
Big Data, Data Science, Machine Learning, predictive algorithms… Many of those are now commonly used in the business world. In order to make their innovative projects happen, companies now decide to build up their own Data Labs. However, most of AI or Big Data projects, 80% of them according to Gartner, do not make it into production. We have been over the failure reasons, now it is time to talk about the solutions. The Machine Learning engineer could be one. Following up on O’Reilly’s article from Jesse Anderson about his role, we decided to put it in our own words and try to take it to another level. Our goal is to explain how he may be the missing link between Data Science and Data Engineering that could make it all work.
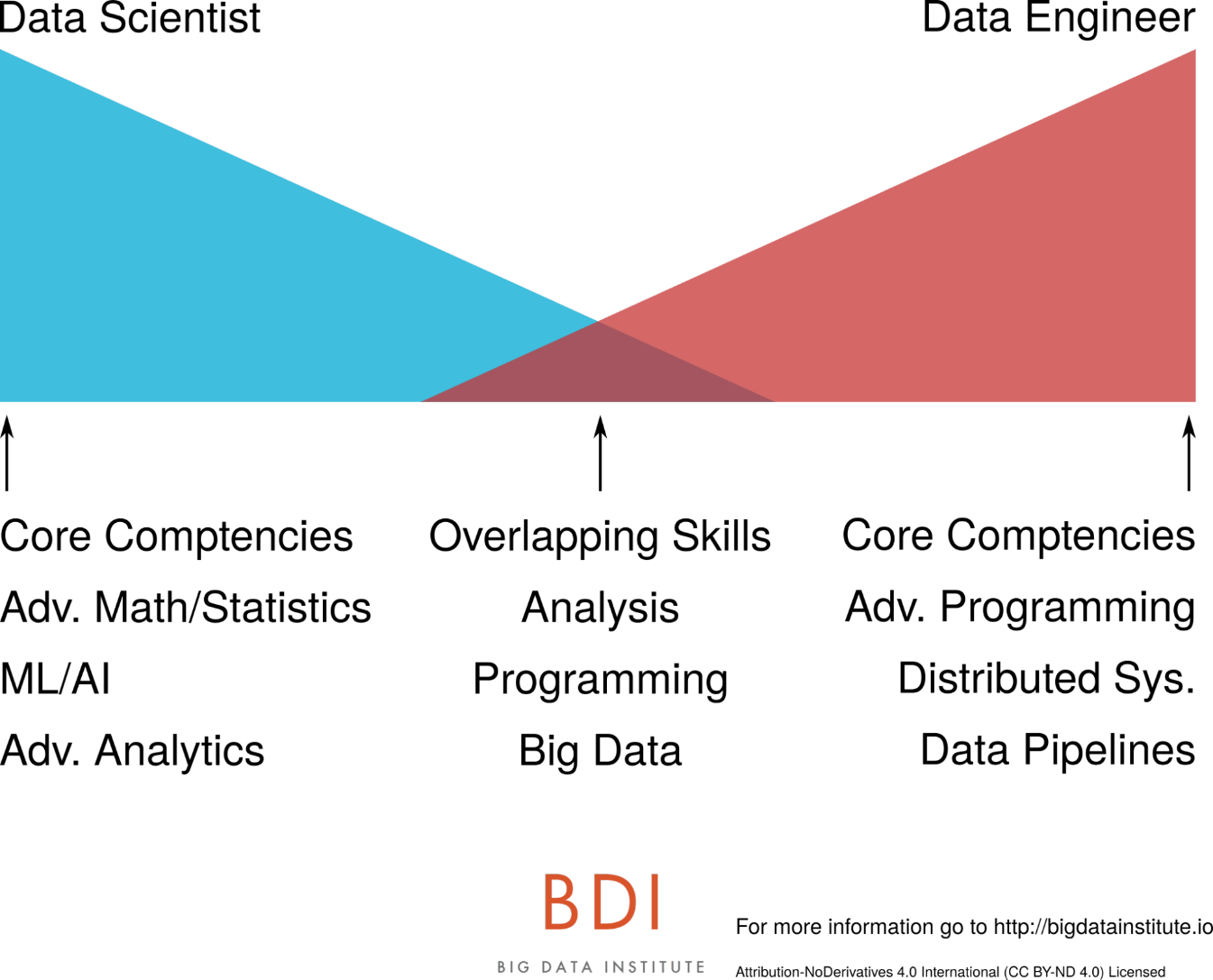
Data Scientist vs. Data Engineer
Why pitting one against the other ? Because many companies ask Data Engineers to do Data Science and vice versa. It can lead to team frustrations and tensions but most importantly, it may cause your project to fail. Their profiles and missions are different, so it needs to be clear so everyone can do what they do best. Jesse Anderson makes the distinction between the two pretty clearly, but we thought we would also give it a shot.
