
“AI” and “quantum”. Here you go, two buzzwords for the price of one! More seriously, although I am aware that it is difficult to sum up two such big fields with a few articles, I wanted to try to expose, as faithfully as possible, the pros and cons of quantum computing applied to artificial intelligence, and more specifically to Machine Learning. The main underlying problem is the limitation of our computing capabilities to execute heavy algorithms. Indeed, although the power of our equipment has increased by 10 times in the last thirty years, we must keep in mind that we will always need more resources and that traditional computing won’t allow us to tackle some Big Data and IoT issues. Quantum mechanics might be one of the technical solutions to make computer science enter a new era in terms of security and algorithms execution speed.
Quantum AI: Ending Impotence!
Did you say “quantum”?
First, we could look into where the adjective “quantum” comes from. This term is so overused – like artificial intelligence – that we often forget its origin. We must go back to the 20’s and 30’s and consider the work of physicists like Planck, Born, Einstein – among others – to hear about quantization. To make it quick, the word “quantum” is roughly related to the atomic energy levels quantization – regarding the photoelectric effect – and the black-body radiation.
When the theory was developed, they understood that measurements related to molecules, atoms and particles can only take certain well-defined and undivided values. Such quantities are said to be “quantized” values. It’s a bit like planet orbits in our solar system: the planets move on well-defined ellipses but there is no planet between two consecutive orbits (except for asteroids). It may not seem like much, but if we imagine that the temperature on Earth was quantized, then it could only be -20°C, 5°C or +40°C… and never something else. What the heck!
Today, “quantum” refers to all subatomic sciences, meaning a world where objects are both particles and waves with probabilistic measurement.
Computing Power Retrospective
In the 70’s was released the first Intel microprocessor, containing 2300 transistors – basic processor component. Since then, the hardware performance, that is intrinsically related to the number of transistors within the processor, follows a trend – the Moore’s empirical law – which states that computers power doubles every 18 months. This is due to the fact that the transistors engraving fineness is always reduced by 50% over this period. The problem is that this “law” will not apply eternally. If IBM has recently passed the five-nanometer threshold for the size of a transistor, we might face a floor by 2020-2021 for we are inexorably closer to the atom size – around the “angstrom” order of magnitude, meaning one-tenth of a nanometer. Why is it an issue? Because, when handling such small components, some phenomena such as quantum tunneling (electrons “go through walls” instead of being stopped) appear, and transistors cannot work like usual transistors any longer.
Moreover, to increase processors computing power, even without considering these quantum effects, manufacturers did not rely solely on their miniaturization because they encountered some issues like circuit overheating. Thus, to ease parallel computing and limit the components temperature, they focused on new architectures that can be classified into two types of approaches.
Quantum AI: The Dice Have Been Cast!
Previously, in the Quantum AI column, we have seen that quantum computing would theoretically enable some complex machine learning algorithms to be executed in a “reasonable” time (less than several years…). But what is so different about quantum computers compared to today’s computers? The purpose of this article is not to go into theoretical details but to simply illustrate – as faithfully as possible – the fundamental differences between classical and quantum computers, especially with a quantum algorithm example.
Understanding the bit concept with the coin analogy
To understand why calculations are potentially much faster in a quantum computer, let’s recall the general functioning of conventional computers. They use bits to code information and are made of electronic circuits so that, when the current flows through the circuit, the bit is worth 1, otherwise the bit is worth 0. You can also consider the electrical voltage rather than the current, the approach will remain the same. To make basic calculations with logic gates (the famous conditions “AND”, “OR”, “NOT”, etc.), we typically use transistors acting as conditional switches: when the “base” electrode is supplied with voltage, they let the current flow between the other two electrodes.
For the rest of this article, we assume that a bit is materialized by a coin. When heads turn up, we can say it codes the value 1, else, when tails turn up, it codes the value 0. There are many other possible analogies (a bulb that lights, a door that opens, etc.) but in my opinion, the coin can illustrate some quantum phenomena – described hereafter – in a simpler way.
Technical digression
The coin analogy eases the mental representation of the rotations and projections of a pure quantum state on the Bloch sphere. In this model, the coin’s heads and tails are similar to the electron spins (spin up ↑ and spin down ↓).
Now, let’s suppose we can shrink the coin size to the atom scale. At that point, its performance could be compared to certain particles and could no longer be described by the usual macro-object mechanics. Here our quantum coin materializes a quantum bit (more commonly called “qubit”) and many phenomena now come into play. I will only expose here the most important of them for the purpose of this article.
The superposition phenomenon
From a quantum point of view, if an object has two possible states then any combination of these states is a valid state. This phenomenon is often illustrated by the paradox of the Shrödinger’s dead-and-alive cat.
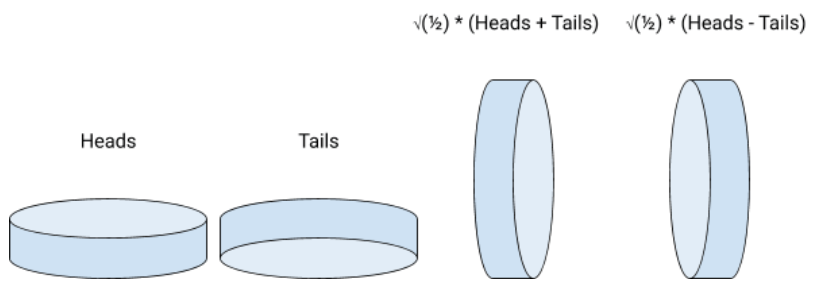
Let’s go back to the quantum coin: it has two possible states at rest (heads or tails up) so it could theoretically turn heads and tails up simultaneously. You can imagine the coin rests “on its edge” (in the real world, it is more complicated than that, but it does not matter seriously). Mathematically, resting on the edge is a linear combination of heads and tails with complex coefficients.
Technical digression
You may wonder why it involved some square roots of ½. Although they are not necessary to understand this example, these coefficients are interesting because they refer to probabilities when squared. The coefficient in front of heads (respectively tails) is the probability amplitude of “seeing” the coin landing on heads (respectively on tails) when it collapses on the side. An amplitude just has to be squared to be turned into a probability. An amplitude can also be negative or even complex (in this case, we take the squared norm to assess the probability). What does it mean to have negative (or even complex) amplitudes? It is simply a rotation around the vertical axis. For example, -1 (= exp (i.Pi)) is a 180-degree rotation.
