La récente démocratisation de la science des données et la...
Quels sont les avantages de recourir à des outils d’apprentissage automatique ?
La récente démocratisation de la science des données et la...

Exploration de GitHub Copilot avec Saagie: révolution du codage intelligent
Dans le monde de l’informatique, l’innovation ne connaît pas de...

Initiation au ML : Construire un Pipeline avec BigQuery et Saagie – Partie 1
Dans cette série d’article, nous verrons comment faire du Machine...

Découvrez comment la Data Science transforme les entreprises modernes !...
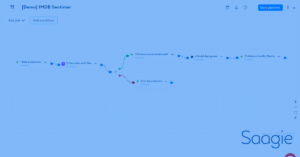
L’orchestration de traitements hybrides est devenue essentielle dans le paysage...

Comment utiliser MLflow pour monitorer un projet de machine learning
Les projets de machine learning se heurtent souvent à plusieurs...

Optimisation de la gestion de la documentation pour le projet SaagieAPI
Dans un monde où l’information est essentielle, la documentation d’un...

L’analyse de données est devenue un élément clé dans la...

Les chiffres parlent d’eux-mêmes : selon une étude de Forrester Consulting, plus...

Comment déployer un modèle de machine learning avec Python ?
Comment travailler avec des modèles de machine learning ? Quelles sont...

Pour accompagner nos nouveaux utilisateurs dans leurs premiers pas sur...
Chaque année, le nombre d’articles vantant dbt et ses capacités...

5 erreurs qui empêchent les projets du Data Lab de passer en production
Toujours pour vous accompagner dans la réussite de votre projet...

Avec l’émergence des approches DevOps en informatique, notamment avec le...

Mise en place et coût d’un Data Warehouse : un mode de stockage des données hébergé sur le cloud
Votre entreprise fait face à un double constat : une...

Stockage de données sur AWS-entreprise : pourquoi Amazon Web Services est si populaire ?
Avec la quantité de données produite quotidiennement par les applications...

Pourquoi utiliser une API pour un projet data ? Quels avantages ?
Vous êtes chef d’entreprise et vous caressez le rêve de...
Avec le monde numérique en plein développement, de plus en...

À quoi sert un data hub dans la mise en place d’un projet data?
La gestion efficace des données est devenue un enjeu crucial...

Le data cleaning, comment obtenir un traitement de qualité des données
Le nettoyage des données d’une entreprise (data cleaning) n’est peut-être...
Comment analyser et modéliser des données Big Data avec Power Pivot ?
En Data Science ou en Big Data, on est amené...

Loi normale Python ou loi de Gauss, comment modélisez-vous vos données?
En Data Science et en probabilités, on est amené à...
Comment intégrer un ingénieur data science au sein de son entreprise ?
Ces dernières années, les entreprises ont compris l’importance d’analyser les...

Le CI/CD en DataOps : le développement continu et la mise en place de pipeline
Les données sont de plus en plus présentes dans les...

La mise en place de conteneurs dans le développement des...

L’analyse de données et le Big Data sont des outils...

Top 5 langages de programmation les plus utilisés en Big Data
Vous pouvez facilement vous retrouver perdu(e) dans le système des...

De nouvelles technologies de stockage sont apparues au cours des...

Comment évaluer, choisir et gérer vos modèles de machine learning ?
Le machine learning (ML) est un domaine de la science...

Data science et développement informatique sont deux domaines très proches...

Alors que les entreprises font de plus en plus appel...
Dash : l’outil idéal pour développer une web App avec Python
Lorsque vous analysez des données, il est courant de devoir...

Le domaine de l’analyse des données est devenu un eldorado...

La conteneurisation (containerisation en anglais) consiste à regrouper dans une...

Les données sont la matière première de tout projet data....

Après des mois de travail passés sur un projet data...

Machine learning : comment évaluer vos modèles ? Analyses et métriques
Vous utilisez ou souhaitez utiliser le machine learning, mais vous...

La programmation fonctionnelle : un exemple concret pour comprendre comment ça marche
La programmation fonctionnelle est un paradigme de programmation peu répandu,...

10 librairies Python qui vous simplifieront la vie pour l’analyse de données
On peut, sans trop prendre de risque, affirmer que le...

Vous commencez un nouveau projet data et vous réfléchissez aux...

Tests unitaires, tests d’intégration… comment tester votre code ?
Vous développez, mais vous testez peu votre code ? Pourquoi et...