The Data Scientist : he has a mathematical and statistics background. He takes Analytics to another level creating AI algorithms from scratch using Machine Learning.
Put simply, he makes data come alive. He manages data processing and figures out ways to make sense of it. The “scientist” in his job title seems appropriate as he is closer to research than one would imagine. However, his business value puts him the heart of the company.
Data Scientists share with Data Engineers the need to be close to business. They need to be familiar with where the company stands and its goals to provide relevant insights at the right time. As these insights will help take business decisions, it also needs to be adapted to the people who will make those decisions.
An interesting fact we learned from O’Reilly’s “Data engineers vs. data scientists” about Data Scientists is that most of them learned to code by need. Doing statistics, coding may be the solution to overcome challenges and get deeper analyses. It does not mean that they are as good as developers or Data Engineers, but they know a few things.
The Data Engineer : he has a computer programming background in Java, Scala or Python in many cases. He is specialized in distributed systems and Big Data.
He is in charge of the data infrastructure, from its build to its maintenance. Without him, Data Scientists and many others can not work. He makes sure databases and Big Data process systems operate as they should. He is also responsible for the datasets modeling processes creation through exploration, acquisition and checking. In a nutshell, he keeps everything up and running.
In more concrete terms, his job is to create data pipelines. As easy as it seems, when it comes to Big Data, it is about making dozens of technologies work all together. He is the one who picks those technologies, so it goes without saying that he needs to know them in order to choose the ones which will fit.
What They Have in Common?
Analysis. Both are able to process and analyze data, the scientist being the expert.
Computer programming. Again, on two different levels. On this matter, the engineer takes the lead. Building a pipeline for example, which is the engineer’s main task, would be really hard if not impossible for the scientist.
The last one is pretty obvious : Big Data. The Data Engineer uses his programming skills to create Big Data pipelines. The Data Scientist uses his mathematics and statistics knowledge to create data products, imagine AI models and predict trends. The link between the two is that the Data Engineer’s pipelines are used to support the Data Scientist’s work.
The Need for Machine Learning Engineer
As O’Reilly’s article states, most of Data Scientists have a college degree, which is not an issue, but can become one as they are more inclined to research and theoretical work. Yet, companies need concrete work, release and value.
The complexity for Data engineers is that putting algorithms into production is simply not what they do. What they do is creating and managing pipelines that support Machine Learning algorithms, not optimizing those algorithms for their implementation.
Implementing Machine Learning algorithms not only requires academic logic, it demands a practical point of view. That is why a new type of profile is emerging, the Machine Learning Engineer. His skills are more and more appreciated, mostly in the US at the time, but it won’t be long until it becomes a worldwide trend.