Conclusion: qubits are complex combinations of 0 and 1. By analogy, a quantum coin can turn heads or tails up simultaneously, by resting on the edge.
The wave packet reduction (~ the wave function collapse)
In the macroscopic world, when a coin rests on its edge, the slightest disturbance (shaking, sneezing, etc.) makes it collapse, with generally 50/50 probabilities for heads and tails results. At the quantum scale, it is so sensitive that it is actually impossible to “see” the coin on the edge because the light itself makes it collapse immediately. To make the coin rest on its edge, you need to isolate it in a perfectly hermetic black box, without any interaction with you or the environment. Under these strict conditions, the coin will evolve spontaneously on its edge, even on “inclined” edges (which would defy the laws of gravity on our scale, but it doesn’t matter). And as soon as you open the box, the coin will collapse instantly, with 50/50 probabilities for heads and tails results. It could also be non-symmetrical probabilities depending on the inclination on which the coin was resting just before opening the box. This phenomenon is called wave packet reduction, also known as wave function collapse (I personally prefer the latter insofar as it describes more the very great instability of the system as well as the idea that the potential realities eventually collapse on the observed reality).
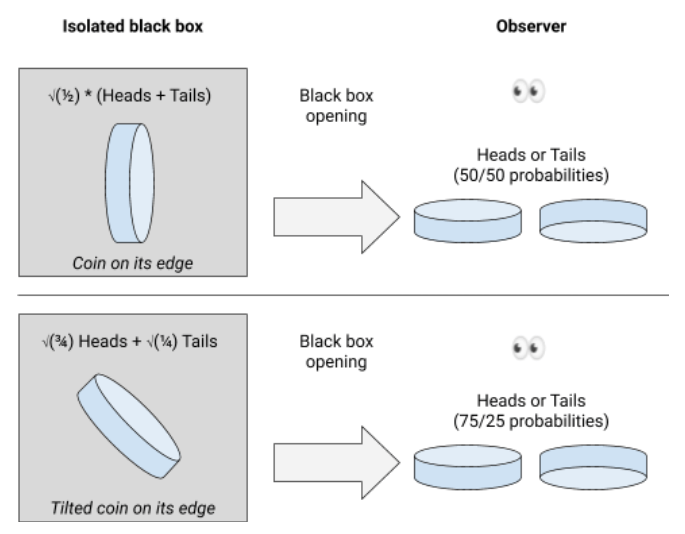
Conclusion: to make the quantum coin rest on its edge, you must neither look at it, nor interact with it. Even if it may rest on its edge theoretically, it is actually impossible to “see” it in such a state; you can only see it rested on heads or tails, after collapsing.
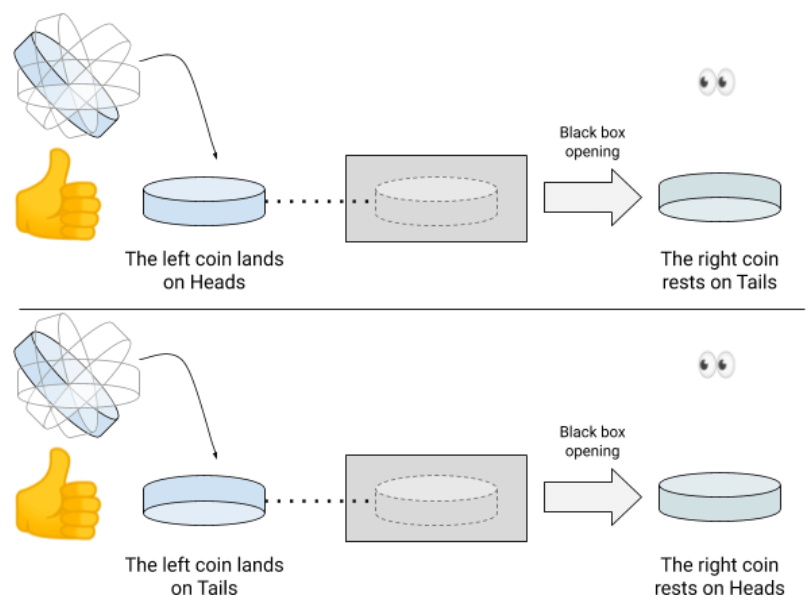
The entanglement phenomenon
Looking at some articles, the entanglement is a phenomenon that has been overjoyed and fed many delusions. It is related not to one but to two quantum coins (or more) and stipulates that, if your two coins has been created under very specific conditions, then their respective fates are linked. For instance, if you stick two coins on their edge (like Siamese twin coins), then they are part of a single and undividable system. We can say here that our coins are “entangled”.
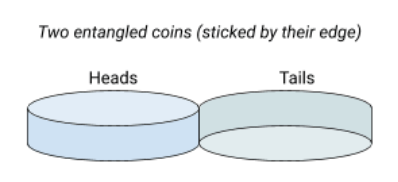
If one is resting on heads, the other is necessarily resting on tails. When you toss this set of two glued coins, the two initial coins necessarily land on opposite sides (one on heads, the other on tails). But the very strange thing is that their osmosis will carry on even if we tear them off. Imagine that we finally separate the two coins and that we enclose the right one in an isolated black box.
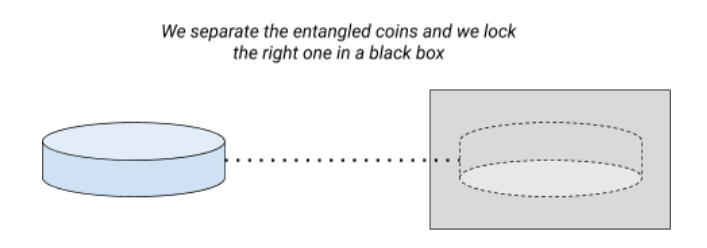
Let’s suppose now we flip the left one. In this case, if the left coin lands on heads, then, if you open the black box, the right coin will be resting on tails… and vice versa! And this will be obtained without anyone having touched the right coin!
