
This article explains the phenomenon of overfitting in data science. It is one of the most recurrent problems in machine learning. We give you some clues to detect it, to overcome it, and to make your predictions with precision.
A definition of overfitting
You have probably already experienced, in the age of big data and artificial intelligence, a situation that looks like the following: you start learning a machine learning model, and you get very promising results, after which you quickly launch the model into production. However, a few days later, you realize that your customers call you to complain about the poor results of your predictions. What happened?
Most likely, you were too optimistic and did not validate your model with the right database. Or rather, you didn’t use your learning base in the right way. In the rest of this article, we will see how to avoid making this mistake again.
When we develop a learning model, we try to teach it how to achieve a goal: detecting an object on an image, classifying a text according to its content, speech recognition, etc. To do this, we start from a database that will be used to train the model, that is, to learn how to use it to achieve the desired goal. However, if we don’t do things properly, it is possible that the model will consider as validated, only the data that has been used to train the model, not recognizing any other data that is a little different from the initial database. This phenomenon is called overfitting.
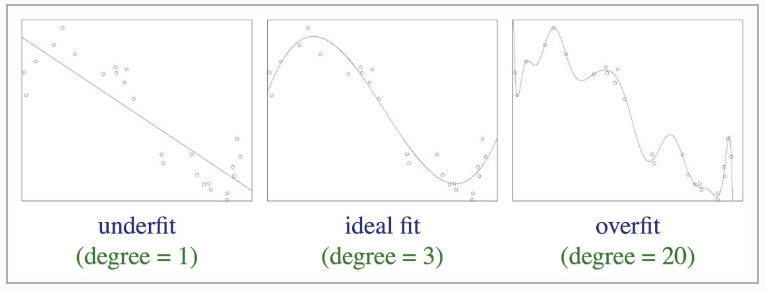
For those who are more comfortable with spatial representations, below you can look at the three different scenarios at the end of the learning process. The points correspond to the training data, and the curve represents the response of your model. On the left, you have a model that hasn’t learned anything because it simply corresponds to a linear model that responds to exactly the same thing it is asked to do. In the middle, you have an ideal model that has understood the problem it is being taught, but still has some generalization about the learning data. On the right is a model that suffers from overfitting. It has become too specialized on the basis of learning, and only sticks to the initial data. This model will be unusable on new data because it will not recognize other data.
How to detect and solve overfitting in machine learning?
Intuitively, if your model performs very (too!) well with the learning data, and strangely enough, it doesn’t do a good job when it’s in production, then chances are it’s an overfitting problem. In more depth, you can use two basic concepts in machine learning: bias and variance.
- Bias is an error corresponding to the general solution found: for example, our model simply learned to detect rectangular shapes when you wanted to detect trucks on images.
- The variance is an error of sensitivity to the learning data. That is to say that the learning result will vary a lot depending on the data. The model is not stable. When the model suffers from a lot of variance, then there is overfitting.
The solution lies in a good organization of your initial data. You will need to do a “cross-validation”. What does this consist of? For normal learning, you divide your data into learning data and test data. For cross-validation, you will simply perform multiple learning by doing iterations where you will vary the distribution of learning and test data.
Thus, at the end of the iterations, all your data will have been used for both learning and testing. Since the model has been controlled through these iterations, you will be less likely to end up with an overfitted model. Below you have a picture to explain graphically how to perform cross-validation.
Build your learning base well, please ensure that there is good data variability. For example, if you are looking to detect dogs in a photo, use photos that contain several different breeds, sizes, colors and positions.
If, during the learning process, you observe that the model converges too quickly towards an optimal solution, then be wary, chances are it has overfitted. If your data is too poor, your model will have difficulty learning the desired objective and you will end up with a lot of variance. You can use several different models to compare results before you run a model in production. For example, try an SVM to validate the results of a neural network.