The Role of the Machine Learning Engineer?
Machine Learning tends to share a similar background with Data Engineers. However, they usually decide to complete their skills range with mathematics or AI courses to be able to manage both the Data Science and its infrastructure.
This is why he appears as the missing link between Data Engineering and Data Science. His Data Science knowledge allows him to best optimize algorithms to implement them and his programming skills to actually do it.
He understands engineering methods and follows the agile approach. As he is the one who supervises the production launch, he also needs to master his environment to make sure it is safe.
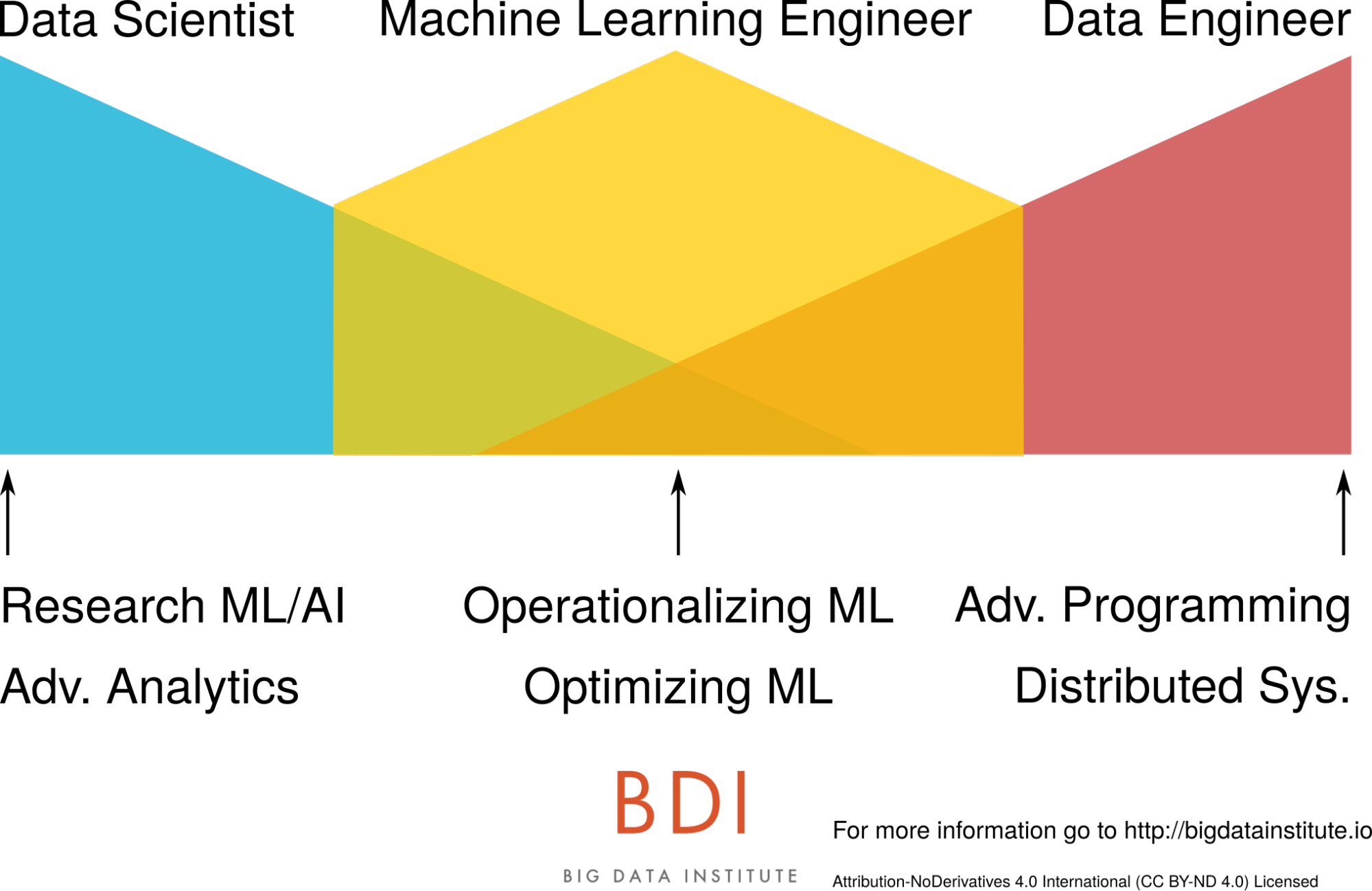
As it is the new on the block in the Data world, there is not a clear definition yet. You can even search for it on Wikipedia but you will come up empty. To put it simply, Machine Learning engineering gathers every process that allows AI algorithms to be implemented.
It may include rewriting one data scientist’s code from R or Python to Java or Scala, scaling this code (Python to PySpark, Python to Scala Spark) to make it more robust, or optimizing an AI algorithm to make sure it runs properly. It is all about the implementation step, from test to release.
A Machine Learning model needs more attention than your classic computer program. One day it can work perfectly fine and then crash the next day or give inconsistent results. The reason might be explained by a change in data if you added some to your datasets or it can come from an outside attack. In any case, the Machine Learning engineer needs to be able to prevent these failures or know how to handle them.
The DataOps Platform: the Ideal Machine Learning Engineering Environment
We have seen that ML engineering could be the bridge between Data engineering and Data Science, but having a ML engineer in your team does not automatically fix all your problems. And what if I tell you you may not need a ML engineer to do ML engineering, as long as you have the right tools ? Let’s show you how.
Saagie’s DataOps Platform eases Machine Learning algorithms implementation. Data Scientists and Data Engineers can easily work on common projects and share their experience as it is a collaborative environment. It allows you access a large amount of data, test your algorithms and their reliability.
Data Scientists :
- they have access to a larger quantity of data to test their algorithms
- they can have their algorithms on different notebooks (Jupyter, R Studio) and implement them without any compatibility concerns
Data Engineers :
- they can create pipelines and have Data Scientists’ algorithms running. they can create pipelines and get Data Scientists’ algorithms running. To do so, they use Docker to orchestrate every open-source technology composing data pipelines (Talend, Scala, Spark, Python, R, etc.).
- Optimizing algorithms and rewriting code for technology incompatibility reasons is thus unnecessary.
Last but not least, Saagie’s Data Fabric aims at embracing DevOps practices. In order to that, it obviously allows you to version, deploy, operate, monitor and iterate every step of the way on any of your Data Scientist or Data Engineer’s project.
This is how the Data Fabric manages to be the best way to industrialize Machine Learning and turn theoretical projects to actual business value.