The entanglement has fascinated many authors and scientists. As the “interaction” of the left coin on the right one is instantaneous, regardless of the distance separating them, some people reckoned it might be a way of teleporting information, or even time-traveling. No worries, this is rather inaccurate. No information can strictly teleport (meaning travel faster than light). Indeed, the action between the two coins may be immediate, we never know in advance the result of a coin flipping. So the result of the other coin (in the black box), cannot be transmitted in advance to someone else… for its result will change at the very last moment, when the coin flipping ends. An information is not a superposed system, only a actual measure.
Technical digression
Likewise, you unfortunately cannot use this phenomenon to reach the limits of causation. A 2012 study (E. Megidish, et al.) tells that two photons can be entangled even if they have never coexisted in time. This is made possible in this experiment by using four photons and by performing an entanglement swapping between two of them. The issue here is the interpretation of events temporality which, in my opinion, is more a matter of special relativity than quantum mechanics. Rather than time-related entanglement, it would be more correct, in my opinion, to talk about entanglement inheritance or exchange over time.
A first example of a quantum algorithm: the Deutsch-Jozsa algorithm
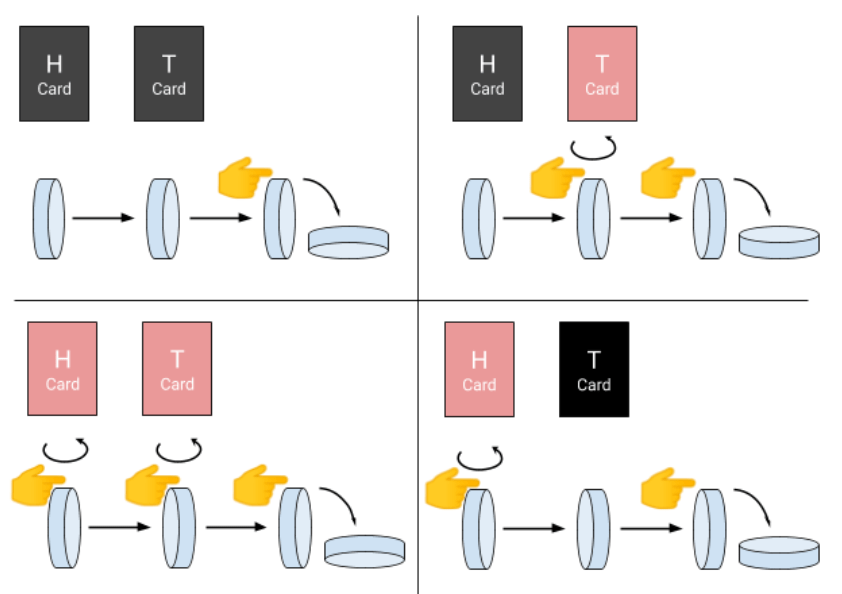
Now it’s time to concretely understand why some quantum calculations are more efficient than their classical counterparts. To do this, let’s play a riddle. You have a coin (an information bit). In front of you is a magician who has two face-down cards (from a traditional deck), marked “H” and “T” (referring to your coin Heads and Tails). The magician’s cards act on your coin depending on the side it is resting. The game goal is to find out whether the magician’s cards are the same color or not .
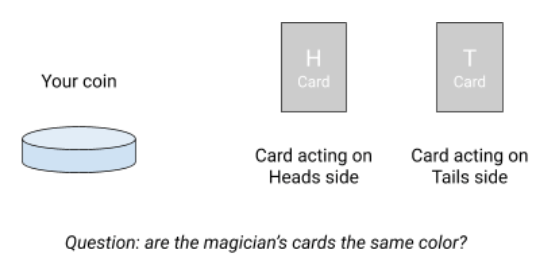
To perform it, you can present your coin to him with heads or tails up. If the coin turns heads up, the magician uses his H card as follows:
- If the H card is red, he flips your coin over to make it rest on tails
- If the H card is black, he does nothing, it leaves the coin heads up
Likewise, when you present the coin with tails up, the magician will then use his T card :
- If the T card is red, he flips your coin over to make it rest on heads
- If the T card is black, he does nothing, it leaves the coin tails up
The important thing is that, in any case, the magician must give your coin back after (on heads or tails), depending on the color of the corresponding card.
With a classic piece, solving the problem is fairly intuitive. You present the coin heads up; the magician acts on it with his H card: if he flips the coin over, then you know that the card is red… otherwise it is black. Then, you retry with the coin tails up. If the magician flips it over, then his F card is red, otherwise it is black. By presenting the coin twice in a row (once on heads, once on tails), you have the answer every time. You carried out two operations to achieve your goal (since you presented the coin twice to the magician).
But what happens if we now use a quantum coin? In this case, you are exceptionally allowed to present the coin… on its edge! Problem: the coin is supposed to collapse immediately on heads or tails. Remember, when we talked about the wave packet reduction, to make the coin rest on its edge, you need to left it quietly in a black box without any interaction at all. In fact, there is another phenomenon which expands the wave function collapse and allows a little flexibility: it is the quantum decoherence phenomenon. With it, it is actually possible to manipulate a quantum coin only for a very short period of time (generally around a few microseconds or milliseconds for the best quantum computers). After what, the coin is forced to collapse into a “classical state”: heads or tails up. As part of the problem, we will assume that the magician has powers that allow him to work long enough on the coin before it collapses on heads or tails.
