in our complex, fast-moving and hybrid world with algorithms that require continuous development and deployment.
Enter Kubernetes, the container orchestration standard that is rapidly gaining ground. Kubernetes through its inherent auto-scaling and resilience capabilities enables a level of abstraction from the compute infrastructure. This layer is called CaaS, container as a Service. Although this is a giant step forward, it does not mean you’ll be able to obtain portability and coherence between on-prem IT and Cloud straight away.
The paradigm show the emergence of a new layer: the DataOps PaaS.
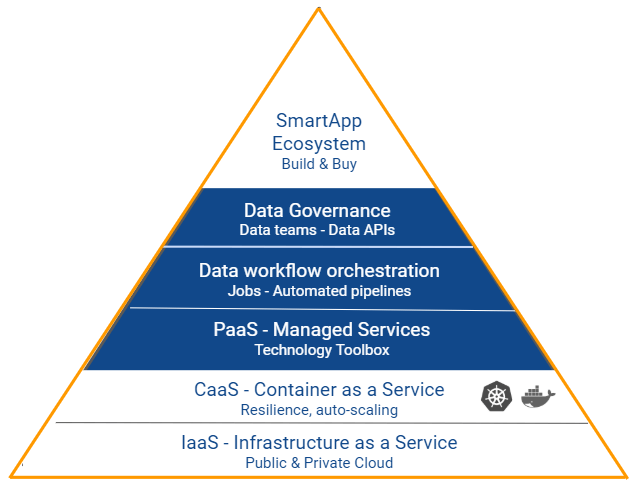
To succeed convergence, DataOps PaaS should combine:
An open and extensible technology toolbox packaged as a Managed Service (PaaS). Obviously, this toolbox should integrate seamlessly with existing Cloud Managed Services and storage in particular. Since the open-source driven technology ecosystem for big data and analytics is innovating fast, this toolbox should be updated with the latest frameworks and be able to run different versions concurrently.
A data workflow orchestrator to make sure that jobs from heterogeneous data technologies (batch and real-time ingestion, processing, machine and deep learning) are prepared, combined into pipelines and monitored in a standardized manner. A key requirement is portability not only with a regular industrialization life cycle in mind (dev/test, pre-production, production…) but also between different infrastructure deployments. Hereby a higher abstraction level is created: changing an underlying data technology will not have any impact, a DataOps Studio will take care of everything. In addition, the orchestrator should integrate with IT scheduling tools, DevOps tools and security components and provide audit and tracking capabilities for compliance reasons.
A data governance layer with metadata to secure data access and allow teams to collaborate efficiently on data projects. Security and an outstanding user experience will finally bridge the gap between IT (infrastructure, technology selection), Datalabs (application development, data engineering, data science) and business teams. In addition, this layer may provide APIs to facilitate access and exposure of datasets.
These layers should allow you to build an Application ecosystem layer ensuring self-service capabilities for all stakeholders. This ecosystem should combine both internally developed applications and externally bought-in components (data wrangling, auto-ML, deep learning training service, data catalogue software, data visualization tools or just any AI startup that has a great solution for a niche requirement).
Creating a DataOps PaaS with a technology abstraction layer, the capacity to work in cross-functional teams and an open ecosystem are powerful enablers to jumpstart towards high-value business use cases, while wasting less time on low-value data plumbing. ROI on data projects definitely remains the most important driver for large-scale industrialization of AI.