Les tests A/B, une étape essentielle pour valider vos modèles de machine learning
Le machine learning (ou ML) est un domaine complexe requérant méthode...

« You can’t manage what you can’t measure. » – Peter Drucker Une citation...

Projet data : bien lister les sources de données disponibles
Les données sont le carburant de tout projet data, elles...

DataOps rime avec pipeline : de quoi s’agit-il et comment les mettre en place ?
89 % des entreprises auraient des difficultés à gérer leurs données...

Vous connaissez un peu le SQL, mais avez entendu parler...

DataOps : pourquoi communiquer ses résultats est-il une étape cruciale ?
Vous utilisez le DataOps dans votre entreprise, mais communiquez-vous suffisamment...

La data est un domaine qui se plaît à paraître...


Comprendre le DataOps : définition, avantages, mise en place
Vous avez entendu parler du DataOps, mais vous voulez en...

La phase pilote, étape de validation essentielle en DataOps avant le passage en production
Entre la naissance d’une idée et la mise en production...

DataOps : comment gérer différents environnements au sein du même projet ?
Quel data scientist ne s’est jamais mordu les doigts lorsqu’un...

Votre hiérarchie est sceptique ? 5 bonnes raisons de passer au DataOps
Vous connaissez le DataOps de nom, mais vous voulez en...

Deep learning… vous en avez sans doute entendu parler. Si...
Quelles priorités le DataOps met-il en avant pour mener un projet efficacement ?
La data est à la mode ces dernières années et...

Les 3 piliers du DataOps : agilité, orchestration, gestion des données
Le DataOps s’est imposé ces dernières années comme un sujet...

DataOps, DevOps, MLOps… qu’est-ce que c’est, quelles sont les différences ?
DataOps, DevOps, MLOPs… Vous avez sûrement déjà croisé l’un de...

Cette semaine, nous sommes ravis d’échanger avec Augustin Marty, CEO...

Comment sécuriser l’accès de son projet data : les protocoles Posix, Sentry et Kerberos
Lors des phases de développement, c’est une partie souvent mise...

Cette semaine, Julien Fricou, Data Engineer chez Saagie, a pu...

Qu’est-ce que Spark et comment l’utiliser pour la programmation fonctionnelle ?
Spark est l’une des technologies web les plus en vue...

Bash est un interprète de commandes aussi connu en anglais...

Apache Zeppelin est un web notebook. Le concept de notebook...

Pourquoi et comment mettre en place une politique de CI/CD ?
Avec l’arrivée des nouvelles méthodes de travail comme l’Agile, le...

L’idée de cet article n’est pas de vous rappeler l’importance...

Dans le secteur de la data science, il existe des...

Si vous êtes développeur, vous savez très bien que depuis...

Grafana est un outil open source avec une licence Apache...

Qu’est-ce que Jupyter et comment faire plus avec vos notebooks ?
Si vous êtes un data scientist, il est fort probable...

De nos jours, la quantité de données que les entreprises...

Docker et la conteneurisation est l’un des sujets en tendance...

Vous êtes-vous déjà demandé comment votre téléphone pouvait comprendre ce...

Lean, Agile, Scrum… Voici des termes que vous avez sûrement...

Les algorithmes de machine learning sont de plus en plus complexes,...

Comment Choisir ses Outils de Management pour la Data Science ?
Si vous êtes impliqué(e) dans un projet data, vous devez...

Qu’est-ce que le Surapprentissage et Comment le Résoudre en Machine Learning ?
Cet article vous explique le phénomène du surapprentissage (overfitting) en data...

L’organisation d’une équipe de Data Science est très complexe. En plus du...

Comment Ordonnancer Facilement des Jobs avec Apache Airflow ?
Cet article s’adresse aussi bien aux débutants qu’aux vétérans d’Airflow...

Le dilemme Robustesse vs. Adaptabilité est un problème bien connu...
Déployer un projet data, du cadrage au déploiement à grande...

Comment amener les pratiques DevOps à vos projets Big Data ?
Suite et fin de notre chronique consacrée à la réussite...

Comment Mettre la Vision Métier au Cœur de son Projet Data ?
Suite de notre chronique consacrée à la réussite de vos projets Big...

Comment se passe un POC (Proof of Concept) dans un Projet Data ?
Deuxième article de notre livre blanc : “Du Data Lab à...


La visualisation de données : c’est quoi et quels sont les meilleurs outils ?
Au programme de ce nouvel article, nous vous expliquons ce...

Le volume de données que nous générons chaque année ne...