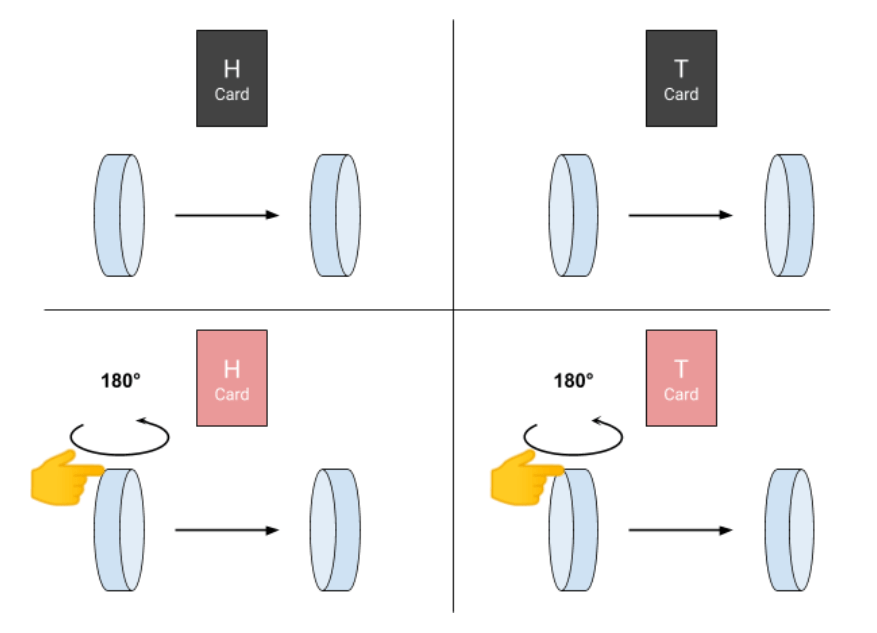
Let’s go back to our game. How will the magician use his cards if you present him a quantum coin on its edge? In fact, showing him a coin on its edge means you show him both sides simultaneously. In this case, the magician is forced to use his two cards in the same time: if the H (or T) card is red, he flips the coin over; otherwise he does nothing. But what does it mean flip the coin over when it is resting on its edge? Well, here the coin performs a 180-degree rotation around the vertical axis, like a spinning-top.
Then the magician must give the coin back to you. But don’t forget, if you look at the coin, it collapses instantly on heads or tails (with 50/50 probabilities). But you can ask the magician to push the coin on the right side before returning it .
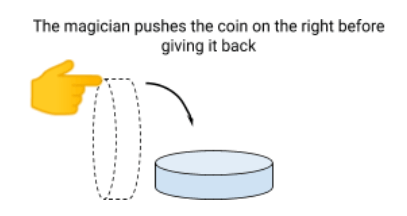
Well, here we are, with this trick, you can know, with a single coin presentation (a single measurement), whether the cards are the same color or not. Indeed, if the magician returns the coin head sup, then the cards have different colors, and if he returns it tails up, then the cards have the same color. Not convinced ? Let’s see the results in detail:
So we did one calculation instead of two (we presented the coin only once to the magician). What a performance! Okay, this basic example does not show a real improvement. But in the general version of this algorithm, you can play for example with 10 coins. In this case, the magician will have 1,024 cards which will act on all possible combinations of heads and tails. In this game, either all of the magician’s cards are the same color, or half is red and the other half is black. The goal is the same: to know the distribution of the magician’s deck. With classical coins, you will have to make between 2 and 513 attempts to find out if his deck of cards contains as much red as black. With quantum coins, you will only need one attempt because you will present your 10 coins on their edge… Here it seems to be more interesting in terms of computing acceleration!
This algorithm has no practical utility even if it roughly shows why a quantum coin can combine information (heads and tails) to reduce the number of operations and then save time. But for more sophisticated algorithms (eg quantum simulated annealing, Shor, Grover, Harrow-Hassidim-Lloyd algorithms), the use cases are very concrete: (de/en)cryption of sensitive data, search in an unsorted database, problems optimization, weather forecasts, molecular simulations for drug discovery, etc.
To sum up, quantum computing relies on the superposition of states and the entanglement of qubits to inherently perform parallel computing (without having to distribute processing on different machines). It also includes the concepts of decoherence time and wave function collapse which are necessary to go from a quantum operation to a real and useful measurement! All the complexity for our coders and physicists is therefore to identify the algorithms (and more specifically some specific operations, see the first article on quantum AI) whose formalism can be adapted to introduce the aforementioned quantum phenomena in order to accelerate the processing time. Finally, let’s remind that the benefits of quantum computation do not apply to all algorithms and that the performance gain is not always significant compared to computations on conventional computers. Today, we do not have true stable quantum computer which is actually marketed. But things should change quickly, when high-ROI quantum use cases increase within companies…
Quantum AI: The Rise of the AIs
Previously, in the Quantum AI column, we have seen that quantum computing would theoretically be able to significantly increase the execution speed of some Machine Learning algorithms. This is due to the phenomena at the core of such computers (like states superposition, qubits entanglement, superposed states decoherence, immediate wave function collapse) that enable parallel calculations by storing several (superposed) information within a single particle. By considerably speeding up algorithmic processing, quantum will make AI solve new problems. Some people go even further and say it could enable the design of an artificial brain as efficient as that of humans, especially able to integrate abstract concepts such as consciousness and feelings. The question that then arises is whether quantum AI would be more likely to become “strong AI” (artificial general intelligence)…
First of all, what is human intelligence?
Before looking at the complementarities between quantum and strong AIs, let’s start by delimiting the notion of human intelligence (HI). To give one definition, we could say that HI is a set of cognitive abilities that enable humans to learn, understand, communicate, think and act in a relevant, rational, logical or emotional way, depending on the situation.
This raises the question of what human intelligence is made up of. Several intelligence models exist, such as the Cattell – Horn – Carroll (CHC) theory. Although there is not yet a consensus for this question, the cognitive skills related to human intelligence could be classified into a few categories (somewhat re-aggregated here) such as:
- Logical and quantitative intelligence : ability for abstraction and formalization, rationality and reasoning;
- Literary and philosophical intelligence : language, reading, writing, structuring of thought and ideas;
- Social and emotional intelligence : introspection, ability to interact with others, ability to understand, perceive, feel and manifest emotions;
- Reactive and psychomotor intelligence : attention, coordination, parallel processing of multiple stimuli, mental endurance;
- Perceptive and artistic intelligence : visual, auditory, spatial, temporal, kinesthetic representations…;
- Memory intelligence: solicitation of short, medium or long term memories depending on the tasks.
Obviously, these declinations of intelligence have overlaps and can be reorganized differently. Moreover, some are subtly correlated, especially with memory. This is why theoretical models tend to distinguish so-called “ fluid ” intelligence from those called “ crystallized ” one in order to differentiate the mental processing that requires or not learning and the knowledge permanently present in memory. There is a cold analogy with computers which can use the information permanently stored on hard disks or that, faster to access, temporarily present in RAM cards, or even in cache.
But above all, scientists like Spearman (the father of the eponymous correlation coefficient) have long wanted to demonstrate the existence of a ”g-factor” that would consolidate all these abilities into a single form of general intelligence. To date, however, there is no real consensus on any model.
Then, how do you define artificial intelligence?
Artificial intelligence, on the other hands, is a set of sciences and techniques aimed at designing stand-alone machines with learning and reasoning abilities similar to those of humans. Be careful, this is an analogy of human intelligence rather than a vulgar technical cloning. Among the underlying sciences of AI are Machine learning – including deep learning, which is characteristic of the advent of AI since 2012 -, followed by natural language processing, neuroscience, computer robotics, etc.
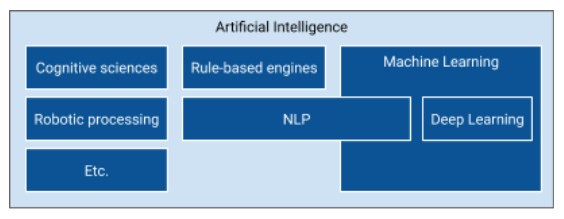
However, the term AI has very different definitions depending on the industry. On this subject, I invite you to read these articles which explain the difference between Machine Learning AI and AI in video games .
In the business world, machine learning (or even deep learning) algorithms have made it possible to create extremely efficient programs – in terms of precision and speed – for some processing. This is how three types of AI (we could rather call them algorithms here) emerged:
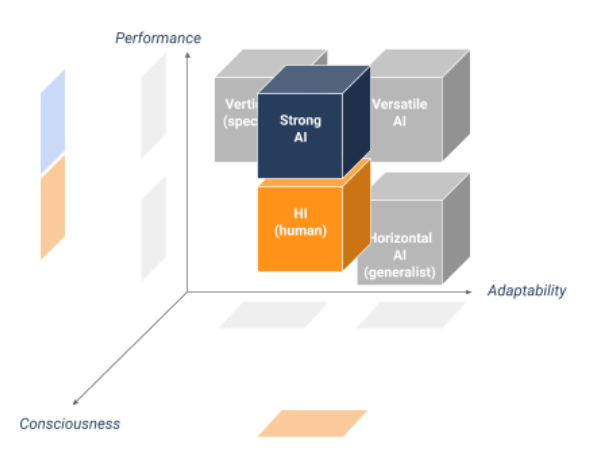
- Vertical or specialist: highly efficient in the execution of a task but not very adaptable to different tasks;
- Horizontal or generalist: reasonably efficient in the execution of a task but above all adaptable to different tasks (by transfer learning mechanisms for example);
- Versatile: superior to humans in the execution of several tasks and adaptable.
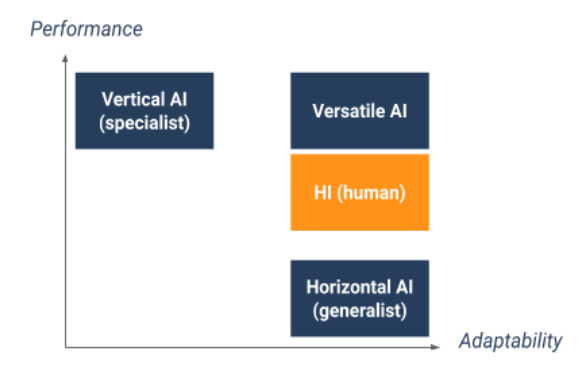
Today, it has been possible to implement high performance vertical AI (for example medical diagnosis on the basis of radiographs) and to some extent horizontal AI in the field of vision, language and games. But it is still very difficult to design good generalist AIs (especially versatile AIs). Just look at the AIs that drive autonomous vehicles: it’s hard to imagine these AIs doing stock market analyzes to drive corporate investments, while our human financial exec generally have no problem driving a car otherwise!
In addition, what is important to remember is that all of these AIs are said to be “weak” (including versatile AIs) because they may be superior to humans in performing specific tasks, but they lack inherent human abilities such as:
- self-awareness and introspection ability;
- the ability to make unlearned decisions or to experience unprogrammed emotions (assuming they are already programmable);
- motivation , curiosity and the search for meaning in life.
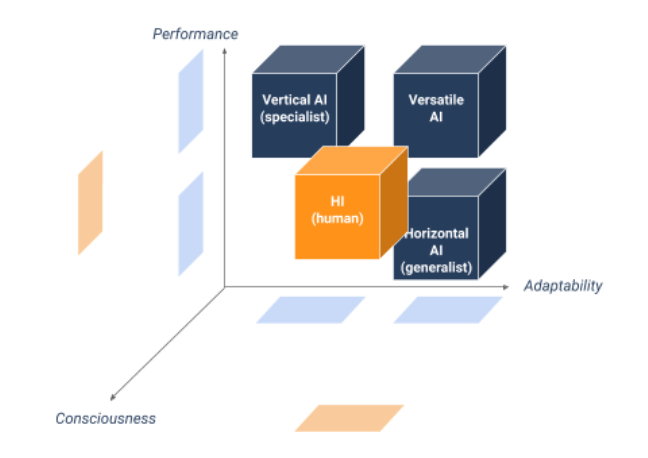
An AI who acquires such human abilities would be qualified as General Artificial Intelligence (AGI) or more simply “strong AI” or even “complete AI”.
A Definition of Strong AI
Thus, strong AI could be define as versatile AI with consciousness, capable of feeling, desiring, judging and deciding with complete autonomy. Arriving at such a level of sophistication, these strong AIs could for example be able to update the code that designed them to adapt to their environment or their new aspirations.
Many people fear this strong AI – starting with Elon Musk whose lyrical and alarmist outbursts have made the rounds of social networks several times. Why is that? Because if such an AI was trying to emancipate itself or “go into a tailspin”, like potentially any human in an extreme situation, then it could have disastrous consequences because of its execution capabilities disproportionately greater than those of the human brain and especially not restricted by the imperfection of our physical and limiting body. This day, when AI would definitively escape the control of humans, seems worthy of most novels or dystopian films such as Matrix, Terminator, Transcendence or I, Robot. But is this singularity only possible? It is difficult to give a date for the birth of strong AI since the obstacles that stand in the way of its design are multiple and perhaps irresolvable.
Strong AI vs. the materialist understanding of thought
First of all, it should be possible to determine whether human intelligence – as defined above -, emotions and sensory perceptions are reducible to a purely material functioning made up of electronic components. This problem is indeed far from obvious, even for the most agnostic among us. Who has never been fascinated by our body’s capacity to produce unsuspected reminiscences by the mere perception of a smell or music, often linked to a memory with a strong affect? Is it therefore possible to reconstruct such a psychic and sensory process with a set of transistors and computational and deterministic logic gates ?
Even without having all the evidence, it may be tempting to answer in the negative because neural biophysics is inherently different from computer electronics. But in order to answer in more detail, one would need a full understanding of the general mechanics of the brain. From this arises a new question: however surprising the latest scientific discoveries in neuroscience may be, does the human brain only have at its disposal all the elements of intelligence to understand with certainty its own functioning? Mathematicians will certainly see here a reference to Gödel’s incompleteness theorem.
More concretely – not being comfortable with the application of this theorem to the functioning of the mind -, I wonder here about the brain physical limitations which would prevent us from understanding the insights necessary for its own understanding. For example, if we try to imagine another color perceptible to the human eye (not present in the visible spectrum), another state of matter (different from solid, liquid, gas or plasma), or even the mental representation of a fourth spatial dimension, we quickly realize that we are not capable of it. This does not mean, however, that these objects inaccessible to our mind do not exist, but rather that our brain is not able to imagine perceptions that are foreign to its own physical structure. It is also the whole problem of qualia (subjective sensations triggered by the perception of something) and their links with consciousness. We naturally come to wonder if the brain is not the seat of phenomena other than neural electricity and the biochemistry of synapses…
The use of quantum AI to reach artificial consciousness
Even without taking these metaphysical considerations into account, it is clear that a Turing machine – the computational model on which traditional algorithms are based on -, although able to simulate many things, may never intrinsically be able to feel, perceive and reason like a human being. This is why, to bypass the barrier of determinism and the perception of reality, in order to achieve artificial consciousness, some would be tempted to call upon two recent areas of fundamental research .
- The first, which I will not detail here, is that of what we could call hybrid neural networks (artificial and biological!) which therefore combine electronic circuits and living cells, following the example of the Koniku society;
- The second is of course quantum computing, whose fundamental characteristic is to leverage the properties of particles to carry out intrinsically parallel operations whose results are no longer deterministic but probabilistic.
Why this choice? Because some scientists such as Penrose and Hameroff assumed that quantum phenomena (superposition and entanglement) would sit in our brain through the spins (intrinsic magnetization) of proteins present in neural microtubules which would behave like the qubits of a quantum computer.
Technical digression
It may indeed seem natural to use Dirac’s formalism (at the basis of algebra modeling for quantum mechanics) and qubits to describe the evolution of these brain microsystems. For example, there is a similar willingness in the field of atomistics to describe molecular orbitals with precision. It comes down to using quantum computing to simulate quantum physics. It’s a bit like using traditional computing to simulate processor electronics.
Nevertheless, the reception given to this theory was very mixed, for the simple reason that, apart from photons (constituents of light), there is almost no physical system at room temperature capable of making quantum phenomena last long enough (we speak of decoherence time, generally well below a billionth of a millisecond for natural molecular aggregates) for them to have any impact on neuronal functioning.
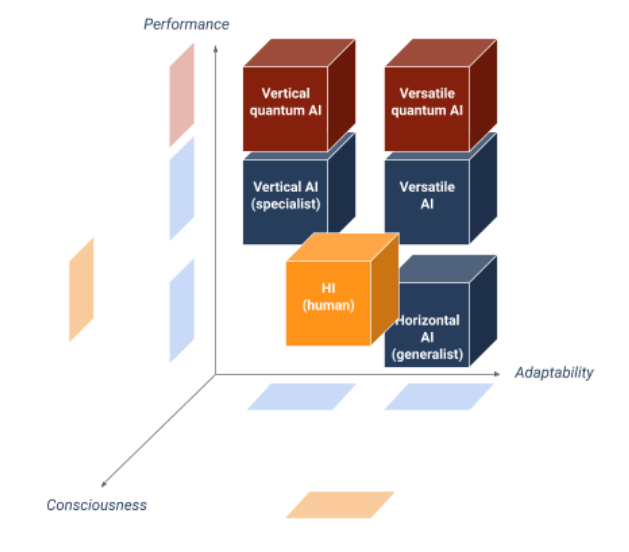
So even if quantum computing allowed vertical AI to solve insoluble problems today, it would not seem capable of adding new properties that are attributable only to the biological brain whose quantum camake AI progress along the performance axis but not along the adaptability axis nor, a priori, to the consciousness axis. Quantum or not, the perspectives of artificial thinking always seem far away.
Technical digression
However, I still have a favorable reservation on the fact that quantum may one day make it possible to model mechanisms such as the notion of subjective reality or consciousness. Indeed, certain phenomena like quantum counterfactuality (cf. the Mach-Zehnder interferometer or the Elitzur-Vaidman’s bomb tester ) could never have been understood without quantum mechanics.
To be brief, it describes the fact that a particle “tests” all possible paths (without actually taking them, we speak here about its associated probability wave) before actually “choosing” one with a given probability. In other words, a phenomenon which could take place on one of the paths of a particle, whether it occurs or not, always betrays its potential occurrence by probabilistically interfering with the result of other measurements on other possible paths. It is as if all the possible futures of an action interfere with each other and only the future with the best resulting probabilities emerges from the present when the wave functions collapse.
This surprising phenomenon testifies to the fact that we have not found better than quantum to accurately describe certain microscopic experiments that challenge intuition, and even if the reality is quite different, quantum appears as the best tool to describe what we observe. I refer here to the Copenhagen school of thought. I tell myself that it is perhaps the same thing with the consciousness that only a theory as abstract as quantum mechanics could describe. In any case, if there really was such an opportunity to model subtle physical processes with a quantum-like formalism (which is above all a tool), then the birth of strong AI would be put back in play. But today, quantum mechanics does not seem to help us on the path of consciousness whose quantum nature is itself uncertain.
And if strong AI existed theoretically, would it be possible to create it for real?
But let’s admit that it is possible, that we can create a strong AI. Is it empirically possible to have the talents and power required to build this AI before the end of mankind? The question does indeed arise. Leaving aside the conceptual complexity of such a program/algorithm, we can look at two important metrics: time and energy.
Regarding time, it is above all a question of when we will finally have a more robust knowledge of the consciousness mechanisms to actually design an artificial mind, supposing that humanity does not have any vital issues to solve in priority before then. As for energy, IBM gives some orders of magnitude of the supercomputers consumption: it would take no less than 12 gigawatts to power a single computer with as many artificial neurons as the human brain (about 80 billion). This is roughly equivalent to the power delivered by some fifteen French nuclear reactors (a quarter of the total number of French nuclear power plants!). From this point of view there, the human being, spending only 20 watts, is incredibly more economical … And do not expect quantum to optimize energy. To preserve the coherence of the qubits superposition/entanglement (required to speed up the algorithmic processing time), the temperature of the computers must be lowered to near absolute zero (-273.15°C). The energy required is obviously colossal .
So, if we assume that the creation of an artificial consciousness will require as much or even more energy than these supercomputers – quantum or not -, it seems unthinkable that we devote so many resources to the development of such AI, however strong it may be. And even if we did it, we would have created an artificial conscious brain similar to a cold data center, but in no way similar to a humanoid walking down the street (otherwise, I’ll let you imagine the size of the battery powering the brain of such a cyborg). Even if current research is focused on making neural networks more efficient, we will probably face an industrial dead end when it comes to making AI strong and mobile, assuming that this has an anthropological interest.
In summary, due to our ignorance of the consciousness mechanisms, quantum AI will probably not be more “strong AI” than conventional AI. The question of the usefulness of a strong AI may arise, but it we likely put more efforts to make vertical AI lighter and less energy-consuming, especially when the latter is partially quantum.
Quantum AI: The Key Role of DataOps
In this new chapter, I want to share my point of view on the theoretical implementation of a quantum production device in a company. This can for example be a decision-making process (BI) or machine learning based on an infrastructure of conventional and quantum machines. The interest is of course to take advantage of quantum processors to solve today insoluble problems, whatever the servers used. Nevertheless, it is clear that such a device can not be done simply without using a DataOps approach. Decryption.
Towards an inevitable hybridization of infrastructures
The initial problem is that when real quantum computers come into being, it is very likely that they will be in the hands of big American players such as IBM, Google or Microsoft, for the simple reason that this new equipment will be expensive … So whatever your urbanization policy, you will have to deal with the cloud to experiment with calculations on quantum virtual machines. In the absence of a “full cloud” policy, it will therefore be highly desirable to be able to rely on hybrid infrastructures (cloud and on-premise) – or multi-clouds at the pinch – to limit the risk of dependence on a provider.
Today, there are already similar issues of resource allocation. For example, we may want to provision a cloud experimentation environment (for testing cognitive services, for example) and maintain an on-premise production environment. However, while exploiting HPC servers in a cluster is now easier thanks to the container orchestrators, ofwhich Kubernetes is the most emblematic representative, the parallel exploitation of several disjoint and heterogeneous clusters proves to be extremely dangerous. The complexity is indeed to be able to use different environments without losing the thread of your analytical project, namely the location of data, the continuity of treatment pipelines, the centralization of logs …
We touch here a well-known problem in addition to Atlantic. The agility of the infrastructures and the orchestration of the treatments on heterogeneous computer grids are some of the main issues that theaddresses DataOps in the long term.
In the rest of this article, I will call “supercluster” a logical set of heterogeneous and hybrid clusters. For example, this might be the bundling of an on-premise environment running a commercial distribution of Hadoop or Kubernetes, coupled to AKS cluster in Azure and to an EKS cluster in AWS or GKE in Google Cloud.
What is DataOps?
Before continuing on the management of superclusters, it is necessary to define the term DataOps, which is quite rare in Europe and more particularly in France. DataOps is an organizational and technological scheme inspired by DevOps. It involves bringing agility, automation and control between the various stakeholders of a data project, namely the ISD (IS operators, developers, architects), the Data center (data product owner, data scientists, engineers, stewards) and trades.
The aim is toindustrialize the analytical processes by making the most of the diversity of the vast technological ecosystem of big data and the multiplicity of skills of each actor. In summary, I believe there are 9 functional pillars within the scope of a DataOps approach:
These principles apply to each stage of the data life cycle (also known as the data value chain or data pipeline).
The approach DataOps is vast and complex, but it only allows to create a sufficient level of abstraction to orchestrate the analytical treatment in a supercluster, as summarized in the following diagram we will go in the rest of this article:
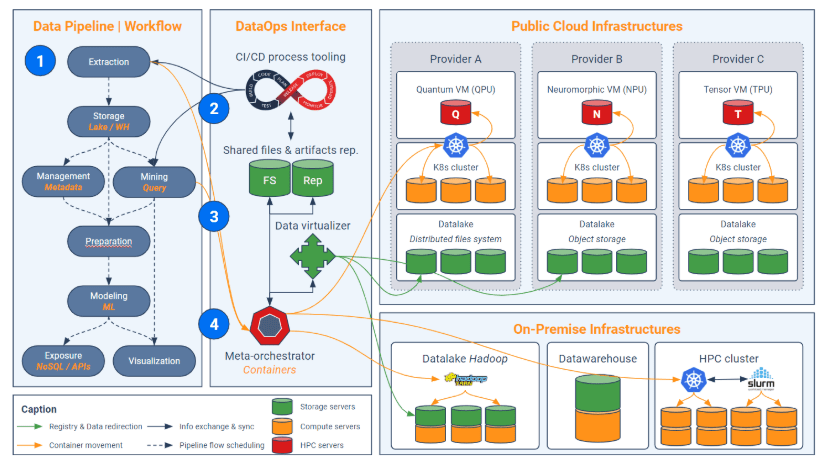
Step 1 – Building a pipeline by abstraction levels
The DataOps interface (vertical block at the center) has four technology components: CI / CD tooling, shared files and artifacts, data virtualizer, and meta-orchestrator. The first stage of implementation of this interface consists in cutting the analytical process (pipeline) into different independent links roughly corresponding to the life cycle of the data: extraction, cleaning, modeling …
This approach has a double interest:
- First, it allows to take advantage of different programming languages (a fortiori with different frameworks) according to the link considered (we do not use the same tools in ETL as in machine learning for example);
- Secondly, this division makes it possible tooptimize the distribution of loads (which we will see in step 4).
But this division does not stop there: even within a specific activity (a link), it is recommended to split its code according to the different levels of functional abstraction. This amounts to imagining a multi-stage pipeline: the first pipeline consists of business bricks (eg “segment customers”) and each of these bricks uses a sub-pipeline that connects steps a little more basic (ex: “Detect missing values”, “execute a K-Means”, etc.) and so on. Below is an example of pipeline and sub-pipelines. Note that the higher the pipeline, the more abstract it is; each dark cell uses a lower abstraction sub-pipeline.
This division into levels of abstraction can also take place directly in the codes (via functions and classes) rather than in the pipeline. But it is important to keep a certain breakdown in the pipeline directly because it will isolate and orchestrate fragments of algorithms that may or may not benefit from quantum acceleration (see step 4).
Indeed, we must remember that only certain steps of an algorithm can benefit from the contributions of quantum computing (see first article of quantum IA). This is usually the inversion of matrices, search for global extremum, modular calculations (the basis of cryptography), etc. Beyond knowing if quantum can or can not speed up some treatments, this breakdown of codes makes it possible to reduce the cloud bill by limiting the use of quantum VMs to a minimum (because their hourly cost will probably cringe).
Digression – An example of a classical algorithm partially converted to quantum
Within the framework of the DBN (Deep Belief Network), it is possible to isolate the unsupervised pre-training stages of RBM stacks and the “fine-tuning” phase (adjustment end). Indeed, some researchers have been interested in a quantum acceleration of the sampling steps in the case of a convolutive network of deep belief (yes, the name is quite barbaric). The goal is to compare the performance of quantum sampling compared to classical models such as the CD (Contrastive Divergence) algorithm. This study shows that the quantum can boost the pre-workout phase, but not the discrimination phase! Hence the importance of properly decomposing the steps of the algorithms, to avoid unnecessarily soliciting a quantum machine on classical calculations that are long and non-transposable quantially speaking.
Moreover, beyond tariff optimization, splitting codes into abstraction levels is also and above all an essential methodology in writing scripts. An interesting article on this subject shows that the management of abstraction (consisting of distinguishing “what” from “how”) is a good development practice that encompasses many others.
Step 2 – Integration with repository and CI/CD tools
Now that the codes (and other artifacts) of the general pipeline are carefully split by abstraction levels, they should be centralized in the repository. This approach is usually accompanied by standardization of codes. The goal is to be able to reuse them easily in different contexts.
The generic and repeatable character of a code can be obtained by means of a double “variablisation”. The first is an intuitive generalization of the code by creating variables relating to data processing (via classes, methods, functions …). The second is the creation of environment variables, that is to say that the setting of the code is done dynamically according to the environment (in the infrastructure sense) in which it runs. For example, the variable “password” can have multiple values, each of which is linked to a specific cluster.
As for the automation of testing and deployment of these scripts, the DataOps solution can either integrate CI / CD functionality, or connect to existing tools such as Maven, Gradle, SBT, Jenkins / JenkinsX, etc. These come to recover the centralized binaries in the repository to integrate them into the processing pipeline. The codes then become “jobs” that will run in dedicated clusters. The pipeline must finally be able to log the versions of the jobs that compose it to keep track of all previous deliveries and possibly proceed with “rollbacks”.
Step 3 – Data virtualization
The penultimate step is storage abstraction. Indeed, since the purpose is to exploit scattered infrastructures – which already requires a huge programming effort to make the codes generic – it is better not to have to take into account the exact location of the data or the need to replicate them with each treatment.
This is typically the role of a data virtualizer that allows an implicit connection to intrinsically different storage sources and facilitates memory management to avoid futile data replication. In addition, data virtualization solutions provide an undeniable competitive advantage in the implementation of cross-infrastructure data governance. By this I mean the implementation of a transverse and unique repository with metadata management and authorizations.
The data virtualizer intervenes at the time of reading the data (to perform the processing) and also at the end of the chain to write the intermediate or final results in a local or remote database (or cluster).
Step 4 – Advanced load balancing
Now that all the data is made available (via the virtualizer) and the codes are standardized and broken down into coherent functional units, the idea is to orchestrate the associated processing within the supercluster. In other words, we try to execute the algorithmic containers in the appropriate clusters.
Each cluster is governed by a solution that acts as a scheduler / dispatcher of tasks and as a container and physical resource manager (eg Kubernetes). Today, all cloud providers offer Kubernetes-as-a-service offerings in their virtual clusters.
The DataOps solution needs to go a step further and play the role of “meta-orchestrator”. The latter aims to distribute jobs among the orchestrators (Kubernetes) underlying each cluster. The meta-orchestrator is therefore an additional layer of abstraction to Kubernetes. When a quantum acceleration is needed, the meta-orchestrator is responsible for redirecting the algorithmic container to one of the Kubernetes orchestrating the quantum VMs. Thus, the meta-orchestrator ensures that only the relevant jobs are routed to the quantum VMs while the others can run on-premise or on cloud clusters composed of traditional VMs.
In summary, the rise of quantum machines in the cloud will encourage companies to optimize the way they orchestrate their analytic and hybrid environments. The DataOps interface (which can be a unified software solution), in addition to automating the deployment of complex pipelines, oversees the routing of certain (quantum-formally compatible) codes to Kubernetes clusters with quantum VMs. Companies would be able to control their costs (especially the cloud bill) by requesting the right clusters at the right time, especially when it comes to using HPC servers (GPU, TPU, NPU, QPU, etc.). ).

Axel Augey is a graduate of Ecole Centrale de Lyon and ESSEC. He joined Saagie in 2017 as Product Marketing Manager and since 2020 has been Data Manager at papernest, a French start-up specialized in simplifying administrative and contractual procedures related to housing.




